读书:谷歌不听话
这篇讲的是谷歌这家公司内部曾经出现的一些“不听话”的现象。作者从谷歌早期“不作恶”的信条出发,回溯了它在商业化、产品决策乃至组织文化上发生的一系列转变与争议。文章并没有停留在表面吐槽,而是深入分析了技术理想主义与商业现实之间的张力,如何影响着这家巨头的步伐。 文章具体提到了谷歌在某些项目(如与军方的合作)上引发的内外争议,以及其搜索引擎、广告业务在发展过程中逐渐偏离初心的具体表现。作者认为,这种“不听话”并非简单的叛逆,而是大型科技公司在规模扩张后,面对复杂利益和伦理挑战时必然遭遇的成长阵痛。 这给技术从业者一个很实在的提醒:任何公司或产品在追求增长时,都需要不断审视自身的初衷与边界。技术的价值与责任如何平衡,是谷歌的难题,也是所有科技人需要思考的课题。
基于购物车的导购猜想
这篇文章从B2C电商一个非常普遍的痛点——购物车遗弃率高企——出发,提出了一个有趣的观察和猜想。作者没有停留在分析遗弃原因或常规召回策略上,而是将视角转向了这些被遗弃购物车里具体商品的价值挖掘。 核心观点在于,这些遗弃购物车本身就是一个经过用户初步筛选、蕴含明确购买意向的“沉默数据金矿”。作者猜想,能否利用这些信息,为其他浏览或购买了同类、相关商品的用户,提供一种更精准的“商品导购”或“搭配推荐”?比如,分析特定商品被频繁遗弃后又被其他用户购买的路径,从而优化商品组合或促销策略。 文章将购物车遗弃从单纯的运营损耗问题,转化为一个潜在的个性化推荐与库存策略的数据源。这种二次利用的思路,为提升转化和用户体验提供了一个不同于常规的视角。
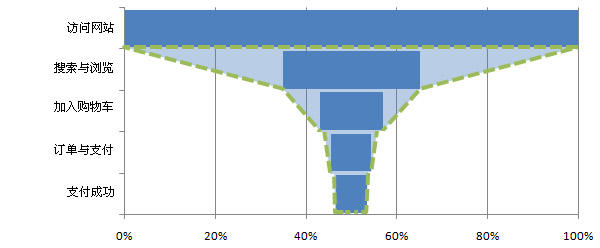
给微博打上标签
这篇文章探讨了微博信息流的理想状态与现实挑战。作者从一个基本观察出发:用户在微博上关注的对象都是经过精心挑选的,其初衷是为了获取高质量、符合个人兴趣的信息。因此,在理想情况下,信息流呈现的内容应该与用户的喜好高度匹配。基于此,文章提出的核心观点是,微博平台应致力于构建一个基于兴趣图谱的内容分发逻辑,即让用户通过关注相同喜好的人,来间接实现信息流的个性化与优质化。 文章进一步点明,这不仅关乎算法推荐,更涉及到用户行为与社交图谱的深层互动。作者将“给微博打上标签”这一操作,类比为对用户兴趣网络进行更精细的梳理和连接。其启发在于,在信息过载的社交媒体时代,单纯依赖算法有时会陷入回声室效应,而通过有意识地构建和关注基于共同兴趣的社交节点,用户能够更主动地塑造自己高质量的信息环境,让微博回归“看”优质内容的工具本质。
从细节看知识搜索
这篇讲的是知识搜索,它如何让你用日常的自然语言,就能直接获取那些经过平台精挑细选的高质量信息。文章从这个核心价值出发,梳理了国内外知识搜索领域的主要参与者,像国内的百度知道、新浪爱问,以及曾风靡一时的Yahoo! Answer和Naver。 作者的视角很实在,没有停留在概念定义,而是快速带我们看到实际的生态。我们能发现,这类服务的共同点是将海量互联网信息进行组织、筛选和结构化,目的是直接回答用户的具体疑问,而不仅仅是罗列网页链接。其本质是构建一个可被自然语言直接调用的、经过加工的知识库。 这种直接满足信息需求的方式,使得知识搜索成为了传统搜索引擎的一个重要补充。它让散布在互联网各处的答案变得有序且可获取,让整个网络更像是一个随时待命的、有组织的图书馆,而不仅仅是一个资料室。
一个Captcha的思路
这篇讲的是大家既熟悉又头疼的 Captcha 技术。作者开篇就点明了它的矛盾处境:一方面,它是对抗 spambot、保障服务安全的必要屏障;另一方面,它又实实在在地给正常用户增加了操作成本,有时甚至导致用户流失。 文章的核心观点在于,问题并不在于 Captcha 本身是否该存在,而在于当前的交互形式过于生硬和普遍。作者观察到,许多网站对所有用户“一刀切”地弹出验证,哪怕用户已经登录或行为模式十分可信。这种做法其实是在用最低效、体验最差的方式,去防御并非来自所有访客的威胁。 因此,作者的思路引向一个更精细的方向:Captcha 应该成为一个“智能开关”,而不是一堵固定的墙。理想情况下,系统应该能通过风险评分机制来判断——对于低风险操作和用户,应当完全隐藏 Captcha;只有当行为模式触发警报时,才介入验证。这样既维护了安全底线,又将对正常用户的打扰降到了最低。
怎样翻译更地道:否定句的翻译
这篇讲的是英文翻译中一个容易被忽略的细节:否定句的两种基本类型如何影响翻译的地道性。作者从一个常见翻译误区切入,清晰区分了“特殊否定”(如“unhappy”)和“句子否定”(如“not happy”)。虽然直接译为“她不高兴”时两者看似等价,但文章的核心在于揭示,一旦句子成分变得复杂,这两种否定的差异就会凸显出来。 作者进一步分析了在不同语境下,选择哪种否定结构会直接影响译文的准确度和自然度。例如,在强调某个具体特质(如“不快乐的状态”)和表达对整体情况的判断(如“目前不快乐”)时,翻译策略可能有所不同。文章旨在帮助译者识别这些细微差别,从而在翻译否定句时做出更精准的选择,避免因直译而导致的生硬或歧义。
怎样翻译更地道:It is…that…句型谚语的翻译
这篇讲的是如何处理“It is…that…”强调句型在英语谚语翻译中的地道转换问题。作者从中国学习者常见的理解习惯切入——大家通常知道要把that后的成分提前来理解强调含义,但在翻译成中文时,直接套用这个结构往往会让表达显得生硬别扭。 文章没有停留在语法规则的表面,而是聚焦在谚语这个特殊语境。它通过分析具体案例,比如“It is the tongue that offends most”这类句子,揭示了翻译这类谚语的关键在于跳出原文的强调框架,抓住谚语本身要传递的核心意思与韵律感。核心思路是:不必死守“It is…that…”的结构,而是根据中文谚语的习惯表达,灵活处理为“最……的是……”或直接用简洁的四字格、对仗句式来呈现。 这种处理方式体现了翻译中“重神似而非形似”的原则。文章为读者提供了一个清晰的思路:遇到这类谚语,先准确理解其强调的实质,再寻找中文里功能对等、形式地道的表达,从而让翻译结果既准确又自然,符合目标语言的阅读习惯。
怎样翻译更地道:译者一定要多走一步
这篇讲的是翻译里一个常被忽视的“笨功夫”。很多人抱怨外版教材译文啰嗦,明明简单的事绕来绕去。作者从这个现象切入,提出了一个核心观点:这种“啰嗦”恰恰是负责任的译者“多走了一步”。译者不能只翻译字面意思,更要为屏幕前、书本前那个未知的读者考虑——他可能基础不同,需要更细致的引导。 文章进一步指出,这多走的一步,是译者从“作者代言人”到“读者摆渡人”的角色转换。译者需要预判读者的困惑点,主动增加必要的解释、衔接或背景说明,而不是机械地搬运文本。这种“多走一步”的思维,其实超越了翻译本身,对于任何需要进行知识传递的技术文档写作、教程编写都具有启发意义:我们是否也在为“广大读者”而不是“某个想象中的熟手”写作? 最终,文章让我们看到,地道的翻译不仅是语言的转换,更是一种体贴周全的沟通艺术,其价值在于真正降低了知识获取的门槛。
怎样翻译更地道:and不是“和”
这篇文章从常见的翻译误区入手,指出初学者常把“and”简单处理为“和”,导致译文生硬。作者对比了两种翻译思路:一种是条件反射式地逐词对应,另一种是根据上下文灵活处理。关键差异在于,前者只关注词语的孤立含义,而后者更注重词语在具体语境中的功能和衔接作用。 文中以“and”为例,拆解它在不同场景下的实际作用。比如,连接并列成分时,有时需要省略不译;表示递进或转折时,可能更适合译为“而且”或“却”。作者通过实例展示,地道的翻译需要理解句子背后的逻辑关系,而不是机械地套用字面意思。 这篇文章提醒我们,翻译的流畅感往往来自对语境和语感的把握。它给出的不只是一个单词的译法,更是一种避免“翻译腔”的思考方式——先理解原文的意图,再寻找最自然的中文表达。
怎样翻译更地道:冠词a的翻译
这篇讲的是英语学习和翻译中一个具体而微的痛点:那个无处不在却时常让人头疼的冠词“a”该怎么翻。文章从维基百科对冠词的定义出发,直指一个核心差异——中文里压根就没有冠词这个语法范畴。这就导致在翻译时,英文中自然存在的“a/an”常常在中文译文里“消失”了。 作者没有停留在指出差异,而是深入拆解了在实际语境中处理“a”的几种常见策略。比如,当“a”表示泛指、数量“一个”或某种抽象的“某种”含义时,译者需要根据上下文进行灵活的增、删或意译。文章通过对比分析,让读者清晰地看到,简单地不译或一律硬译都会损害中文表达的地道感。它提供的不是僵硬的规则,而是一套需要结合语境判断的思维工具。 对于经常需要处理英汉互译的读者,无论是学习者还是从业者,这篇文章的价值在于它将一个高频出现的“小”问题掰开揉碎,提供了可操作的分析思路。掌握这种处理微观语言差异的方法,对提升译文质量有着切实的帮助。
怎样翻译更地道:无生物主语的处理
这篇讲的是翻译中一个具体而常见的挑战:如何处理英语中频繁出现、中文却不太习惯的“无生物主语”句式。 作者从典型句子切入,展示了直接按字面翻译(如“It is widely believed that...”译成“它被广泛认为……”)带来的生硬感。文章深入分析了中英文在主语选择上的核心差异:英语允许“抽象事物”或“环境”作为主语发出动作,而中文更倾向让“人”或“具体事物”来主导句子。针对这一点,作者给出了几种非常实用的处理原则,例如将英语的无生物主语转换为中文的动宾结构(“An earthquake occurred”译为“发生了地震”),或者调整句子视角,把动作的发出者或承受者明确出来。最后,文章也提醒,这种转换并非绝对,在科技文本或追求客观风格的语境中,有时保留一定的“无生物主语”也是可行的选择。掌握这些技巧,能让译文在保持准确性的同时,读起来更符合中文的表达习惯,避免“翻译腔”。
三十分之一的梦想
这篇文章从一次朋友间关于职业梦想的对话切入,探讨了顶尖平台的价值与个人成长路径的选择。作者的朋友渴望加入顶级VC,理由很具体:结识聪颖的年轻人、接触前沿的想法、参与企业成长并分享成功。 作者通过追问“为什么是顶尖的VC”,实际上引导我们思考:在职业起点或转换期,选择最高标准的平台,其核心收益并非头衔本身,而是上述三类稀缺资源的密集交汇。这像是一个筛选器,将最活跃的思维、最具潜力的项目与最渴望成长的人聚集在一起,加速个体的认知迭代与人脉积累。 文章没有给出普适答案,但点明了关键:评估机会时,不仅要看“能做什么”,更要看“能与谁同行、接触何种层级的问题”。这种对平台“附加价值”的清醒认知,或许能帮助我们在众多选择中,更清晰地定位那条属于自己的成长路径。
怎样翻译更地道:被滥用的“被”
这篇讲的是中文翻译中一个常见但容易被忽略的细节:如何摆脱英文被动语态的“翻译腔”。作者指出,许多译者习惯性地将英文的“be + 过去分词”直接对应为“被xx”,虽然语法正确,但过度使用会显著影响中文表达的流畅度与地道感。 文章并非否定“被”字句本身,而是强调需要根据具体语境灵活处理。作者通过对比生硬翻译与地道中文表达的例子,揭示了关键差异:中文往往更倾向于使用主动句式、省略施动者、或选用“由”“遭”“给”等替代词来传达被动含义。这种处理不仅关乎语法正确性,更关乎是否符合中文的叙事逻辑和阅读习惯。 对技术写作者和翻译者而言,这篇文章点明了一个提升文本专业感与可读性的具体路径——不是机械地转换语法结构,而是深入理解两种语言在表达被动概念时的思维差异。掌握这一分寸,能让技术文档、产品说明乃至日常沟通的译文都显得更加自然和专业。
怎样翻译更地道:当遇到when的时候
这篇讨论的是翻译中一个常见却容易被忽视的痛点:如何摆脱机械的“翻译体”。作者以英语中高频出现的连词“when”为例,指出许多译者会习惯性地将其固定译为“当……时”、“在……的时候”。这种看似忠实的处理,却让中文译文透出明显的欧化痕迹,读者仿佛能直接“看”到原文的结构。 文章的核心在于对比。作者剖析了固定译法的问题——它常常割裂了汉语的句法节奏,使表达显得冗长生硬。接着,文章展示了更地道的处理思路:根据具体语境,灵活地将“when”转化为前置时间状语、合并到主句动词中,甚至完全省略不译,转而依靠上下文的逻辑关系来传达时间顺序。 作者强调,这种细微处的变通,其意义远大于词汇本身的替换。它触及了翻译中“形”与“神”的平衡。真正的地道,不是逐字对应的“安全”,而是让译文读起来像原生中文。这篇短文提醒我们,每一个小词的背后,都连贯着对中英文节奏差异的深层理解。
怎样翻译更地道:“as somebody said…”的翻译
这篇讲的是如何把英文里常见的引用句式“as somebody said”翻译得更地道。作者发现,很多人会不假思索地译成“正如某人所说”,但这常常显得生硬,缺乏中文的语感。文章对比了两种核心思路:一种是“移植式翻译”,保留原文结构;另一种是“归化式翻译”,彻底转换为中文的表达习惯。 作者指出,关键差异在于中文更习惯将引用内容前置,形成一种铺垫或结论。因此,更地道的做法是先抛出观点本身,再用“正如……所言”来点明出处。文章还提供了丰富的例子,比如将“as Einstein correctly pointed out”译为“正如爱因斯坦所正确指出的那样”略显累赘,而处理为“‘想象力比知识更重要’,爱因斯坦一语中的”则更为有力。 这种翻译上的取舍,体现的其实是对中英文思维节奏的把握。它提醒我们,优秀的翻译不是词对词的对应,而是信息流动方式的转换,让读者首先关注到思想本身,而非引用的形式。
自然描述与自然任务
这篇讲的是一个看似微小却普遍存在的问题:描述与任务的脱节。 作者从一个点菜的尴尬场景切入:当顾客问“有什么好吃的”,服务员却用一串化学名词和拉丁学名来描述菜品——比如“黄豆与可食用菌落群酿制剂与 Carassius auratus 共同高温加热制成品”。技术上完全正确,但彻底脱离了“点菜”这个实际任务的需求场景。 这其实映射了技术交流中的常见陷阱。我们常常沉浸于精确、专业的表述中,却忽略了对话的根本目的是什么。当用户真正需要完成一项“自然任务”时,我们提供的“自然描述”是否真的在帮助他,反而成了需要额外解码的负担?文章通过这个生动比喻,揭示了好的交互和设计应始终锚定在用户的实际目标上,而非自我满足于表达的“正确性”。 说到底,沟通和设计的核心是让人更顺畅地达成目标,而不是制造理解的门槛。否则,吃饭可能真的会变成一件麻烦事。
如何从无到有建立推荐系统
这篇讲的是,一个技术人如何通过自学和整理,为内容型网站搭建出推荐系统的第一版。 作者在实践中发现,虽然推荐系统概念普及,但关于“从无到有”构建它的清晰路径却很少见。他甚至潜入国内顶尖的推荐系统技术社群求教,但依然感到困惑,难以形成一个以**内容推荐为核心**的产品落地蓝图。转机来自《集体智慧编程》这本书。作者没有止步于阅读,而是将书中的核心思想与工程实践相结合,梳理出了一份可操作的框架。 这篇文章的价值就在于它跳出了纯理论,直接给出了一个面向**内容型网站**的推荐系统产品框架草图。它分享的不仅是技术选型,更是从零开始思考产品与技术如何结合的完整思路。对于想自己动手实现推荐功能,但苦于无从下手的开发者来说,这篇笔记提供了一条清晰的从理论到原型的实践路径。
怎样翻译更地道:so…that…的翻译
这篇讲的是英语学习中常见的“so…that…”句型,作者从译者的实际困境切入——很多学习者从小被教要直译为“如此…以致于…”,但生硬套用在实际翻译中往往会让中文读者感到别扭,甚至需要反推回英文才能理解,这违背了翻译降低理解门槛的初衷。 文章通过具体例子指出,译者的职责是让译文自然流畅。作者提出,面对“so…that…”,需要根据上下文灵活处理:有时可以用“太…了”、“如此…以至于…”等更地道的表达,有时则需要彻底拆分句式,用简洁的中文重新组织逻辑。核心在于摆脱机械对应,让译文读起来像原生中文。 作者从翻译细节的重要性出发,强调高质量翻译需要超越字面准确,追求表达上的自然与贴切。文中探讨的摆脱直译困境的方法,不仅适用于这一个句型,也提醒所有翻译者:好的翻译应该让读者直接抓住意思,而不是在别扭的语句中费力还原原文。
音乐智能推荐
这篇讲的是音乐智能推荐系统的技术方案。这篇来自SlideShare的演示文稿,共27页,系统梳理了为用户个性化推荐歌曲背后的核心逻辑与技术演进。 它首先点出了音乐推荐面临的经典难题:用户音乐品味的多样性与动态变化、海量曲库的稀疏性,以及如何挖掘音乐之间深层的相似性。方案的核心在于介绍主流的技术路径,包括基于用户行为的协同过滤(CF),以及分析音频特征和元数据的内容感知方法。文中进一步探讨了更前沿的思路,例如利用图神经网络(GNN)对复杂的用户-音乐交互关系进行建模,以捕捉更丰富的潜在连接。 这份材料没有停留在算法罗列,而是呈现了不同推荐策略之间的权衡与互补关系,为理解现代音乐平台(如Spotify、网易云音乐)推荐引擎背后的“大脑”如何工作,提供了一个系统性的入门框架。
编程珠玑番外篇-G. 高级语言怎么来的-4
这篇讲的是 LISP 语言的起源,以及它如何与人工智能领域结下不解之缘。 作者从早期 AI 研究的困境切入,指出冯·诺依曼和图灵等先驱发现,用当时主流的基于数学公式的语言来模拟人类思维过程,表达起来极其别扭。为了解决“如何高效表示和处理复杂的符号结构”这一核心问题,John McCarthy 在 1958 年设计了 LISP。 文章重点剖析了 LISP 的几个关键设计如何与 AI 的需求一拍即合:其列表(List)数据结构能自然地表达嵌套和递归的思维;函数式编程范式与符号演算的逻辑高度契合;动态类型则让探索性的编程变得灵活。正是这种“为问题量身定做”的哲学,使得 LISP 不仅成为了 AI 研究的首选工具,也深刻影响了后续编程语言的哲学。 读完你会理解,LISP 与 AI 的这场“青梅竹马”,根源在于它们共享了处理复杂符号这一最原始、最核心的挑战。