开发者调试工具Chrome Workspace
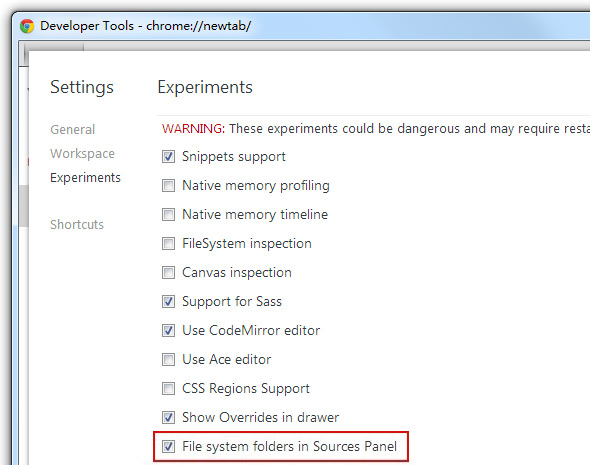
这篇讲的是Chrome开发者工具中一个能直接提升前端调试效率的内置功能:Workspace。 它允许开发者在DevTools里直接修改JS和CSS代码,并且改动会实时、自动地保存回本地文件。这省去了以往“在工具中调试确认效果,再切回编辑器手动同步修改”的重复步骤。过去实现类似自动保存需要依赖第三方工具(如autosave)并手动启动本地服务,现在Chrome正式版已原生支持,流程大大简化。 文章详细说明了启用方法:对于普通Chrome用户,需先在`chrome://flags/`中启用开发者工具实验选项,重启DevTools后在设置的“Experiments”中开启“File system folders in Sources Panel”。出于安全考虑,还需在目标项目根目录下创建一个名为`.allow-devtools-edit`的空文件(文中提供了Windows和Mac的命令行创建方式),然后在Workspace中添加该目录即可开始使用。作者也提醒,若资源通过URL加载,需使用Mappings设置映射,并特别注意路径结尾不要加反斜杠。 最后文章指出,尽管Workspace在调试阶段能有效提效,但其目前并不支持SCSS、LESS等预处理器文件的编辑,这是一个尚待完善的限制。
本机暂存