JVM垃圾收集器
这篇讲的是JVM中垃圾收集器的原理与选型。作者从垃圾收集是算法的具体实现出发,系统梳理了JDK 1.6时代的六种主流收集器。 文章的核心在于对比。它首先指出没有万能收集器,只有最合适的。Serial作为单线程基础款,适合客户端;ParNew是其多线程升级版,主要为了配合CMS;Parallel Scavenge则专注于吞吐量,适合后台计算任务。在老年代,Serial Old是单线程整理,Parallel Old实现了多线程整理以贯彻高吞吐思路。 重点落在两种并发收集器上。CMS以最短停顿为目标,通过并发标记清除实现,但面临CPU敏感、浮动垃圾和空间碎片问题。G1则带来了革命性改进:基于标记-整理,不产生碎片;通过将堆划分为多个Region并优先回收垃圾最多的区域,实现了可预测的、精确的停顿时间控制。 文章结合图示,清晰地展示了各收集器的适用年代、组合方式以及从Serial到G1,用户线程停顿时间不断缩短的发展脉络,为理解JVM内存管理提供了扎实的入门图景。
Servlet线程安全问题
这篇讲的是开发中容易踩到的陷阱:Servlet的线程安全问题。文章从Servlet默认的多线程执行模型切入,指出当多个线程并发访问同一个Servlet实例时,如果代码不当,会产生难以复现的bug。 作者用了一个很直观的代码案例:在service方法中使用了一个实例变量PrintWriter。当用户a和b几乎同时请求时,由于线程调度和共享实例变量,用户a的浏览器收到了空白页,而a的信息却错误地显示在了用户b的页面上。文章进而从Java内存模型(JMM)的角度,分析了线程工作内存与主内存的同步延迟,如何导致了这一问题的随机性与危险性。 针对该问题,文章总结了三种解决方案:一是实现SingleThreadModel接口(但已被废弃,且不能解决所有问题);二是使用synchronized关键字同步代码块;最根本的,是避免在Servlet中使用实例变量,将需要的数据作为局部变量处理。这对于理解Web容器如何执行Servlet,以及如何编写可靠的并发代码,都是很好的一课。
Java程序员应该知道的10个eclipse调试技巧
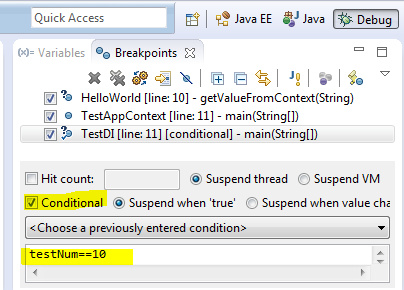
这是一篇面向Java开发者的Eclipse调试技巧系统性梳理。文章开篇就给出了三个高优先级建议:放弃System.out.println,转而启用并分析组件日志。核心内容则围绕十个具体、可操作的调试功能展开。 作者从基础的条件断点、异常断点讲起,逐步深入到监视点、变量值修改等高级操作。特别值得一提的是对“Drop to Frame”(返回堆栈帧)功能的讲解,它能让程序状态“回档”以便重复调试,但作者也提醒了其可能带来的副作用。最后,文章对F5、F6、F7、F8这四个最核心的调试快捷键进行了清晰归类,是入门和巩固的必备知识。 整篇文章的实用性很强,不仅罗列了“是什么”,更通过具体场景说明了“怎么用”以及“注意什么”,旨在帮助开发者更高效、精准地定位代码问题。
java中byte转换int时为何与0xff进行与运算
这篇讲的是Java开发中一个具体但容易踩坑的技术点:将byte数组转换为十六进制字符串时,为何要对每个字节先进行与`0xFF`的按位与运算。 作者直接从代码出发,点出看似多余的`& 0xFF`操作,并设问为何不能简单地将byte强转为int。其核心原因在于Java中byte(8位)与int(32位)的位数差异,以及计算机采用补码表示负数。当一个负数byte(如`-1`,二进制补码为`11111111`)被扩展为int时,会进行符号位填充,得到`0xFFFFFFFF`,这显然不是我们期望的原始字节对应的无符号数值。 与`0xFF`(二进制低8位为1,高24位为0)进行与运算,正是为了清除扩展产生的高位比特,强制将结果限制在低8位内,从而确保得到的是字节的正确无符号值(如`255`)。文章通过复习补码知识和举例说明,清晰地阐释了这一操作的必要性,是理解Java基本数据类型转换细节的一个好示例。
程序员的五个阶段
这篇讲的是程序员职业发展路径中常见的五个阶段,作者从实际工作场景出发,描绘了一幅清晰的进阶地图。 文章首先勾勒出前两个“执行层”阶段:从拿到详尽设计文档、只做编码实现的“编码机器”,到能独立完成模块设计与实现的“独立实现者”。这两个阶段虽然能产出代码,但工作本质上仍是被动的、残缺的。 真正的分水岭出现在第三阶段“项目沟通者和管控者”。此时程序员需主动参与需求澄清、技术难点攻关与项目计划管理,沟通成本急剧上升,其协作能力直接影响团队效率。国内许多公司的工程师正处于这一承上启下的位置。 后两个阶段则标志着思维质变——从“做项目”跃升至“做产品”。这意味着思维重心需从倾听和交付,转向深度思考用户痛点与产品定位,并承担长期的产品维护与迭代。最高阶段“产品成长的见证人”,则描述了参与产品从0到1甚至更迭全过程的完整体验,充满了探索、试错与坚持。 文章的核心观点是:一个完整的程序员不能止步于编码,沟通能力与产品思维是通往更高阶段的关键阶梯。
HTTP协议Keep-Alive模式详解
这篇讲的是HTTP协议中的一个关键性能优化机制——Keep-Alive模式。作者从HTTP“请求-应答”的本质出发,对比了默认断开的普通连接和持久化的Keep-Alive连接。 在普通模式下,每一次请求都要单独建立和关闭TCP连接,开销很大。而启用Keep-Alive后,连接会被重用,避免了重复握手的损耗。文章指出,HTTP 1.0默认关闭此特性,需要手动开启;而从1.1开始,这已是默认行为,服务器是否支持决定了实际效果。 文章的重点分析了Keep-Alive如何判断消息传输完成。由于连接不会自动断开,不能依赖EOF信号。作者详细解释了两种标准方法:一是通过`Content-Length`头部明确告知数据长度;二是使用`Transfer-Encoding: chunked`进行分块编码传输,尤其适用于动态生成的内容。文中甚至给出了chunk编码的具体格式示例。 此外,文章还梳理了RFC标准中消息长度的优先级判定规则,并附录了常见的HTTP头字段解释。可以看出,Keep-Alive并非简单的“保持连接”,而是一套涉及连接复用、数据完整性和协议协商的完整方案,其优势在于节省CPU与内存、支持请求管道化、降低网络拥塞和延迟。理解它,是深入掌握现代HTTP性能调优的基础。
JVM内存分配与回收策略
这篇讲的是JVM中对象内存分配的“潜规则”,作者从最基础的规则出发,通过具体的代码示例和GC日志,带你看清内存分配的真实行为。 文章核心围绕三个关键策略展开:一是对象优先在Eden区分配,当Eden空间不足时就会触发Minor GC;二是大对象会绕过新生代,直接被“安置”在老年代,这可以通过`-XX:PretenureSizeThreshold`参数来控制;三是长期存活的对象会从新生代“晋升”到老年代,其阈值由`-XX:MaxTenuringThreshold`决定。 作者并没有停留在理论描述,而是为每个规则都准备了可运行的代码和对应的GC输出日志。比如,通过对比设置`MaxTenuringThreshold`为1和15时不同的GC结果,你能直观地看到对象年龄计数器如何影响晋升行为。这种用实验数据说话的方式,让这些抽象的内存管理机制变得非常具体和可验证。
JVM垃圾收集算法
这篇系统梳理了JVM垃圾回收中几种核心算法的思路与权衡。文章从最基础的“标记-清除”算法切入,指出了它虽简单却有效率低下与内存碎片两大硬伤。为解决效率,“复制算法”以空间换时间,通过内存分区和存活对象拷贝来运行,但代价是内存减半;不过,结合新生代“98%对象朝生夕死”的特性,现代虚拟机巧妙调整了Eden与Survivor区的比例,将浪费降至10%。 针对老年代对象存活率高、无法浪费空间的场景,“标记-整理”算法则另辟蹊径:标记后让所有存活对象向一端移动,从而整理出连续内存空间。最后,文章点明了当今主流的做法——“分代收集”,它并非新算法,而是根据新生代与老年代的不同特点(对象存活率、空间担保需求等),灵活组合采用上述策略,以达到整体最优的回收效果。整篇文章对比清晰,从算法原理到工程实现,为理解JVM内存管理提供了扎实的脉络。