设置双核浏览器的浏览模式
这篇讲的是前端开发者长期以来的一个“幻想”——双核浏览器能否智能识别页面技术,自动切换到更适合的内核。作者从一个知乎问题出发,发现不少开发者都期望浏览器能自动处理CSS3兼容性,但现实中多数双核浏览器并无此“智能”。 文章的核心发现在于,虽然自动识别不普遍,但开发者可以主动“告知”浏览器。具体来说,以360安全浏览器6.5版本为例,只需在网页的`
`标签内添加一行``代码,即可强制使用极速(Webkit)内核渲染页面。`content`属性支持`webkit`、`ie-comp`和`ie-stand`三个值,分别对应极速、兼容和IE模式。 作者实测该方法有效,但也指出一个小缺陷:修改代码后需要刷新页面才能生效。文章最后提到搜狗、QQ等浏览器尚未跟进此特性,并呼吁它们支持,以惠及更多用户。这篇短文为开发者提供了一个明确、可操作的兼容性配置方案。JavaScript 中的陷阱
这篇讲的是JavaScript开发中那些因为语言特性而容易“掉坑”的典型场景。作者从JavaScript“弱语言”的灵活与宽松出发,指出了几个开发者常会忽略的陷阱细节。 比如,全局变量的隐式创建并不局限于省略`var`关键字,`var a = b = 0;`这样的连写同样会让`b`意外泄露为全局变量。文章还深入剖析了“变量提升”与“函数提升”机制——你可能以为在函数里使用`alert`会输出外部变量,但实际结果往往是`undefined`,因为该作用域内的变量声明已被提前解析。函数声明也遵循同样的提升规则,甚至允许后面的声明覆盖前面的,导致行为与直觉相悖。 这篇文章的价值在于,它没有泛泛而谈,而是用一连串精准的代码实例,揭示了JavaScript在变量作用域、解析顺序方面的核心机制。它提醒开发者,要写出健壮的代码,就必须理解这些“坑”背后的语言设计逻辑,养成逐一声明变量、手动管理提升作用域的习惯。
程序员眼里IE浏览器是什么样的
这篇讲的是程序员如何用幽默解构曾经的浏览器霸主IE。文章没有做严肃的技术评测,而是收集了一系列广为流传的搞笑图片,从“反射弧有点长”到“如何区分HTML与HTML5”,再到不同浏览器的用户画像,用一个个生动的梗图勾勒出IE在程序员心中的形象——反应慢、兼容性差、总像没睡醒的“学渣”。 这些看似戏谑的调侃,其实精准地指向了IE衰落的核心原因:在Web标准快速演进的时代,它固步自封,更新迟缓。文章以轻松的方式提醒我们,这些笑话不仅是吐槽,更反映了开发者们对一个开放、标准、高性能的Web环境的集体追求。
关于z-index的那些事儿
这篇技术文章从一个经典的CSS谜题切入:如何在不修改HTML结构、不改动z-index与position属性的前提下,让设置了z-index:1的红色span反而堆叠到其他元素之下?作者通过揭晓答案——为父元素添加一个极小的opacity值(如.99)——引出了对z-index工作原理的深度剖析。 文章的核心在于揭示“堆栈上下文”这一关键概念。作者指出,许多开发者误以为z-index只是简单的数值比较,而忽略了它受元素定位(position)和透明度(opacity)等属性的间接影响。当父元素因设置了opacity小于1而创建新的堆栈上下文时,其所有子元素(无论z-index值多高)都会被限制在这个新的层级范围内,无法突破到上层堆栈中。这就是谜题的解法,也是日常开发中z-index“失灵”的常见根因。 文中进一步梳理了在同一个堆栈上下文中,元素从后到前的排列规则:包括负z-index值的定位元素、非定位元素、z-index为auto的定位元素,以及正z-index值的定位元素等。这些细节帮助开发者在构建复杂UI时,能更精准地预测和控制元素的层叠顺序,避免因误解规则而产生的布局困扰。
被边缘化的前端
这篇文章以一句引人深思的断言开篇:前端开发是互联网技术领域中最容易被边缘化的工种。作者从产品开发全链条的视角出发,指出前端往往处于下游环节,难以把握产品走向,甚至常被其他职能人员轻视其价值——“这个做起来不是很简单么”。这种尴尬处境,在大多数非前端专精的公司里尤为明显。 文章的核心观点并非一味悲观,而是借“堂主”之口敲响警钟:随着信息呈现媒介从浏览器向多端扩展,前端的传统舞台面临萎缩风险。作者犀利地指出,前端角色的可替代性恰恰源于其与产品核心逻辑的距离。文中列举了前端在合作中被忽视、工作量被他人估算等具体现象,生动地刻画了职业困境。 真正的启发在于文末的呼吁:前端工程师需要打破“拒绝陌生领域”的本能。文章建议,与其固守即将被稀释的阵地,不如主动向后端、架构或产品方向延伸能力边界。作者认为,这种危机感并非制造焦虑,而是对抗边缘化的必要清醒——毕竟,在技术世界里,角色的边界从来不是固定的。
使用SeaJS实现模块化JavaScript开发
这篇文章通过一个Web应用“TinyApp”的具体开发场景,清晰地对比了传统JavaScript开发与使用SeaJS进行模块化开发的差异。作者指出,传统模式下随着文件增多,开发者需要手动维护繁琐的script标签列表和复杂的模块依赖顺序,极易导致代码纠缠与维护困难。 而SeaJS作为一个遵循CommonJS规范的轻量级模块加载框架,其核心在于“一切皆模块”的理念。文章展示了在SeaJS模式下,HTML页面只需引入一个sea.js,所有模块依赖都通过模块内部的`require`声明并由框架自动处理。这使得代码组织清晰,开发者可以专注于业务逻辑本身,不必再被依赖管理所累。 此外,文章还深入讲解了SeaJS的实践细节,包括如何使用`define`函数定义模块,以及工厂函数中`require`、`exports`和`module`这三个关键参数的作用。作者强调SeaJS秉持KISS原则,API简洁,能够与jQuery等主流框架无缝集成,从而提升前端工程的代码可维护性。
我的博客系统折腾手记暨papery正式发布
作者为了根治自己的代码洁癖,将一个最初用几个零散 Node.js 脚本搭建、丑陋且通用性差的个人博客系统,彻底重构为名为 papery 的通用博客生成器。这个过程源于微博上朋友们的询问,促使他花了一个周末集中解决积累已久的痛点。 重构的核心方案是明确区分通用与特化功能,并引入现代化开发体验:通过 npm 实现一键安装和升级;用 EJS 模板引擎替代手工 HTML 拼接;采用 YAML 作为更简洁的配置文件格式;新增命令行工具以一键创建博客并启动本地调试服务器。作者还充分利用了 Node.js 社区的成熟组件(如 js-yaml, connect 等),避免重复造轮子,最终目标是让代码变得清晰、优雅且易于扩展。 目前 papery 已开源在 GitHub 和 npm 上,作者自己的博客便是用它生成的。作为一个新项目,它可能尚不完美,但已切实解决了作者的痛点,实现了从“凑合能用”到“清晰好用”的转变。
javascript继承机制
这篇讲的是 JavaScript 中实现继承的两种经典机制:构造函数继承与原型继承。作者从具体的代码示例出发,清晰地展示了 `Animal.apply(this, arguments)` 这种构造函数继承如何复用父类构造函数中的属性,同时点明了它无法继承原型方法的局限性。 文章的核心在于对比。它指出,如果使用 `class.prototype = new parent_class()` 的原型继承方式,则能同时继承父类构造函数和原型上的属性与方法。此外,文章还细致地区分了 `call` 与 `apply` 在传参方式上的不同,并通过反例(如在构造函数内使用 `this.prototype`)强调了原型继承的正确写法。 最后,作者给出了一个精炼的总结:根据是否需要继承原型方法来选择继承方式——若只需构造函数内的成员,用 `apply/call`;若需要原型链上的完整继承,则用原型赋值。这种对比式的讲解,帮助开发者快速理解不同继承模式的核心差异与适用场景。
JQuery,Extjs,YUI,Prototype,Dojo 等JS框架的区别和应用场景简述
这篇从Web2.0时代JavaScript的角色演变谈起,指出在敏捷开发中借助JS框架是效率与深度的双赢,并重点对比了几大主流框架的特性与适用场景。 作者将JQuery评为首推的五星级框架,理由在于其体积小巧、学习曲线平缓、强大的DOM操作与灵活的UI扩展性。Extjs和YUI则凭借出色的UI组件,更适配后台管理系统或网盘这类复杂交互的应用。Dojo功能最为全面,尤其适合需要离线存储、数据网格等企业级特性的产品,但代价是庞大的体积和陡峭的学习成本。Mootools则以其纯正的面向对象设计和低耦合的模块化见长。 文章的核心观点是:没有“最好”的框架,只有“最适合”的选择。开发者应依据项目实际需求来决策,如果感到迷茫,不妨从最灵活的JQuery入手开始实践。
加载,不只是少一点点
这篇讲的是前端性能优化中的“加载精简”策略,其核心目标是解决页面加载慢、带宽成本高的问题。文章重点剖析了离线存储(Application Cache)这一具体方案。 作者指出,加载精简能通过减少资源加载量来加速首屏,并在一定程度上提升渲染速度。具体实施上,离线存储依赖于manifest文件来划分需要缓存和在线获取的资源,在移动端(如离线APP)应用尤为广泛。文章详细说明了其配置方法、基于版本注释的更新机制,以及监听网络状态实现更智能更新的进阶思路。 然而,文章并未止步于优点。它坦诚地揭示了离线存储的“残缺美”:更新时全量下载导致效率低下,manifest文件可能因资源列表庞大而变得臃肿,以及无法很好处理同一页面的不同参数URL等问题。 因此,作者的结论非常务实:寻找适合项目自身阶段(如初期侧重SEO)和性质的方法至关重要,而非盲目采用。离线存储虽能有效“加速”,但其使用需要权衡其利弊与实际场景需求。
JavaScript 设置浏览器标题闪动
这篇文章讲的是一个简单却实用的前端交互技巧:如何让浏览器标签页的标题闪动,从而在用户不看页面时也能有效提醒他们有新消息或内容更新。 作者直接给出了一个名为 `BlinkTitle` 的 JavaScript 类来实现这一功能。核心思路非常清晰:通过 `setInterval` 定时器,让 `document.title` 在一个新标题(如“新消息!”)和原始标题之间来回切换,制造视觉上的闪烁效果。代码实现中巧妙地做了备份和恢复,用户点击“停止”后,标题能立刻恢复原样。 这种方法不依赖任何库,代码轻量,非常适合嵌入到需要实时提醒的网页应用中,比如在线客服系统、后台管理界面或者任何使用 Ajax 长轮询的页面。当用户切换到其他标签页工作时,这个闪动的标题就能成为一个不容忽视的提醒信号。
如何成为一名优秀的web前端工程师(前端攻城师)?
作者开篇指出一个常见现象:许多前端程序员要么不断追问“如何学习”,要么轻视前端“就那么一点东西”,却很少有人思考如何成为一名优秀乃至卓越的前端工程师。 这篇文章系统剖析了这个职业。它首先厘清了前端工程师的核心技能栈——HTML、CSS与JavaScript,但强调其知识体系远不止于此,还需涵盖性能优化、SEO、服务器端基础以及各种辅助工具与架构理念。作者坦言前端入门快但精通难,学习曲线是“先快后慢”,许多从业者易停留在“会用”的阶段,而琐碎的知识点和快速迭代的技术更增加了系统化成长的难度。 文章的精华在于明确了优秀前端工程师的必备特质:既要具备知识的广度与深度,以应对从基础编码到复杂架构的全链条挑战;又必须拥有极快的学习速度,以跟上Web技术日新月异的变化。此外,沟通能力被提升到关键位置,因为前端工程师需要与产品经理、UI设计师、项目经理及最终用户等多方有效协作。文中引用了Yahoo工程师Nicholas C. Zakas的观点,称前端是计算机科学中最复杂的工种之一。 最后,作者推荐了一份从入门到精通的JavaScript书单,如《JavaScript高级程序设计》、《JavaScript权威指南》以及《JavaScript Patterns》等,并指出要成为真正的优秀者,还需深入研究高性能网站构建、HTML5/CSS3乃至后端语言,道路虽艰辛,但方向清晰。
Javascript触屏手势库-jTouch
这篇讲的是作者因项目代码混乱而受刺激,在业余时间封装的一个触屏手势库——jTouch。它专注于为触屏浏览器提供一套完整的手势识别方案。 文章开篇就坦诚地分享了作者的创作动机,那种对整洁代码的追求很能引起开发者共鸣。jTouch目前主要针对iPad测试,支持tap(单击)、doubletap(双击)、longtap(长按)、hold(拖拽)、swipe(滑动)、flip(轻拂)、pinch(捏合)和rotate(旋转)这八种核心手势。 作者没有停留在功能列表,而是详细说明了每个手势回调函数中能获取到的关键数据。比如,swipe和flip会返回方向(direction)和移动距离(x, y);pinch会返回缩放类型(in/out)和比例(scale);rotate则会返回方向和旋转角度(rotation)。这些细节对于开发者在回调中实现具体交互逻辑至关重要。 文章还提供了链式调用的简洁语法示例,并附带了几个生动的在线演示,包括一个触摸平滑移动的轮播效果,以及一个模拟iPad图标长按抖动、双击复位的界面。这些示例直观展示了库的实用性,也为想实现类似效果的开发者提供了直接的参考思路。
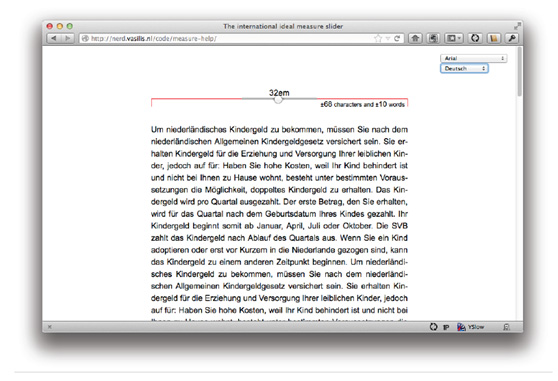
合理设置响应式设计的响应点【译】
这篇讲的是如何为响应式设计设置合理的“响应点”。传统的做法要么依据流行设备尺寸,要么在布局“被打破”时才调整,但作者认为这缺乏根本依据。他主张回归内容可读性的经典理论:当一行文字的长度偏离了便于阅读的范围(如45至75个字符)时,就是设置响应点的合理时机。 作者进一步考虑了语言、字体等实际因素。他举例说,同样是10个单词,用Verdana字体的德语宽度是38.5ems,而用Georgia字体的英语只有22ems,差异巨大。因此,响应点必须根据具体内容来定义,而不是一个固定数值。 在实践中,文章演示了从一个小屏开始的过程:默认使用16px字号,确保内容区宽度不小于45字符。当屏幕宽度增加,内容区超过这个最佳范围时,就引入第二栏、第三栏,通过媒体查询改变布局。所有这些变化都是基于`em`单位计算,使得布局能弹性适应字体大小的变化。 文章的最终结论是,一个健壮的响应式设计应当从内容出发,优先定义默认样式,然后让布局随着内容的“舒适度”自然生长,而不是生硬地适配某个具体的设备或尺寸。这种方法更具逻辑性,也更能适应未来的屏幕变化。
使用渐进式JPEG来提升用户体验
这篇讲的是JPEG图片两种常见的存储方式之间的对比:标准型(Baseline)和渐进式(Progressive)。二者图像数据完全相同,核心区别在于解码显示的方式:标准型如同从上到下逐行扫描,图片一行行清晰显现;而渐进式则包含多次扫描,加载时会先呈现一个模糊的轮廓,随后逐渐变得清晰锐利。 这种差异直接影响用户体验,尤其在网络速度较慢时。渐进式JPEG能让用户在图片完全加载前就大致看到内容,心理上减少等待的焦虑感,这对于图片密集或用户网络环境不稳定的场景是明显的优化。不过,文章也提到,对于采用“瀑布流”布局的网站,传统标准型可能是更稳妥的选择。 另外,渐进式图片的体积并不比标准型大,有时甚至更小,但其解码过程会消耗稍多一点的CPU和内存资源,不过这在当今的设备上通常不成问题。文章的后半部分相当实用,直接给出了在Photoshop、Linux命令行、PHP、Python等多种环境下,如何将一张图片转换为渐进式JPEG的具体代码和命令。
用 javascript 判断 IE 版本号
这篇讲的是如何用一段巧妙的JavaScript代码来准确判断IE的版本号。作者从一个实际项目需求出发,发现jQuery 2.0已放弃版本检测转而推荐特性检测,但面对特定场景,版本号信息依然重要。 文章的核心亮点是分享了一段“以巧破力”的代码。它没有采用常规的解析User-Agent字符串的方法,而是利用了IE浏览器独有的“条件注释”特性。通过动态创建元素并循环写入特定条件注释,代码能够检测出当前IE的精确版本,且对不支持条件注释的现代浏览器能安全地返回`false`,兼容性极佳。 作者也解释了为何要绕开User-Agent检测——那些字符串(比如IE10和IE11的)早已被各厂商修改得杂乱无章,完全不可靠。相比之下,这段利用浏览器原生特性的检测方式,既简洁又稳健,避免了“猜谜”式的判断,为需要区分IE版本的场景提供了一个值得参考的解决方案。
人人都能用的10条网站易用性技巧
这篇译文提炼了WebAIM团队提出的10条提升网站易用性的基础技巧,每一条都直指前端开发中容易忽略的细节。文章不仅列出做法,更点明了其背后的技术原理。 比如,它强调为logo添加alt或title属性,不仅是为了让屏幕阅读器“读懂”图片,在网速不佳图片加载失败时,也能为所有用户保留关键信息。又如,针对许多开发者喜欢移除浏览器默认的:focus焦点样式,文章明确反对这种做法,并给出了如何用自定义高亮样式的代码示例,因为这对键盘操作用户至关重要。 此外,文中还涉及使用ARIA Landmarks帮助读屏软件理解页面结构、用aria-required标记表单必填项、以及避免使用tabindex和“点击此处”这类对辅助技术不友好的模糊链接。作者用平实甚至带点幽默的语言(比如“把设计师的鼠标拿走一天”),将这些看似琐碎却影响深远的实践要点娓娓道来。 这些技巧虽然基础,但共同构成了构建一个包容性更强的Web环境的重要基石。
javascript函数的throttle和debounce
这篇讲的是JavaScript开发中两个常用的性能优化技巧:函数节流(throttle)与函数去抖(debounce)。文章从一个常见的性能优化问题——频繁触发的 `window.resize` 和 `scroll` 事件——切入,形象地将这些持续触发的事件比喻为“机关枪扫射”,而节流就像控制射击频率的扳机。 作者明确指出了两者的核心差异:throttle 是控制函数在连续调用时,按固定时间间隔执行(例如每隔400ms执行一次),适合处理鼠标移动、窗口拖拽等持续触发的场景;而 debounce 则是控制函数在连续调用结束后,必须等待一段指定的空闲时间才执行,特别适用于文本输入、搜索自动补全等场景,能有效过滤掉用户的“快速连续操作”。 文章不仅解释了概念,还提供了原生的 setTimeout 实现思路作为节流示例,并附上了一个通用且实用的函数代码,通过传递参数同时实现了节流和去抖功能。文末提供的在线 Demo 和扩展阅读链接,让读者可以直观体验效果并深入学习。对于前端开发者而言,理解并正确运用这两个技巧,对提升页面交互性能至关重要。
HTML 5 的data-* 自定义属性
HTML5的data-*自定义属性为前端开发提供了一种标准化的数据存储方式。这篇文章从实际用法出发,清晰地对比了传统getAttribute/setAttribute方法与HTML5新增的dataset属性两种存取路径。前者兼容所有浏览器,但和非标准的自定义属性区别不大;后者则通过专属API提供了更简洁的对象式访问,并在属性名包含连字符时(如data-date-of-birth)自动转换为驼峰命名(dateOfBirth),但在部分旧版浏览器中尚未得到支持。 文章指出,data-*属性的更大价值在于其语义化及与CSS选择器、JavaScript的深度结合。开发者可以直接使用`[data-attr]`选择器来精准定位元素,或根据属性值设置样式,这为动态交互和组件化开发带来了便利。总体来看,文章在厘清基本概念的同时,也给出了兼顾兼容性与未来标准的实践建议。
jQuery的data()方法
这篇讲的是jQuery中data()方法如何优雅地管理HTML5的data-*自定义属性。它解决了一个实际问题:如何方便、安全地在DOM元素上绑定和读取各种类型的数据,同时避免循环引用可能导致的内存泄漏。 作者从基本用法切入,展示了四种调用方式,核心优势在于data()会智能处理数据类型——字符串值的"true"会被转为布尔值true,"43"会变成数字43,而符合JSON格式的对象或数组字符串也会被自动解析。这意味着你从HTML属性拿到的不再是笨重的原始字符串,而是可以直接使用的JavaScript值,省去了大量手动转换的代码。 更关键的是它的存储机制:data-*属性在首次读取后,数据便交由jQuery在内部缓存,后续操作都基于这个内存对象。这不仅性能更优,也保证了数据的一致性。需要注意的是,如果你想严格保持字符串形式,就该用attr()方法。 文章用一段简洁的示例演示了这种自动转换的直观效果,比如`$("div").data("options").name`直接就能获取到对象属性,非常适合需要在HTML标签上轻量级配置复杂参数的场景。