order by 与 limit 的优化
作者从自己团队“提倡简单SQL”的实践出发,探讨了一个高频但易被忽视的优化点。在避免JOIN、子查询的风格下,`ORDER BY`与`LIMIT`成了支撑业务查询的主力,其性能直接影响用户体验。 这篇文章没有空谈理论,而是聚焦于这类简单查询可能带来的性能陷阱。作者强调,在面对这些看似基础的语句时,真正的技巧往往藏在细节里。他批判了仅凭模糊经验就下结论的浮躁心态,转而提倡一种更严谨的态度:对每一条涉及排序和分页的SQL,都需要仔细分析其执行计划与底层逻辑,学习并借鉴已被验证过的优化方法。 文章的价值在于将关注点从“炫技”式的复杂查询,拉回到大量简单查询的实战优化上,提醒开发者对基础保持敬畏。这种基于真实业务场景的思考,对于追求数据库稳定与效率的团队来说,是很有参考意义的务实分享。
the ways to kill mysql application performance
这篇讲的是MySQL应用中那些看似不起眼、却在悄悄拖垮性能的操作习惯。 作者没有罗列常规的“如何优化”,而是从反面切入,系统梳理了那些会直接“杀死”性能的行为模式。比如不恰当的索引设计如何引发全表扫描、配置参数设置不当如何导致资源浪费,或者是一些看似便捷的SQL写法背后隐藏的执行计划陷阱。文章的价值在于,它帮开发者建立起一种“性能风险意识”——你不是在主动优化,而是在避免日常开发中无意识犯下的错误。 这种视角对于需要排查慢查询或系统卡顿的团队尤其有用。它提醒我们,性能问题的根源往往不在于缺少某个高级技巧,而在于基础操作中的疏漏。把这些“坑”提前识别并避开,本身就是最有效的性能保障策略。
博客数据库的演变史
这篇讲的是数据库使用如何深刻影响技术架构演进。作者从亲身经历出发,分享了在公司中多次遇到由数据库使用不当引发的重大故障案例。这些案例并非孤立事件,它们共同指向一个核心发现:数据库的选型、设计与运维方式,往往是技术架构演进路径的隐形推手,甚至决定了系统能否稳健支撑业务发展。 文章并未停留在列举故障,而是将个人观察提炼为一种普遍认知:一个优秀的工程师,对数据库的理解深度直接关系到其架构设计能力。它揭示了在高速迭代的业务环境中,对数据库特性的掌握不足,可能埋下严重的性能或稳定性隐患。 作者基于实战踩坑的经验,得出了一个朴素的结论:主动学习数据库原理与最佳实践,不仅是修复故障的“救火技能”,更是前瞻性构建健壮系统的“必备思维”。这对于所有希望提升系统设计能力的开发者而言,都是一个值得深思的视角。
深入理解SET NAMES和mysql(i)_set_charset的区别
这篇讲的是在PHP操作MySQL时,看似效果相近的SET NAMES和mysqli_set_charset函数,其实存在一个关乎安全的重要差异。 作者从一次PHP安全编程培训切入,指出许多开发者混用这两个命令,但它们在协议层面的工作机制完全不同。SET NAMES仅仅是在MySQL服务器端设置字符集,它告诉服务器“我接下来发的数据是这个编码”,但并不会改变PHP客户端本身的编码认知。而mysqli_set_charset则不同,它通过专用协议命令,同时修改了客户端和服务器端的字符集。 关键差异在于:只有使用mysqli_set_charset后,PHP的mysql_real_escape_string函数才能基于正确的客户端字符集进行转义。如果仅用SET NAMES,转义函数可能因编码理解错误而失效,这为SQL注入攻击留下了潜在漏洞。文章清晰地指出了各自的使用场景:SET NAMES更适合用于纯数据库层面的字符集沟通,而涉及客户端与数据交互的编码设置,务必使用mysqli_set_charset以确保安全。这个区分是编写健壮PHP数据库代码的基础。
Two-phase commit(2PC) 与MySQL Cluster
这篇讲的是分布式系统中一个核心的一致性保障机制:两阶段提交协议(2PC),并结合MySQL Cluster的实际应用来理解它。作者直接切入2PC的本质——通过“准备”和“提交”两个阶段,确保所有参与者要么全部提交事务,要么全部回滚,从而在分布式环境中维护数据的一致性。 文章没有停留在理论层面,而是特别指出了MySQL Cluster内部正是采用2PC协议来同步数据。这为理解该协议提供了一个非常具体的视角:像MySQL Cluster这样的分布式数据库,其内部节点间如何保证“一个事务要么在所有节点上生效,要么都不生效”,答案就在于这套机制。 读完这篇文章,你能快速抓住2PC解决的核心问题——跨节点事务的原子性,也能看到它在一个成熟产品中的落地方式。对于需要理解分布式事务基础,或对MySQL Cluster内部原理感兴趣的开发者来说,这是一个清晰而实用的切入点。
MySQL数据库存储引擎和分支现状
这篇文章梳理了MySQL在经历Sun收购与随后被Oracle接手后,所面临的发展危机与社区演化路径。作者指出,在核心开发团队相继离开、官方主线发展放缓的背景下,MySQL并未走向终结,而是通过引擎的分化与分支的创立,开启了另一条技术演进之路。 文章重点剖析了存储引擎的演变,如InnoDB的稳固地位、MyISAM的渐退,以及XtraDB等增强型引擎的出现。同时,详细介绍了由此衍生出的主要分支,如MariaDB、Percona Server与Drizzle各自的定位与技术侧重,它们分别在兼容性、性能优化与架构革新上做出了探索。 对于技术选型者而言,这篇文章的价值不仅在于回顾了关键的历史事件,更清晰地呈现了如今“MySQL生态”下不同技术选项的真实面貌与内在逻辑,为理解当下数据库格局提供了扎实的背景认知。
ubuntu下移动mysql数据库位置
这篇讲的是在Ubuntu系统中迁移MySQL数据库存储目录的实用操作。作者坦言,移动数据库位置本应是个直截了当的任务,无论是出于数据管理、空间扩容还是系统迁移的考虑。 文章没有深入理论,而是直接从实操步骤切入,梳理了一个看似简单的四步走流程:首先停止MySQL服务,然后将数据库文件整体移动到指定的新路径。接下来是关键的一步:确保新目录的权限设置正确,这直接关系到服务能否正常启动。最后一步是编辑MySQL的配置文件`my.cnf`,将`datadir`参数指向新的数据目录路径。 文章特别点明,这些步骤构成了完成该操作的核心路径。它没有复杂的故障故事,而是聚焦于把每个环节的要点说清楚,比如权限问题可能带来的坑,以及配置文件的具体修改位置。对于需要调整数据库目录的系统管理员或开发者来说,这篇内容提供了一份清晰、无冗余的操作清单,能帮助你平稳地完成数据迁移。
XML路径语言:XPath
这篇讲的是XPath——在XML世界里精确定位数据的“导航语言”。作者从XML的树状结构出发,清晰解释了XPath如何像写文件路径一样,通过一系列步骤在复杂数据树中找到目标节点。路径表达式每一步由节点名、谓词和轴操作构成,用“/”分隔形成查询链。 文章特别强调XPath的实用性,比如用`/root/child[@id=1]`直接抓取特定元素,或是用`//section[position()>2]`批量选取片段。这些具体示例让抽象的“节点寻址”变得直观,读者能立刻想象出如何应用到实际数据处理或爬虫任务中。 如果你常与XML或HTML打交道,这篇把XPath的骨架拆解得很明白,没有冗余概念,直接给出可上手的语法框架。无论是清洗配置文件还是做Web自动化测试,理解这套路径逻辑都会让数据提取变得更顺手。
PostgreSQL
这是一篇关于 PostgreSQL 数据库的基础介绍。文章从其开源历史与核心定位切入,重点阐述了它作为一款功能强大的对象关系型数据库,如何在扩展性、标准兼容性以及数据完整性保障方面形成独特优势。 PostgreSQL 最显著的特点之一是其极强的可扩展性。它允许用户自定义数据类型、函数、操作符乃至索引方法,这使得它能够灵活适应从传统OLTP到复杂地理空间分析、时序数据处理等多样化的业务场景。文章提到了其丰富的内置数据类型(如 JSON/JSONB、数组、范围类型)以及强大的扩展生态系统(如 PostGIS 用于地理信息,TimescaleDB 用于时序)。 在核心功能上,PostgreSQL 对 SQL 标准的高度遵循、严谨的事务支持(ACID)以及多版本并发控制(MVCC)是其可靠性的基石。这些特性确保了数据的一致性,即使在高并发读写环境下也能稳定运行。 对于开发者和架构师而言,PostgreSQL 提供了一个兼具关系型数据库的严谨与 NoSQL 灵活性的选择。无论是构建全新的应用,还是需要处理复杂的分析查询,它都提供了一个坚实且功能完备的基础。
Virtual Indexes
这篇讲的是Oracle数据库中一个容易被忽略的索引特性演进。作者从Oracle 11g引入的“invisible index”(不可见索引)切入,指出其设计思想很可能更早源自“virtual index”(虚拟索引)的概念。文章对比了这两者的异同:不可见索引是数据库优化器能感知但不会使用的索引,主要用于评估索引变更的影响;而虚拟索引则更“虚”,可能不占用实际存储空间,常用于更早期的测试或特定工具链中。 核心差异在于它们与数据库优化器的交互程度和适用场景。不可见索引为DBA提供了一个安全的“试验沙盒”,可以在不影响线上性能的前提下,验证新索引的收益;虚拟索引则可能更多用于快速原型验证或特殊调试。文章并未止步于功能罗列,而是引导读者思考索引可见性管理背后的运维智慧——如何在保障系统稳定的同时,为性能优化保留灵活的探索空间。这种将新功能回溯至历史概念的分析视角,对理解Oracle的设计脉络很有帮助。
与数据相关的职业路径
这篇文章从当前火热的数据领域切入,为读者梳理了三条核心职业路径的分野与选择。作者没有泛泛而谈,而是具体对比了数据分析师、数据工程师和数据科学家这三个最常被混淆的角色。 文章指出,数据分析师更侧重于从现有数据中提炼业务洞察,是业务与技术之间的桥梁;数据工程师则专注于构建和维护可靠、高效的数据基础设施,是幕后的管道铺设者;而数据科学家则致力于运用统计与机器学习模型,解决更具探索性和预测性的复杂问题。 通过拆解日常工作内容和所需技能栈,文章清晰地揭示了三者的关键差异。最终,作者的结论落在个人选择上:兴趣和现有能力是最佳导航。喜欢与人沟通、洞察业务的人可能更适合分析师;痴迷于构建稳定系统的人或许会爱上工程师的工作;而热衷于数学和算法探索的,则可能在数据科学领域找到归属。
当logfile被误删除后
当一个只有单个logfile member的logfile group,在logfile变为current时被发现已被误删除,问题就变得相当棘手了。这篇处理记录详细复现了这一数据库紧急状况。 根因其实有两重:直接的起因是DBA的误操作(rm),但更深层的风险源在于,每个logfile group仅配置了一个logfile member,这使得 logfile 没有任何冗余和容错空间,一旦被破坏即意味着可能的数据丢失。当发现current logfile缺失时,数据库实例会因为无法归档或写入新日志而宕机。 文章梳理了从发现问题后的紧急处理流程:首先必须立刻停止数据库操作以防止日志序列被覆盖,接着评估通过操作系统文件恢复工具或 RMAN 备份找回日志文件的可能性。最终,恢复过程严重依赖于是否有可用的、完整的RMAN备份。 这次“踩坑”不仅是一次紧急恢复操作,更是一次深刻的架构教训。它强烈提示,生产数据库的日志文件绝不能只有单一副本,必须配置多个logfile member,并将它们放置在不同的物理磁盘组上。此外,建立严格的运维操作规范,避免直接执行高危命令,才是从根源上杜绝此类问题的方法。
转载:cassandra读写性能原理分析
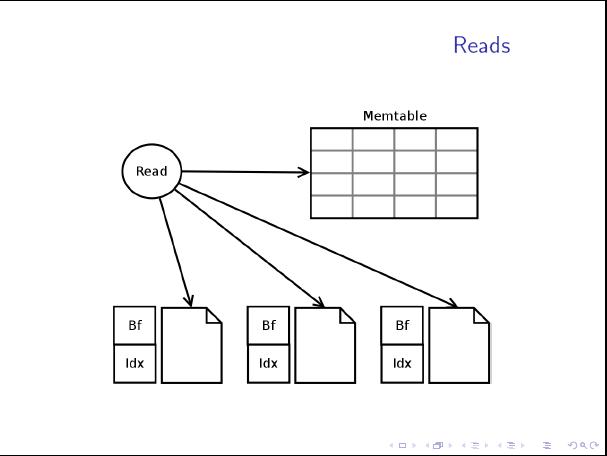
这篇讲的是Cassandra数据库在高并发读写场景下,其性能表现背后的底层原理。作者从数据在内存与磁盘间的流动路径出发,深入剖析了Cassandra如何利用LSM-Tree结构来极致化写入吞吐量。 核心思路在于将随机写转化为顺序写:数据先写入内存中的MemTable,满了之后再顺序刷入磁盘,生成不可变的SSTable文件。这带来了极高的写入速度,但也为读取带来了挑战,因为数据可能分散在多个文件中。 文章的亮点在于详细拆解了Cassandra为优化读性能所做的“权衡”与“设计”。例如,它如何通过布隆过滤器快速排除不存在的SSTable,减少不必要的磁盘IO;如何定期执行压缩(Compaction)操作来合并SSTable,既减少文件数量,又清理过期数据。文中对不同压缩策略(如Size-Tiered和Leveled)的适用场景也做了对比,帮助读者理解如何在写放大与读放大之间做出选择。 总的来说,这不仅仅是对配置参数的说明,而是带领读者理解Cassandra在“快速写入”与“高效查询”这两个看似矛盾的目标之间,是如何通过精巧的存储架构设计达成平衡的。
多IDC的数据分布设计(一)
作者从一次关于多IDC(数据中心)读写一致性的实际困惑出发,这个问题在分布式系统中颇为常见且棘手。他坦言最初想到了多种解决方案,但思路总不够清晰。 直到他参考了Google AppEngine工程师Ryan Barrett关于后端数据服务的一次演讲。该演讲深入剖析了跨数据中心事务的处理。作者借鉴了演讲中的分析方法来重新审视自己最初的问题,原本混杂的方案顿时变得条理分明。 文章正是基于这个清晰的框架,开始深入探讨多IDC环境下的数据分布设计,旨在为解决同时读写访问的挑战提供一种结构化的思路。
Zmanda让MySQL的备份与恢复更加方便快捷灵活
数据库管理员常为MySQL的备份恢复问题头疼:传统脚本维护成本高,第三方工具又可能不够灵活或费用高昂。这篇讲的是开源工具ZRM(Zmanda for MySQL)如何有效解决这些痛点。文章从实际运维场景出发,指出ZRM不仅免费提供社区版,其核心优势在于将备份恢复流程化、策略化。它支持灵活配置备份类型、频率和存储位置,并能通过Web界面进行可视化管理,大幅降低了操作复杂度。对于寻求可靠、低成本且易扩展的MySQL数据保护方案的团队,文中展示的ZRM具体功能和实践效果,提供了一个值得考量的实用选择。
深入浅出cassandra 4 数据一致性问题概述
Cassandra 4数据一致性问题概述,这篇文章以清晰易懂的方式,深入剖析了分布式数据库中的核心挑战。作者从Cassandra的分布式架构出发,对比了传统ACID模型与Cassandra最终一致性的本质差异,指出关键在于Cassandra在可用性、分区容忍性和一致性之间所做的权衡。文章系统性地梳理了不同一致性级别,如ONE、QUORUM和ALL,解释了它们在读写操作中的具体行为——例如QUORUM级别通过多数节点确认来平衡延迟与数据可靠性,并举例说明在多数据中心部署
Oracle高可用架构
这篇讲的是Oracle MAA(最大可用性架构)的全景式解读。作者从一个核心问题出发:如何设计数据库系统,才能在硬件故障、数据中心灾难等各种场景下,依然保持服务可用甚至不中断? 文章没有堆砌枯燥的理论,而是将MAA架构拆解为几个关键维度来剖析——从本地高可用的RAC,到数据保护的Data Guard,再到云环境下的综合方案。它把Oracle多年来围绕高可用、容灾和性能优化推出的一系列“武器”清晰地串联了起来,点明了每个组件适合解决什么问题,以及它们如何协同工作形成完整的防护网。 对于正在规划数据库架构或评估容灾方案的工程师来说,这种结构化的梳理非常实用。它帮你快速建立起从单机到集群、从本地到异地的完整认知框架,理解各种技术选择背后的权衡与定位。
数据库设计范式的理解
从去年年底开始,作者与多位技术朋友就数据库设计和架构展开深入交流,发现一个普遍现象:不少开发者过分推崇ORM工具和数据库设计范式,将其视为设计的金科玉律,却忽视了技术必须服务于业务这一基石。这篇文章正是基于这些交流,分享作者对数据库设计范式的真实理解。 文章指出,范式化设计虽能提升数据一致性和减少冗余,但若脱离业务场景,反而可能增加复杂度和开发成本。作者通过对比理论范式与实际业务需求,强调设计时应权衡范式优势与业务灵活性,避免为了范式而范式。例如,在读写性能要求高的系统中,适度反范式化能有效提升查询效率,而机械套用第三范式可能导致查询效率低下。核心观点是:数据库架构应从业务逻辑出发,让技术为业务赋能,而非反过来。 对于正在构建数据层的开发者,这提醒大家回归业务本质,在范式与实践间找到平衡点——设计范式是手段,业务成功才是目标。
MySQL也能并发导入数据
这篇讲的是一个实用技巧,解决MySQL导入SQL备份文件时令人头疼的效率问题。作者从“导入备份不能并发导致慢”这个普遍痛点出发,提出了一种清晰的解决思路:与其等待整个大文件串行执行,不如主动将它“化整为零”。 具体方案是,先通过脚本计算SQL文件的总行数与大小,然后按设定的单文件尺寸阈值,将完整的备份文件切分成多个小片段。在初始化好表结构后,便能并发地导入这些小文件。作者分享了从计算、切分到最终并发执行的关键步骤,让这个方法具有很强的操作性。 文章的价值在于转换了解决问题的视角,不依赖于MySQL自身功能的改进,而是通过外部的文件处理与并发控制,有效提升了数据恢复的吞吐量。对于经常需要处理大型SQL备份的DBA或开发者来说,这提供了一个可直接参考的性能优化方案。
闲谈分布式key-value存储服务nuclear及其他
这篇讲的是国内技术圈一度火热的 key-value 存储热潮。作者从豆瓣的 beandb、新浪的 SDD,到小道消息中的腾讯 TDB 以及人人网的 nuclear 等具体项目切入,勾勒出这股技术风潮在国内的落地图景。 文章进而追溯了这股潮流的源头:亚马逊那篇经典的 Dynamo 论文。虽然 Dynamo 本身并未开源,但它点燃了业界对分布式存储的探索。紧随其后,Facebook 引入了曾参与 Dynamo 开发的工程师,推出了开源的 Cassandra;同一理论脉络下,LinkedIn 也诞生了 Voldemort 系统。 作者通过梳理这些项目,清晰地展示了一条技术传播与演进的路径:从亚马逊的闭源实践,到 Facebook 等公司的开源实现,再到国内公司的借鉴与探索。读完这篇文章,能帮助你理解关键的 KV 存储系统并非凭空出现,而是在相似的理论基础上,结合各公司具体场景生长出来的不同枝干。