AI 摘要
文章围绕开源自部署网络流量分析面板 Neko Master 的诞生与演进展开。作者作为 Homelab 用户,希望获得比 Clash 面板和 Grafana+Loki 更直观、美观的“流量感知”视角,于是在春节期间通过 Kimi K2.5 等模型进行 Vibe Coding,一小时内完成接入 OpenClash 的 MVP,并在四小时内上线首版,迅速获得 GitHub 与 Docker 的关注。后续项目从玩具版走向复杂架构,重点解决家庭 NAS/软路由环境下的稳定性与性能问题,包括:通过内存缓冲队列、批量写入、先聚合再写和写入限流,将 SQLite 导致的日写入量从 200GB 降到 1.6GB;在多 Agent、多网关场景下引入 ClickHouse,通过批量写入窗口、按时间分区与排序键建模、预聚合高频指标等手段,提升查询稳定性与响应时间。文章系统复盘了 Kimi、Claude Opus、CodeX、Gemini 在原型搭建、性能调优、架构重构中的分工,并强调“给 AI 视觉锚点”来提升 UI 审美效果。作者总结,Vibe Coding 极大压缩了从 0 到 1 的时间,但从 1 到 100 仍依赖人类对性能、架构、审美和用户需求的判断。
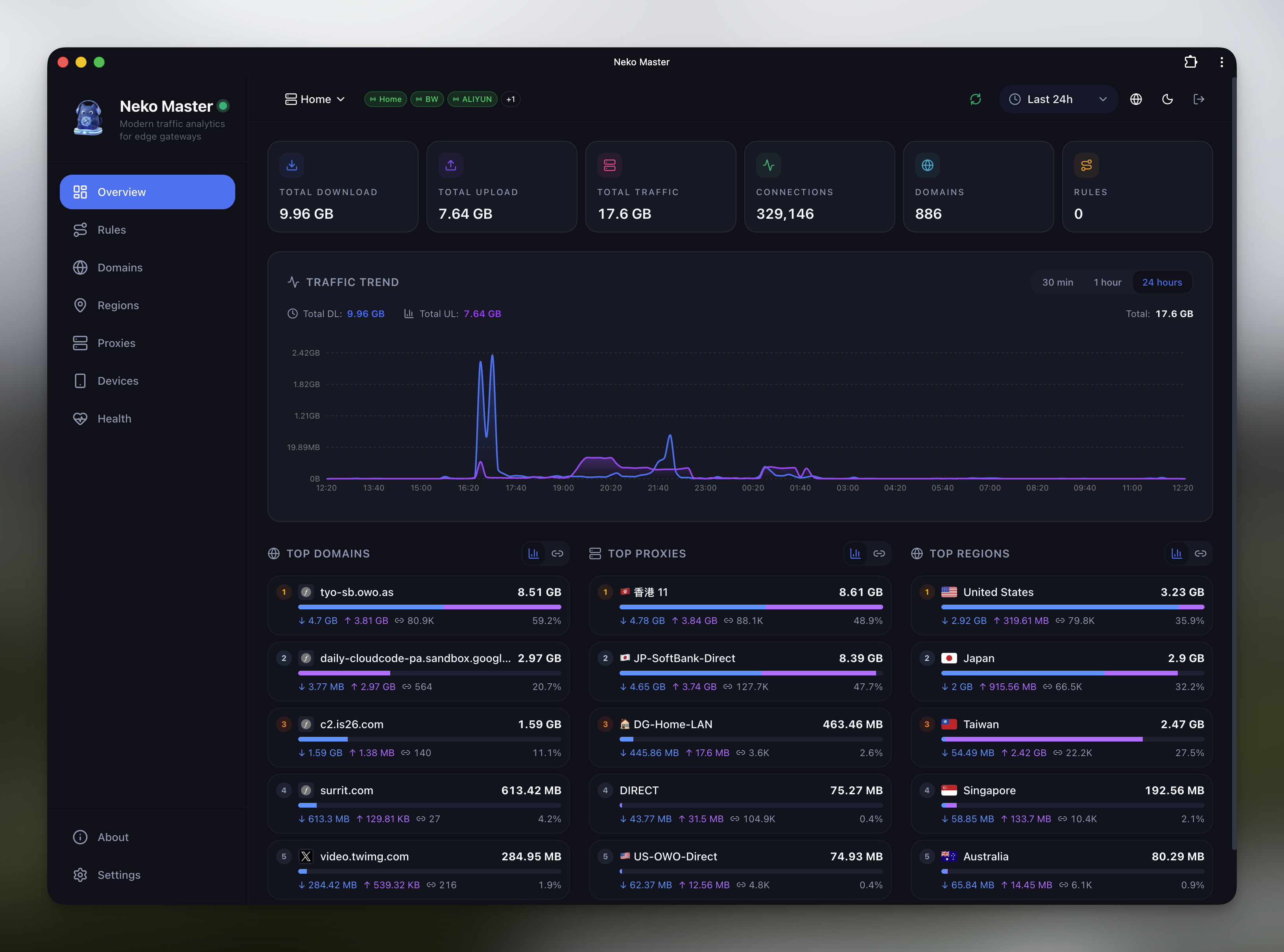
春节期间,我花了四个小时,从零开始 Vibe Coding 了一个网络流量分析面板 Neko Master,当天就上线了第一版。项目上线一周,GitHub 收获了 1000+ Star,Docker Pull 破了 10K。
项目最初叫 Clash Master,用了一周后改名为 Neko Master。原因很简单:不想跟 Clash 这个名字绑定太死,后来支持了 Surge v5+,未来也可能接入更多网关类型。
Neko Master 是什么?
一个开源、自部署的网络流量分析面板。
- 多维流量统计(域名 / 节点 / 规则 / 地区等)
- 趋势分析
- 多后端支持(OpenClash / Mihomo / Surge)
- Docker 一键部署
- 移动端适配 + PWA
如果你家里也在用 OpenClash / Mihomo / Surge,欢迎体验。MIT 开源,欢迎 Star 和提 Issue。
- GitHub: github.com/foru17/neko-master
- 在线演示: neko-master.is26.com(
密码: neko2026)
从最初的「玩具」到现在拥有复杂架构的项目,这篇文章算是对整个开发过程的一个回顾和总结,分享一些 Vibe Coding 的实战体感。 如果只看第一版,它其实不复杂;真正的复杂度,是上线后被真实流量和用户场景一点点逼出来的。
为什么会有这个项目
我是一个 Homelab 用户,家里跑了一堆服务,分流策略比较复杂,日常开发也会频繁切换 IP。
其实早在 2024 年初,我就折腾过一次流量监控方案:用 Grafana 和 Loki 配合 Clash Premium 的 Tracing API,弄了一个监控面板。当时发了条推,说「能看看自己的线路流量什么的,其实也没啥用」。
luolei @luoleiorg · 2024年1月7日
用 Grafana 和 Loki,配合 Clash Premium 的 Tracing API,弄了一个 Clash 监控面板,能看看自己的线路流量什么的,其实也没啥用。 https://t.co/YhrjvpspIe https://t.co/3huqYdmg4r
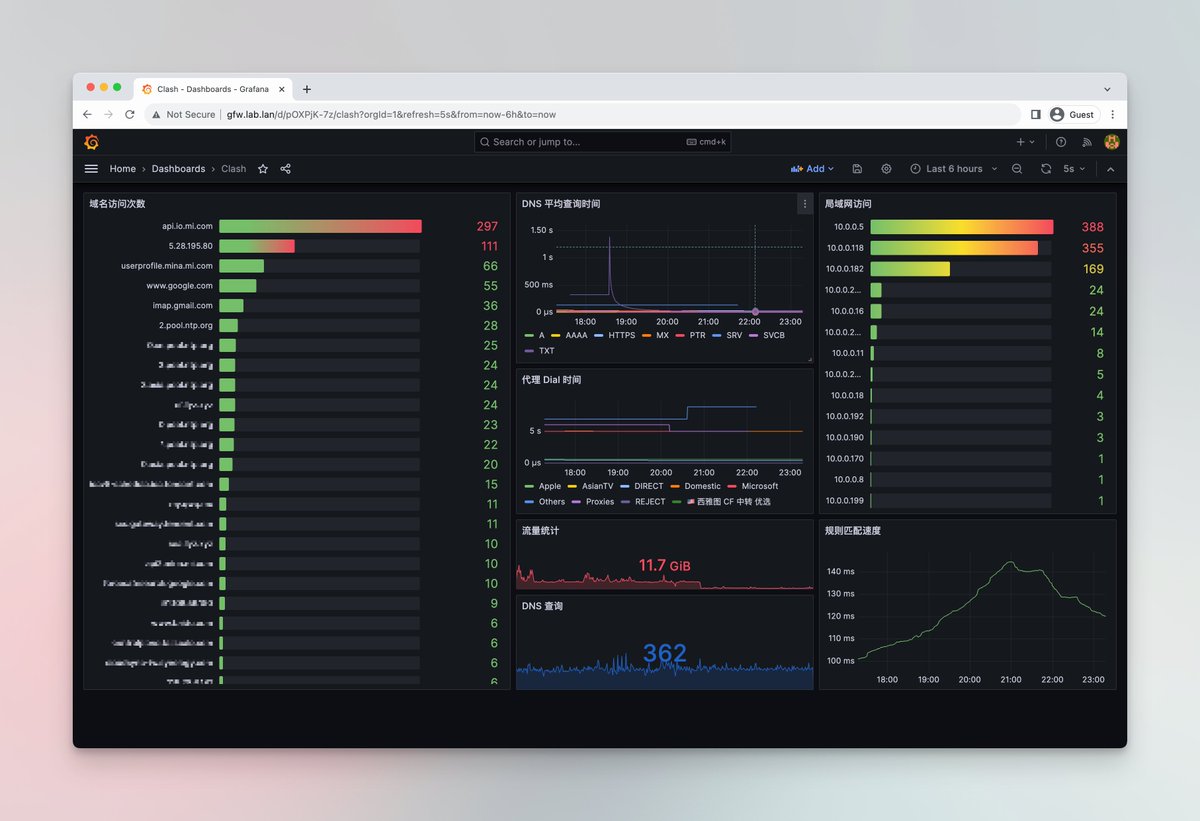
但用了一段时间后,发现 Grafana 这套东西虽然功能强大,但对于家庭用户来说门槛还是太高了。配置繁琐,界面也不够直观,更关键的是长得不好看。原生的 Clash 面板更多是「运行状态」展示,但我一直缺少一个更直观的视角去看:
流量到底在干什么?
- 哪些域名在吃带宽?
- 哪个节点负载更高?
- 深夜学习 AI 时到底哪个网站最耗流量?
- 当前的规则策略是否合理?
市面上除了 UniFi 之外,其他统计工具的界面确实有些一言难尽。与其在不同工具之间拼凑数据,不如自己做一个更好看、更好用的「流量感知」的面板。
一小时打造 MVP
2 月 5 日下午,我打开 Kimi Code,使用最新的 K2.5 模型,开始 Vibe Coding。
没有画原型图,没有写技术方案,就是在脑子里先搭了个大概框架,然后直接跟 AI 对话。一小时不到,MVP 就跑起来了:部署在内网,监听 OpenClash 流量,能看到域名统计、节点流量,数据还能持久化。
luolei @luoleiorg · 2026年2月5日
我又来吹 Kimi K2.5 了。刚花一小时 Vibe 了一个 Clash 流量分析工具,完成度极高。部署在内网,监听 OpenClash 流量,实现域名、节点流量统计及 IP 归属地查询,数据持久化。我家的网络分流策略比较复杂,一直想找个工具感知流量状况,毕竟市面上除了 UniFi,其他统计工具的界面确实有些一言难尽。 https://t.co/RoLJbkaP53
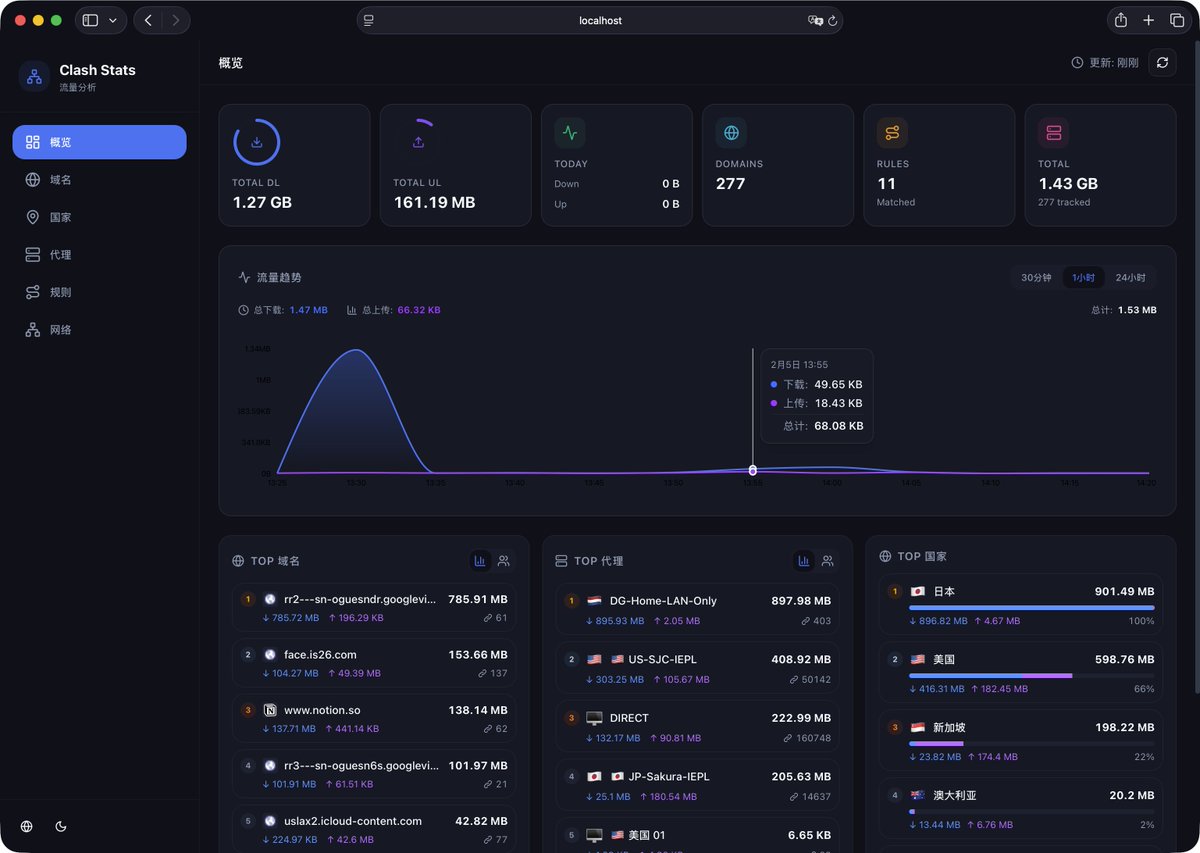
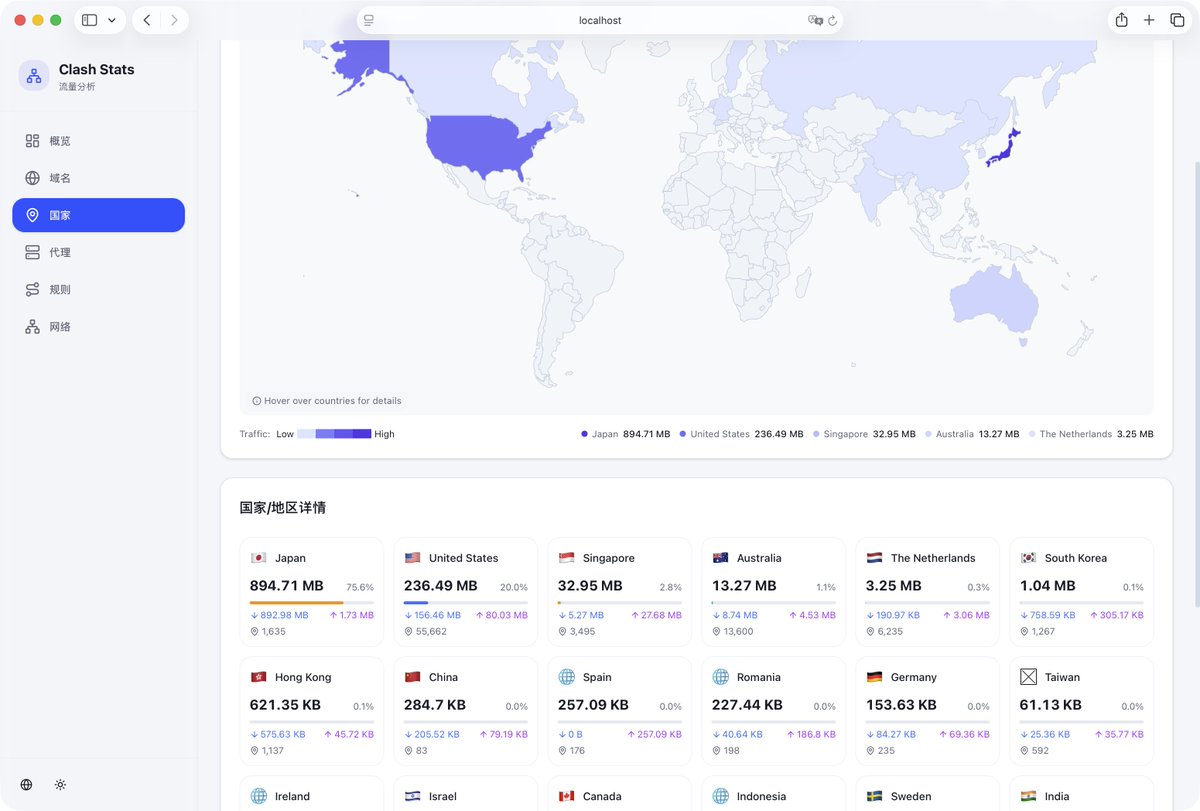
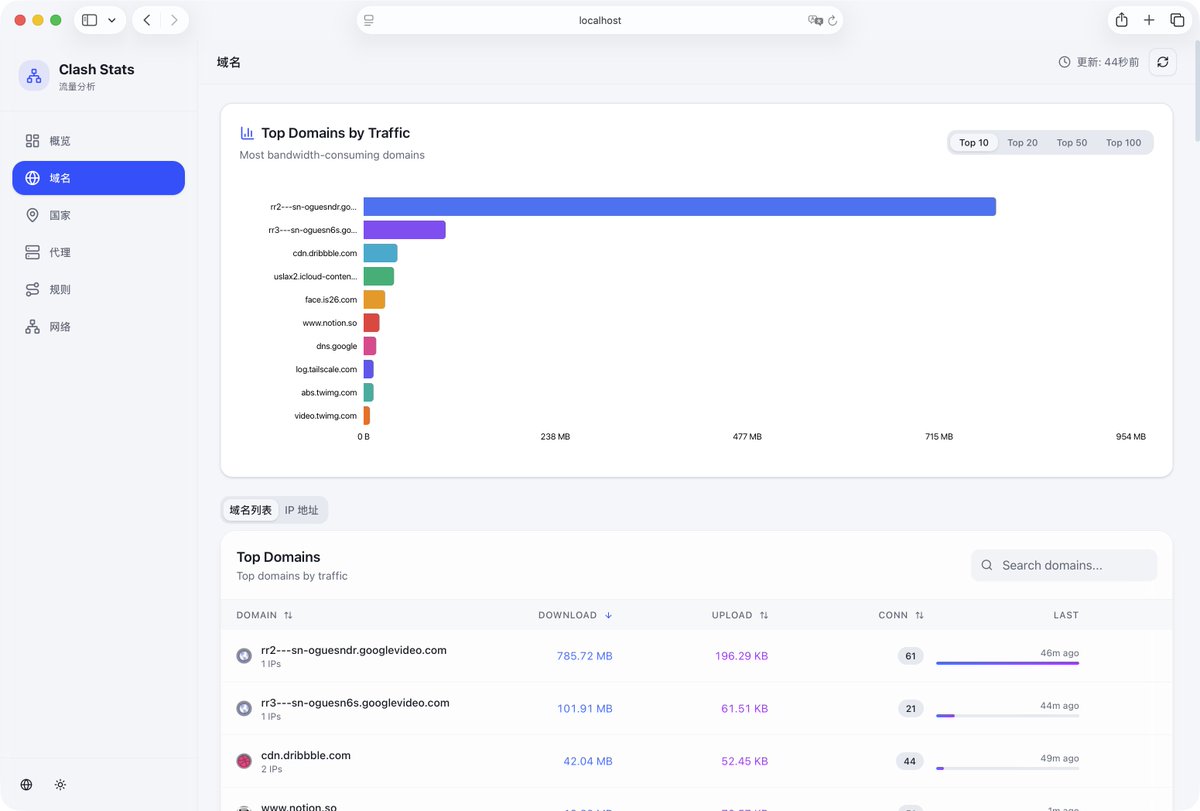
当天晚上又花了三个小时打磨了一下,凌晨四点半,第一版 Clash Master 就上线了。
这个项目发布不到 24 小时,就收获了 GitHub 400+ Star,Docker Hub 1000+ 次拉取。这就是 AI 时代的开发速度。
让 AI 审美在线
这次开发 Neko Master,听到最多的评价就是「好看」,甚至有人在 V2EX 专门发帖,问 Logo 是怎么做出来的。问与答:《想问一下这种 logo 是怎么做的》

Neko Master 整体的 UI 属于现代 SaaS 风格,我自己也挺满意的。后面我还专门发了一条推,聊「如何让 AI 审美在线」。
luolei @luoleiorg · 2026年2月6日
昨晚随手 Vibe 的一个项目 Clash Master,不到 24 小时,收获 GitHub 400+ Star,Docker Hub 1000+ 次拉取。
图 1 是昨晚 Vibe Coding 的第一版,图 2 是现在的完全体。 前者 AI 味浓浓,后者审美基本达到 2026 年现代 App 的水准了。这就是 AI 时代的开发速度。⚡️
分享一个 Vibe Coding https://t.co/9E1GM32EDZ
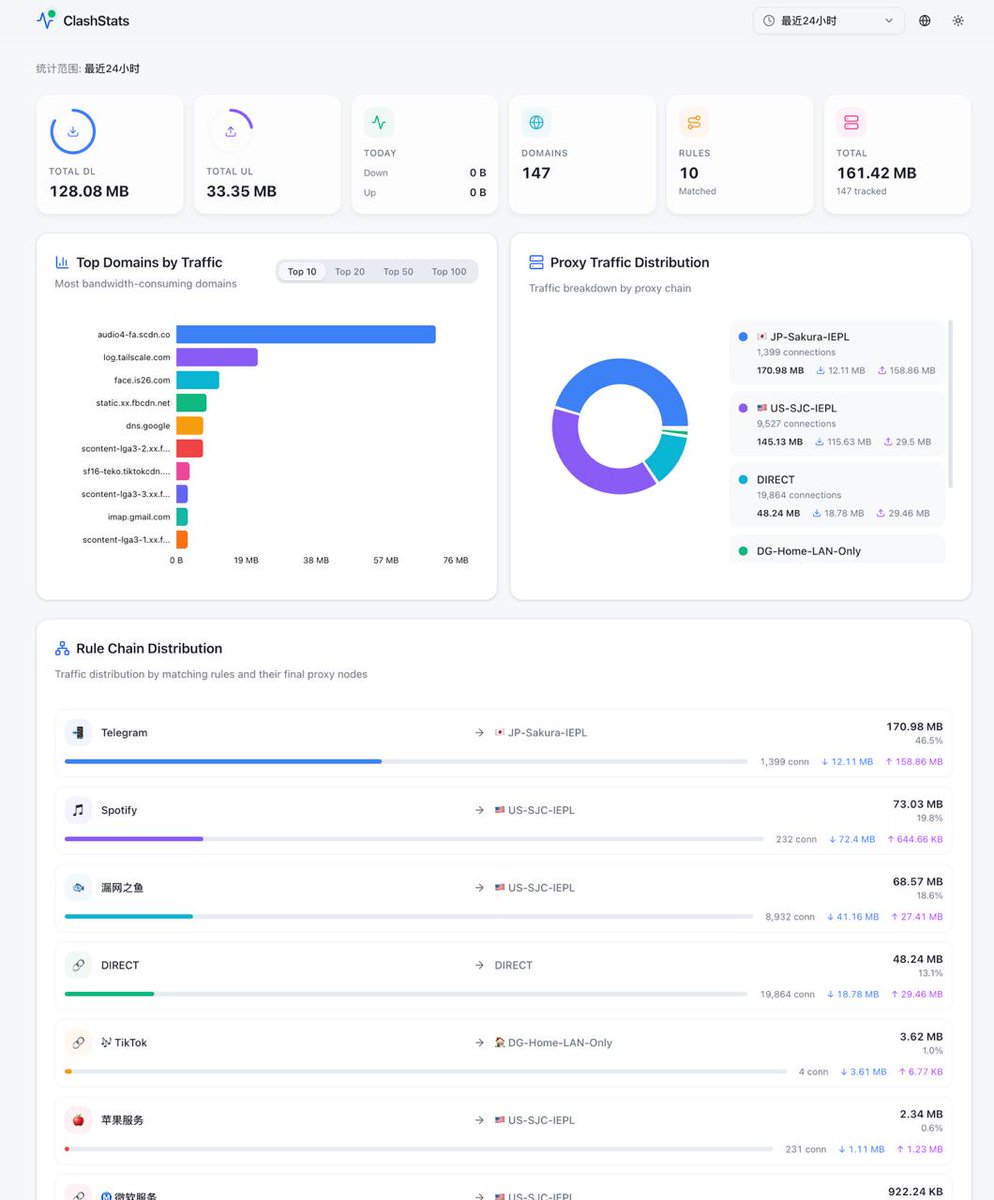
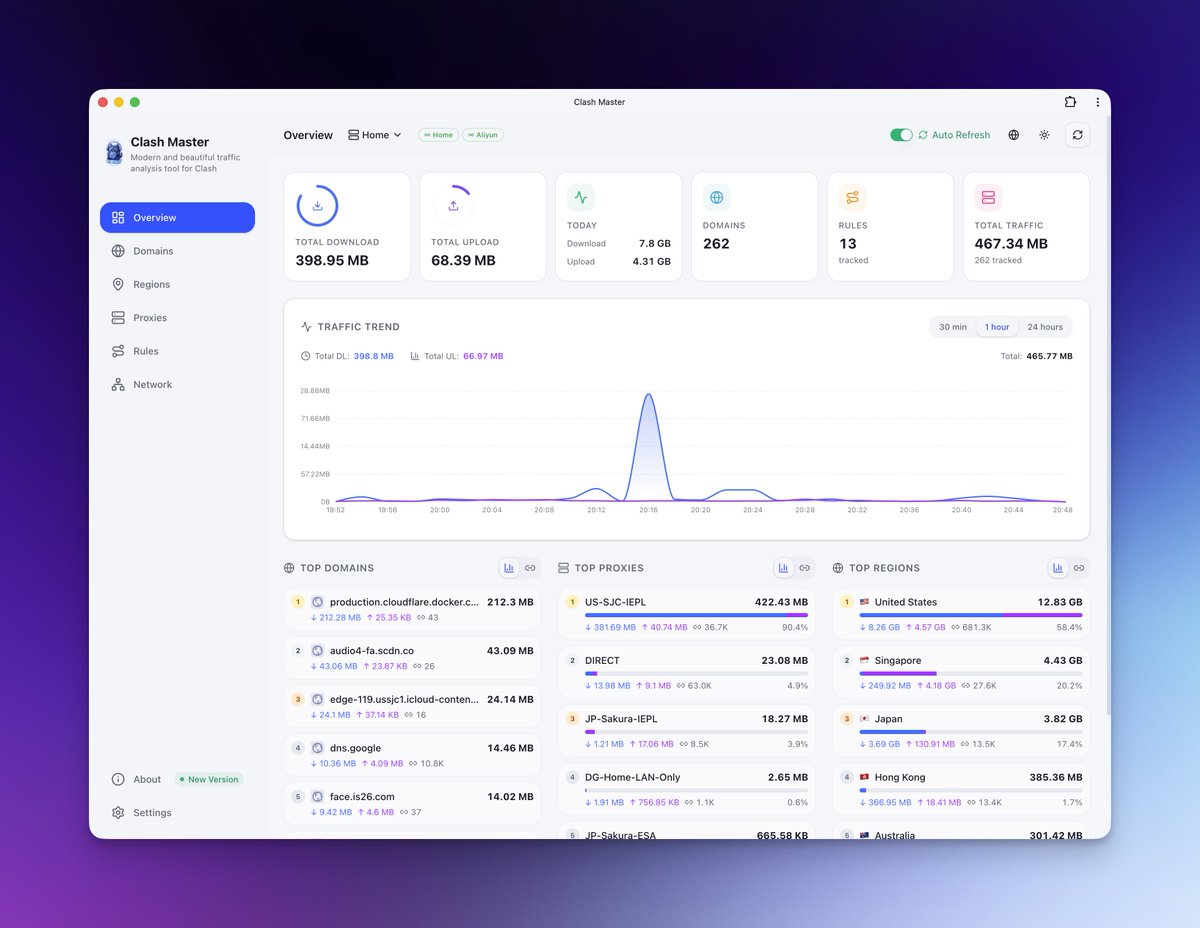
图一是当晚 Vibe 出来的第一版,图二是几天后的完全体。前者 AI 味浓浓,后者审美基本达到了 2026 年现代 App 的水准。
很多人吐槽 AI 生成的界面「千篇一律」,说实话第一版确实如此。分享一个我实践下来觉得很有效的技巧:
不要只用文字描述「给我写个好看的面板」。要给视觉锚点。
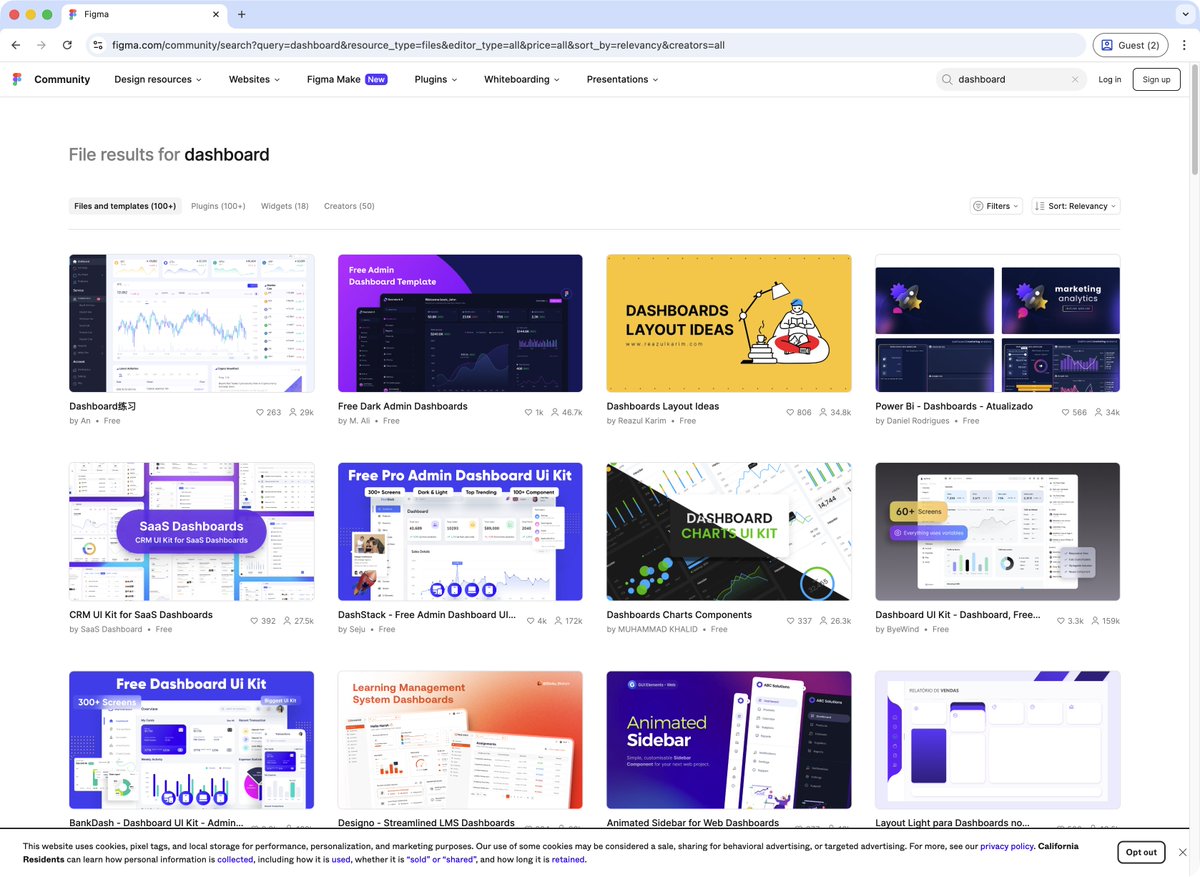
具体做法:去 Dribbble / Figma Community 搜「Dashboard」,挑一张看着舒服的截图直接喂给 AI,告诉它「复刻这个设计感」。配色、卡片阴影、数据可视化风格,都可以用截图来锚定。
有了参考系,AI 的审美直接从「程序员风」进化到「SaaS 级」。
一个我越来越确信的感受是:在 AI 时代,代码的门槛在下降,但审美判断依然是决定成品质量的关键因素。 AI 可以帮你写代码、做布局、调样式,但「好不好看」这件事,最终还是得靠人来判断。
AI 工具复盘
这个项目开发过程中,我把市面上主流的几个 AI 编码工具都用了个遍。直接说结论:
| 工具 | 角色 | 体感 |
|---|---|---|
| Kimi K2.5 | 早期主力 | 量大管饱,中文理解好,MVP 阶段 100% 主力,甚至没见过任何限额提示 |
| Claude Code (Opus 4.6) | 硬骨头 | 贵公子。一个复杂任务下去 4 小时限额 15 分钟直接见底,但遇到架构和性能深水区,只有它能啃 |
| CodeX (GPT 5.2/5.3) | 日常输出 | 5 小时循环用量非常扎实,开发过程基本碰不到小时限制的瓶颈,但周限量两天就用完了 |
| Gemini 3 Pro | 辅助 | 主要用来 Review 和写 Commit Message,质量偶尔掉线 |
一个真实体感:国产模型在初始化阶段已经足够高效,Kimi K2.5 是 Clash Master 诞生阶段的绝对主力。但当项目复杂度提升,面对数据库性能调优、架构重构这些深水区问题时,还是得靠 Claude Opus 4.6 和 CodeX 5.3 交叉 Debug。
一个额外体感是:模型不是越贵越好,关键看任务匹配。原型、重构、排障用的模型可以完全不一样。
Vibe Coding 的节奏:快速迭代与用户反馈
上线之后的两周,基本就是一个循环:发版 → 收反馈 → 修 Bug → 加功能 → 发版。 从 v1.0.2 到 v1.3.2,迭代了大约 20 个版本。
这个节奏下,AI 的角色不再是「帮我从零写一个功能」,而是变成了「帮我快速响应用户反馈」。 V2EX 上有人说磁盘 I/O 炸了,我把日志贴给 Claude,十五分钟定位到是 SQLite 单条写入没做批处理,连夜修了三个版本,I/O 从一天 200GB 降到了 1.6GB。Docker 镜像太大被吐槽,让 AI 帮我做多阶段构建,从 800MB 瘦到 300MB。
这个阶段的一个核心体感是:Vibe Coding 不只是「让 AI 写代码」,更是「让 AI 帮你加速整个反馈循环」。 用户提了个需求,你不需要花半天去查文档、写方案,直接跟 AI 说清楚上下文,几分钟就能拿到一个可用的 patch。这种响应速度,在开源项目的早期阶段是非常关键的——用户看到你迭代快,信任感就上来了。
技术细节
改名的同时做了一次比较大的架构升级,包括 Agent 分布式部署模式、ClickHouse 大规模分析后端等。 真正难的不是把面板做出来,而是让它在 NAS / 软路由这类资源受限环境里稳定跑起来。这里补几个最能体现复杂度的深水区问题。
1) 硬盘 I/O:从“硬盘灯常亮”到可持续运行
这个坑是最痛的一次。早期版本把每条流量记录都直接单条写入 SQLite,功能是对的,但在真实家庭网络里会触发严重写放大。用户反馈磁盘写入量吓人,我一看容器和主机监控,日写入量确实离谱。
核心问题不是 SQLite 本身,而是写入策略太“在线”了:高频事件 + 单条落盘 + 没有缓冲,I/O 自然爆炸。在 demo 阶段不明显,一上真实流量就暴露。后面连续几个版本做了三件事:
- 内存缓冲队列 + 批量落盘(30 秒 flush,达到阈值提前 flush)
- 先聚合再写入(热点统计先在内存合并,减少无意义小写入)
- 写入限流和背压(高峰期优先保系统稳定,不让磁盘被打穿)
结果非常直观:
v1.0.2 -> v1.0.7 -> v1.0.9
200GB -> 20GB -> 1.6GB / day
这次之后我基本确定了一件事:AI 能快速把“能跑”的代码给出来,但 I/O 模型、缓存策略、背压机制这些基本功,必须由人把关。
2) ClickHouse:不是“接上就快”,而是“建模正确才快”
单网关场景 SQLite 足够,但多 Agent、多网关以后,域名/IP 维度的数据量会迅速上涨,查询复杂度也跟着上来。尤其是 TopN、时间趋势、规则命中这类查询叠在一起时,读写压力会互相放大。ClickHouse 引入后,第一版也踩了典型坑:小批次高频写入导致 parts 激增,merge 压力上来后,查询延迟会抖动。
后面重点做了几层优化:
- 写入侧:统一批量写入窗口,避免 tiny insert 把 MergeTree 打碎
- 存储侧:按时间分区 + 按常用筛选维度排序,热点列做低基数字典化和压缩
- 查询侧:把仪表盘高频指标(Top 域名、节点趋势、规则命中)前置到预聚合层,接口优先读聚合结果
- 迁移侧:保留 SQLite + ClickHouse 双写,先灰度再切换,避免一次性迁移风险
这套优化做完后,收益不只是“更快”,而是“更稳”:高峰时段的查询波动明显下降,面板体验从偶发卡顿变成可预期的稳定响应。这也是项目从“能跑”走向“可维护”的分水岭。
3) AI 在深水区的正确使用姿势
深水区里,AI 最有效的用法不是“一次性生成”,而是进入工程化闭环:日志与指标 -> 假设 -> patch -> 压测/对比 -> 继续迭代。 我在这个项目里基本就是让 Kimi 快速铺功能,用 Claude/CodeX 啃性能和架构细节,然后自己做最终取舍。AI 把迭代速度拉高了,但稳定性边界和技术债优先级,还是得人来拍板。
如果你对完整架构感兴趣,GitHub 仓库里有完整的架构文档和部署说明。
写在最后
Vibe Coding 确实改变了我的开发方式,过去需要一两周的原型,现在几小时就能跑起来。但有一个东西 AI 替代不了:从「能跑」到「好用」的那段距离。
200GB 的写入 bug 是 AI 写的,但发现问题、定位瓶颈、设计缓存策略是人做的。界面从「AI 味」到「SaaS 级」,靠的不是更好的 prompt,而是你自己对美的判断。Agent 模式的架构设计,来自对真实部署场景的理解,不是 AI 能凭空想出来的。
Vibe Coding 降低了「从 0 到 1」的门槛,但「从 1 到 100」的路,依然需要经验、审美和对用户需求的理解。