闲话命名
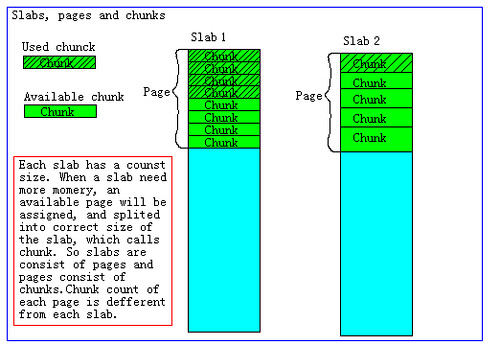
你是否曾因为一个命令参数的顺序而头疼?作者从一个关于`ln`命令参数记忆的简单提问切入,发现命令手册中“target”与“linkname”两个不同参数名的细微差异,竟能显著影响开发者的理解与使用体验。这引出了文章对“命名”这一看似微小却至关重要问题的探讨。 文章指出,命名绝非简单的贴标签,它深刻塑造着我们的认知,并直接影响协作与设计的成败。在软件开发中,如“weight”这样缺乏单位的具体变量名,会导致团队沟通成本激增;而历史上NASA火星探测器的失败,其根源正是单位命名不一致引发的混乱。在产品设计中,不当的本地化命名(如将推荐功能“radar”直译为“雷达”,或在邮件界面将“discard”译为可能引发歧义的“关闭”)也会违背“Don't make me think”的设计原则,为用户制造障碍。 作者进一步通过“骑马螺丝”这一生动形象的民间命名,说明好的命名需要结合语境与巧思,有时源自生活的直觉比喻(如“装电池式睡觉”)反而最贴切。文章最终强调,无论是在代码、产品还是日常生活中,重视并打磨命名,是提升效率、避免灾难、促进理解的必要功课。
本机暂存