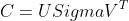如何计算两个文档的相似度(三)
这篇讲的是《如何计算两个文档的相似度》系列文章的实战篇。作者从上一节的gensim基础用法出发,这一次要用“课程图谱”的真实课程数据,来实际验证和改进文档相似度计算的方法,并引入了NLTK这一专业的自然语言处理工具进行文本预处理。 核心思路是利用NLTK解决真实英文文本中的“脏”问题。作者展示了,如果只是简单地将单词小写化,标点符号和单词会粘在一起,影响计算质量。因此,引入了NLTK的`word_tokenize`函数进行精细分词,将“texts.”这样的组合拆分为“texts”和“.”。更关键的一步是使用NLTK内置的英文停用词表(共127个词,如“the”, “is”, “and”),过滤掉这些高频但对主题区分贡献低的词汇。 为了让验证可复现,文章提供了完整的Coursera课程数据集,包含379门课程。数据集结构清晰,每行是“课程名\t课程简介\t课程详情”,且已清除HTML标签。摘要中展示了加载数据和进行NLTK处理的初始步骤代码,体现了从数据准备到工具应用的完整实践流程。
php扩展中如何定义线程安全的全局对象
作者在开发一个PHP图片裁剪扩展(tclip)时,为了提升效率,希望将OpenCV的人脸识别分类器(CascadeClassifier)作为全局对象,在扩展初始化时加载一次供后续重复使用。这引出了一个具体的技术问题:如何在PHP扩展中定义线程安全的全局对象。 文章直击踩坑点:最初尝试直接在模块全局变量中声明CascadeClassifier对象,却遭遇了“‘CascadeClassifier’ does not name a type”的编译错误,因为该类并未在对应的头文件中引入。作者调整方案,改用`void *`指针来声明全局变量,并在C源文件中定义一个静态的CascadeClassifier实例。在模块初始化函数(`PHP_MINIT_FUNCTION`)中完成配置文件的加载与实例化后,将实例的地址赋给那个`void *`类型的全局指针。 核心的解决思路在于,使用`void *`绕开了头文件依赖问题,并将对象实例的实际生命周期管理在静态作用域。而在扩展的实际函数中使用时,则需要通过`TCLIP_G()`宏访问该指针并强制类型转换回`CascadeClassifier *`。文章特别指出,要确保扩展的线程安全,就必须通过这类模块全局变量宏来访问数据。整个过程为在PHP C扩展中安全复用大型配置对象提供了一个可行的实践路径。
利用新词统计特征进行中文分词
这篇讲的是如何改进中文分词模型以更好地适应新领域。作者指出,传统基于条件随机场(CRF)的分词模型主要依赖上下文特征,在面对训练数据未覆盖的新词(如跨领域的专业术语)时,分词准确率会明显下降。 为解决这个问题,作者在特征中引入了新词的统计表现特征,比如词频高、搭配稳定等,提出了增强的FCRF模型。在《SIGHAN Bakeoff 2005》语料上的测试表明:当训练和测试文本属于同一领域时,FCRF与传统CRF效果相当;但当跨领域测试时(例如用金融领域模型分词体育文本),FCRF的优势就凸显出来了,其F-score和未登录词召回率(Roov)均有大幅提升,证明新特征有效增强了模型的领域适应性。 文章还对比了FCRF与其他分词工具在金庸小说上的表现,并说明FCRF需要预先统计新领域的词频信息,这会略微牺牲分词速度,但换来了更好的新领域适应能力。
失败的人生
这篇观点类文章从一位观察者视角剖析了80后群体的普遍心态困境。作者指出,不少80后身上带有“失败者的气息”,具体表现为缺乏锐气、过度纠结、想法与行动分裂,以及既自足又抱怨的矛盾心理。 文章分析了这种心态的成因:他们成长于社会开放、经济高速发展的时代,却不幸遭遇了上下挤压的竞争环境,成功机会相对稀缺。作者承认社会结构性因素的影响,但更强调80后一代本质上聪明、有干劲,所缺的是耐心与把握机会的勇气。 核心观点在于对30岁“中年危机”叙事的反驳。作者认为,与前辈们30岁即拥有丰富经验的时代不同,今天的80后30岁征程才刚刚开始,不应过早摆出老成姿态或热衷总结。文章呼吁他们相信自己仍能拼搏,应身处一线发挥所长,而非寻求安逸。 对读者而言,这篇文章的启发在于:环境制约固然真实存在,但心态的年轻与行动的勇气是突破困境的关键。个人的奋斗周期应基于自身条件重新定义,而非困于他人的经验模板。
浅析十三种常用的数据挖掘的技术
这篇讲的是数据挖掘领域里十三种核心的技术方法,作者没有停留在抽象概念,而是系统地梳理了从统计、关联规则到神经网络、模糊集等每种技术的底层逻辑。比如,统计技术的核心是先假设一个概率模型再进行挖掘;而关联规则旨在发现变量间隐藏的规律性,其生成的规则带有可信度。 文章特别适合想快速建立技术全景图的读者。它清晰区分了各类技术的特点:决策树用于展示条件规则;神经网络通过输入层、隐含层和输出层的复杂连接来建模;粗糙集处理不精确的数据分类;差别分析则专注于发现异常模式。这些技术并非孤立存在,它们共同支撑起从分类预测、聚类分析到异常检测等数据挖掘的核心任务。 对于技术实践者而言,这篇文章的价值在于将众多方法置于统一框架下进行说明,帮助读者理解每种技术解决哪类问题、其基本假设是什么。结尾也点明了数据挖掘作为一门交叉学科,融合了机器学习、统计学、数据库等多个领域的精华,其发展最终旨在将海量数据转化为可用知识。
数据化比大数据更靠谱
这篇讲的是,为什么对实体企业而言,“数据化”比追逐“大数据”更为务实和迫切。作者指出,大数据概念火热,但许多传统行业其实更需要先完成自身业务的扎实数据化,这好比电子商务的核心终究是商务的电子化。 文章核心观点很清晰:企业最终要的是用户,大数据只是决策支撑。海量数据本身价值有限,关键是要理解数据产生的逻辑,并倒推出数据与企业经营、用户行为的内在联系。作者强调,数据化是一个需要培养的决策思维,不会一蹴而就。 那么怎么着手?文章给出了具体路径:从经营业绩数据化开始,让管理者对财务数据敏感起来;到业务模式数据化,例如零售业可通过图像识别技术捕捉线下用户行为;再到用户行为数据化,文中以中坤集团将景点数字化、提升游客体验为例;最后落实到员工管理的数据化。 作者提醒,数据化的另一关键是与移动互联网、物联网的融合,因为这提供了与用户深度绑定并挖掘数据的最佳机会。总体而言,这篇文章为传统企业提供了一份从理念到实践的“数据化”落地指南,强调数据化对企业经营决策的实际意义。
浅谈翻译的两个基本问题
这是一篇探讨翻译本质与常见困境的知识点对比类文章。作者从“翻译是什么”和“直译与意译如何选择”这两个困扰许多新手的问题切入,澄清了两个普遍的误区。 首先,文章指出翻译并非高不可攀的“艺术”,而是一门可通过训练掌握的“技艺”。它同时包含技术(如句型转换规则)、艺术(对文字美感的判断)和科学(运用工具、分析长难句)三个维度。只要在这些方面没有明显短板,普通人都有机会入门并胜任大量实用文本的翻译工作。 其次,针对直译与意译之争,作者通过具体例子(如“muddling along”译为“虚与委蛇”而非简单“等待”)分析了两者的局限:直译有时会生硬难懂,而意译若功力不足则可能偏离原意或丢失文字本身的形式美感。文章给出的核心原则是:以原文性质为准绳。对于新闻、说明书等信息类文本,应以意译为主,确保流畅易懂;对于诗歌等形式本身具有审美价值的文字,则需增加直译的比重,保留原文神韵。 作者认为,这场争论之所以持久,正源于文字同时承载信息与审美的双重功能。解决之道不在于二选一,而在于根据翻译目的和原文特点,找到两者的最佳结合点。
基于用户行为分析的搜索引擎自动性能评价
搜索引擎性能评价一直是个难题。传统Cranfield方法需要人工标注标准答案,面对数十亿网页的搜索结果池,这项工作变得耗时耗力,难以满足算法快速迭代的需求。 作者从信息检索评价的核心困境出发,梳理了各种自动评价方案的探索与局限。无论是基于搜索结果反馈的“伪相关”标注,还是利用外部目录资源,其可靠性都存疑。文章进而聚焦于用户点击行为这一天然存在的行为日志,分析其作为自动化评价依据的潜力。作者通过对比不同搜索引擎上“电影”这一查询的点击分布,发现信息类、事务类查询的答案多元且用户行为差异大,难以跨系统评价。 因此,文章将自动评价的可行范围明确限定于“导航类查询”——这类查询通常只有一个明确的目标网站,用户点击行为高度一致且可靠。作者详细阐述了如何从海量日志中筛选导航类查询,并利用群体点击行为自动标注唯一正确答案,从而实现基于“首现正确结果排序倒数”等指标的全自动性能评测。这为搜索引擎在保持评价科学性的同时,大幅提升迭代效率提供了一条切实路径。
如何计算两个文档的相似度(二)
这篇系列文章的第二部分聚焦于gensim的实战上手。作者从安装这个看似简单的步骤切入,详细记录了在Ubuntu和Mac OS上配置gensim及其依赖库NumPy、SciPy时遇到的典型问题——比如Mac上因缺失Fortran编译器导致的SciPy安装失败,并给出了解决方案(通过Homebrew安装gfortran),这对国内开发者很有参考价值。 在核心的使用演示部分,文章没有照搬官方教程,而是另辟蹊径,使用了“Latent Semantic Indexing (LSI) A Fast Track Tutorial”中的三个简短英文文档作为案例。整个流程清晰展示了从文本预处理(小写化)、构建词袋字典、生成文档向量,到训练TF-IDF模型,最终通过LSI(潜在语义分析)将文档映射到二维主题空间的全过程。作者特别指出了gensim在计算IDF时未对出现频率为100%的词(如介词a, in, of)进行平滑处理导致其权重为零的现象,并以此反向论证了TF-IDF算法在过滤停用词上的有效性。 通过这个从安装到模型输出的完整闭环,文章为读者提供了一份可复现的gensim入门实践指南,为后续在“课程图谱”上的应用打下了基础。
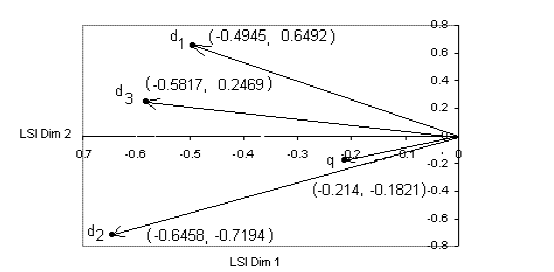
如何计算两个文档的相似度(一)
作者在构建“课程图谱”网站时,面临课程推荐系统冷启动的难题:缺乏用户行为数据,人工标注标签又耗时。一个可行的思路是直接利用课程文本内容计算相似度,而作者最终选择了基于主题模型的自动化方案。 核心工具是强大的Python库gensim,文章以LSI(浅层语义索引)模型为例,展示了如何将两篇文档映射到主题维度,进而计算其语义相似度。作者用不到百行的代码便实现了这一流程,并给出了以Andrew Ng《机器学习》课为示例的推荐效果图。文章还规划了进一步优化:利用全量英文维基百科语料,在普通笔记本电脑上训练更复杂的LSI和LDA模型,以提升相似度计算效果。 文章整体脉络清晰,分为三个部分:先简要铺垫TF-IDF、SVD等基础知识点并提供参考资料;再详解gensim的安装与具体实现;最后探讨在大规模语料上训练模型的应用。作者并非平铺直叙,而是从实际项目需求出发,分享了从选型到落地的完整思考与实践。

从抛硬币试验看概率论的基本内容及统计方法
这篇讲的是,概率世界里那个最经典也最容易被轻视的例子——抛硬币。作者从“概率为何存在”这个哲学问题切入,指出我们并非先验地认可概率,而是从类似“抛多次硬币,正面频率趋近50%”的反复观测中,总结出了统计规律。文章随后系统梳理了如何将这种直观认识形式化为数学模型:从要求等可能结果的古典概型,到更为普适和严格的公理化概率定义,并引出样本空间、随机事件等核心概念。 文章接着引导读者从静态的模型走向动态的统计规律。它介绍了大数定律如何从理论上确保频率的稳定性,并以此为基础,介绍了描述二元(正反)结果的二项分布,以及当试验次数极大时正态分布如何登场。在应用层面,文章触及了如何从有限数据反推模型参数(最大似然估计),以及如何基于模型判断一个观察到的现象是否显著(假设检验)。 这篇文章的价值,就在于将抽象的数学大厦建立在一枚硬币的抛掷之上,让读者清晰地看到,从简单的物理实验到严谨的统计推断,中间经历了怎样的思维跨越。
模糊逻辑在 AI 中的应用
这篇文章从作者阅读游戏编程书籍中有关模糊逻辑的章节出发,用了一个生动的例子来阐释:在游戏中,一个NPC决定是否追击玩家,可能同时受到“距离出生点远近”和“自身血量多少”等多个条件的约束。传统的精确逻辑设置一个硬性阈值(如超过40米就放弃),会导致在边界点上决策发生突变,不够智能和平滑。 作者随即引出模糊逻辑如何解决这一问题。它不再使用非此即彼的分界,而是将“远近”、“血量多少”这样的输入,通过定义“近、中等、远”等模糊集合进行软化。然后,基于一组人类经验式的模糊规则(例如“如果距离远且血量少,就非常不想追击”),经过模糊推理和最后的去模糊化计算,能输出一个确定的、但连续平滑的决策倾向值。 文章进一步指出,当决策条件增多、规则发生组合爆炸时,可以使用Combs方法将复合规则拆解为一维的独立规则来简化设计。虽然可能导致少量矛盾,但实践证明其结果与完整规则组合非常接近。整体上,这篇文章通过一个具体的游戏AI场景,将模糊逻辑从概念到实现的关键步骤进行了清晰拆解,说明了它如何让AI的决策行为更接近人类的柔性判断。
给程序员推荐几部电影
这篇文章从程序员视角出发,推荐了六部与编程思维紧密相关的电影。作者的推荐逻辑并非基于票房或类型,而是精准地为每部作品提炼了一个核心编程概念作为关键词:例如《黑客帝国》的“矩阵”、《盗梦空间》的“虚拟化”、《云图》的“并行”,乃至《恐怖游轮》的“递归”与《源代码》的“重入”。 这种关联非常巧妙,它将电影中看似科幻或烧脑的情节,映射为开发者熟悉的抽象模型。比如《恐怖游轮》中不断循环的困局,正是递归函数调用自身直至基线条件的经典体现;而《源代码》里在有限时间切片中反复“重启”寻找答案的过程,则像极了重入操作。文章不仅提供了片单,更提供了一种用专业眼光解读故事的有趣视角。 对于程序员而言,这些电影或许能成为理解抽象概念的另类注解,或在下班后提供一种充满技术梗的放松方式。作者也将完整片单整理成了豆瓣列表,方便读者一键收藏,体现了社区分享精神。
U&A在产品市场竞争状况调研中的应用
如何量化产品的市场地位和竞争态势?这篇讲的是利用“使用习惯和态度研究”(U&A)这一成熟调研方法论来进行分析。作者从品牌渗透率、最常使用率、品牌忠诚度等核心指标出发,拆解了一套完整的问卷结构与分析思路。 文章通过具体案例展示了如何应用这些指标:比如,通过计算各品牌在不同时间段的使用率与“品牌采用指数”,可以判断用户对品牌的认同程度;用“最常使用率”近似模拟市场占有率;而通过分析用户的“保持率”与“转移率”,则能清晰看到用户在不同品牌间的流动情况与忠诚度。 分析结论十分具体,例如发现案例中品牌a在各项指标上均处于领先地位,且用户忠诚度最高;而其他品牌则面临用户流失的问题,有的品牌甚至有超过一半的新用户是从品牌a转移而来。文章最后也指出,这套方法不仅限于竞争分析,还可拓展至购买习惯研究、品牌形象挖掘等多个维度,为产品定位和营销策略提供数据支撑。
百度AStar2008的一道题:成语纠错
这篇文章聚焦于百度AStar 2008竞赛中的一道经典编程题:“成语纠错”。题目要求在一个错误的四字成语中,只修改其中一个字使其变为给定列表中的正确成语,且修改前后的汉字必须属于同一分类,从而保证结果唯一。 文章的核心是分享作者当年满分通过此题的C++实现思路。关键巧妙之处在于对汉字编码(GBK)的处理和高效的索引设计。代码没有暴力枚举所有可能,而是首先利用自定义的哈希函数,将每个GBK编码的汉字映射为一个整数索引。接着,程序为两大数据建立了索引:一是“汉字-分类”关系,通过汉字索引快速查找它所属的分类列表;二是“成语列表”,按成语的第几个字符建立索引,方便快速定位包含某个特定汉字的成语。 解题时,对于待纠错成语的每一个字符位置,程序快速查找出成语列表中所有在该位置与之相同、且其他三位字符也恰好只有一位不同的候选成语。随后,验证修改处的两个汉字是否属于同一分类。这种基于精确索引的查找方式,避免了低效的线性扫描,将复杂度控制在了合理范围内,清晰地展示了如何将题目限制(编码、分类)转化为高效的编程解法。
皮尔逊积矩相关系数的学习
作者从相似度计算中常见的皮尔逊相关系数出发,用两种视角帮你真正“看懂”这个公式。第一种是统计学视角,通过高中课本里的Z分数处理,逐步拆解公式;第二种是几何视角,将其理解为两组数据向量夹角的余弦值,文章里还配了直观的回归线示意图。 两种理解方式都附有清晰的Python实现代码,让抽象概念变得可操作。不仅如此,文章最后还梳理了应用皮尔逊相关的四个关键约束条件,并提到了实践中常输出的相关系数与独立样本检验系数。 从“算出来”到“看明白”,这篇文章提供了从基础推导到几何直观的完整路径,能帮你建立更立体的技术理解。
为什么特斯拉是史上最伟大的geek?
这篇讲的是尼古拉·特斯拉如何被大众严重低估,而商业巨头托马斯·爱迪生却被误认为“电力之父”的故事。作者通过一系列具体对比,勾勒出一个被遗忘的天才极客形象。 核心在于颠覆认知:我们今天依赖的交流电系统、无线电技术、雷达概念乃至X射线的早期研究,关键突破都指向特斯拉。他像一个痴迷的极客,不断“修补没坏的东西”,将人类带入第二次工业革命。相比之下,爱迪生被刻画为精明的CEO,他擅于改进和专利垄断,甚至曾用不光彩的手段诋毁交流电。 文章抛出了一连串震撼的事实:特斯拉的17项专利构成了马可尼无线电的基础,他早在1917年就向美国海军提出了雷达方案,而他对X射线的危险性也早有警告。这些细节串联起来,旨在为这位孤独的发明家正名——他定义了现代世界的电力与无线通信基石,却长期活在另一位更懂营销的“发明家”阴影之下。读完会让人重新思考,真正的极客精神究竟是什么。

谈谈SVD和LSA
这篇讲的是SVD(奇异值分解)和LSA(隐含语义分析)之间的关系。作者首先拆解了LSA的核心思想:它是一种主题模型,认为词语背后由潜在主题驱动。比如“计算机”和“电脑”在传统词向量空间中无关,但在LSA看来它们同属一个主题,因此包含它们的文章也相关,这突破了表面词汇的限制。 而SVD正是实现LSA的关键数学工具。文章从特征值与特征向量这些基础概念切入,为理解SVD如何分解文档-词矩阵、提取潜在语义结构做了铺垫。作者也点出SVD的广泛应用,比如它同样是PCA(主成分分析)和图像压缩的技术基础。整篇文章从数学基础讲到实际应用,清晰地勾勒出SVD作为通用分解方法,如何催生了LSA这一文本分析利器。

概率语言模型及其变形系列-LDA及Gibbs Sampling
这篇讲的是概率语言模型系列的第二篇,聚焦于LDA(Latent Dirichlet Allocation)及其参数推断方法Gibbs Sampling。文章从LDA的核心思想切入:如何通过无监督学习,从文本中发现隐含的“主题”结构,从而解决“一词多义”和“一义多词”的语义匹配问题,让搜索结果在语义层面真正相关。 理解LDA的关键在于其概率基础。文章深入剖析了“随机生成过程”视角,解释了文本如何被看作词项的样本集合。重点阐述了多项分布(Multinomial)与其共轭先验狄利克雷分布(Dirichlet)的特性与计算优势——后者被称为“分布之上的分布”,其样本恰好是多项分布的参数。这些数学工具共同构成了LDA模型的基石。 作为PLSA到变形LDA之间的承上启下之作,文章不仅厘清了基础概念,也为后续探讨Twitter LDA、Labeled-LDA等各类变形模型铺平了道路。对于想从理论层面掌握主题模型的读者,这篇系统性的推导提供了扎实的起点。
概率语言模型及其变形系列-PLSA及EM算法
这篇从LSA(隐性语义分析)的SVD方法入手,分析了其处理一词多义和一义多词问题时的不足——通过低秩逼近虽然能降维去噪,但缺乏严谨的统计基础且计算耗时。由此自然引入Hofmann提出的PLSA模型。 PLSA采用概率图模型重新表述文档生成过程:先以一定概率选中文档,再从中抽取主题,最后根据主题生成单词。文档和主题都被建模为多项分布,而EM算法则负责估计这些隐含参数。文章不仅推导了PLSA的数学框架,还通过简单的混合Unigram模型与高斯混合模型(GMM)类比,帮助理解EM算法“期望步-最大化步”的迭代精髓。 整个系列其实计划覆盖从PLSA、LDA到各类变形模型(如Twitter LDA、Labeled-LDA等)的演进脉络,这篇作为开篇,扎实地奠定了概率主题模型的基础认知。