背景
Code Review 是大家日常开发过程中很常见的流程,当然也不排除一些团队为了快速上线,只要功能测试没问题就直接省去了 Code Review。
我个人觉得再忙的团队 Code Review 还是很有必要的(甚至可以事后再 Review),好处很多:
- 跳出个人开发的思维误区,更容易发现问题
- 增进团队交流,提高整体的技术氛围
- 团队水平检测器,不管是审核者还是被审核的,review 几次后大概就知道是什么水平了
通常 Code Review 有两种场景,一种是公司内部,还有就是开源社区。
开源社区
先说开源社区,最近也在做 cim 项目里做 Review,同时也在 Pulsar、OpenTelemetry、StarRocks 这些项目里做过 Reviewer。
以下是一些我参与 Code Review 的一些经验:
先提 issue
在提交 PR 进行 Code Review 之前最好先提交一个 issue 和社区讨论下,你的这个改动社区是否接受。
我见过一些事前没有提前沟通,然后提交了一个很复杂的 PR,会导致维护者很难 Review,同时也会打击参与者的积极性。
所以强烈建议一些复杂的修改一定先要提前和社区沟通,除非这是一些十拿九稳的问题。
个人 CI
一些大型项目往往都有完善的 CI 流程来保证代码质量,通常都有以下的校验:
- 各种测试流程(单元测试、集成测试)
- 代码 Code Style 检测
- 安全、依赖检测等
如果一个 PR 连 CI 都没跑过,其实也没有提前 Review 的必要了,所以在提 PR 之前都建议先在自己的 repo 里将主要的 CI 都跑过再提交 PR。
这个在 Pulsar 的官方贡献流程里也有单独提到。
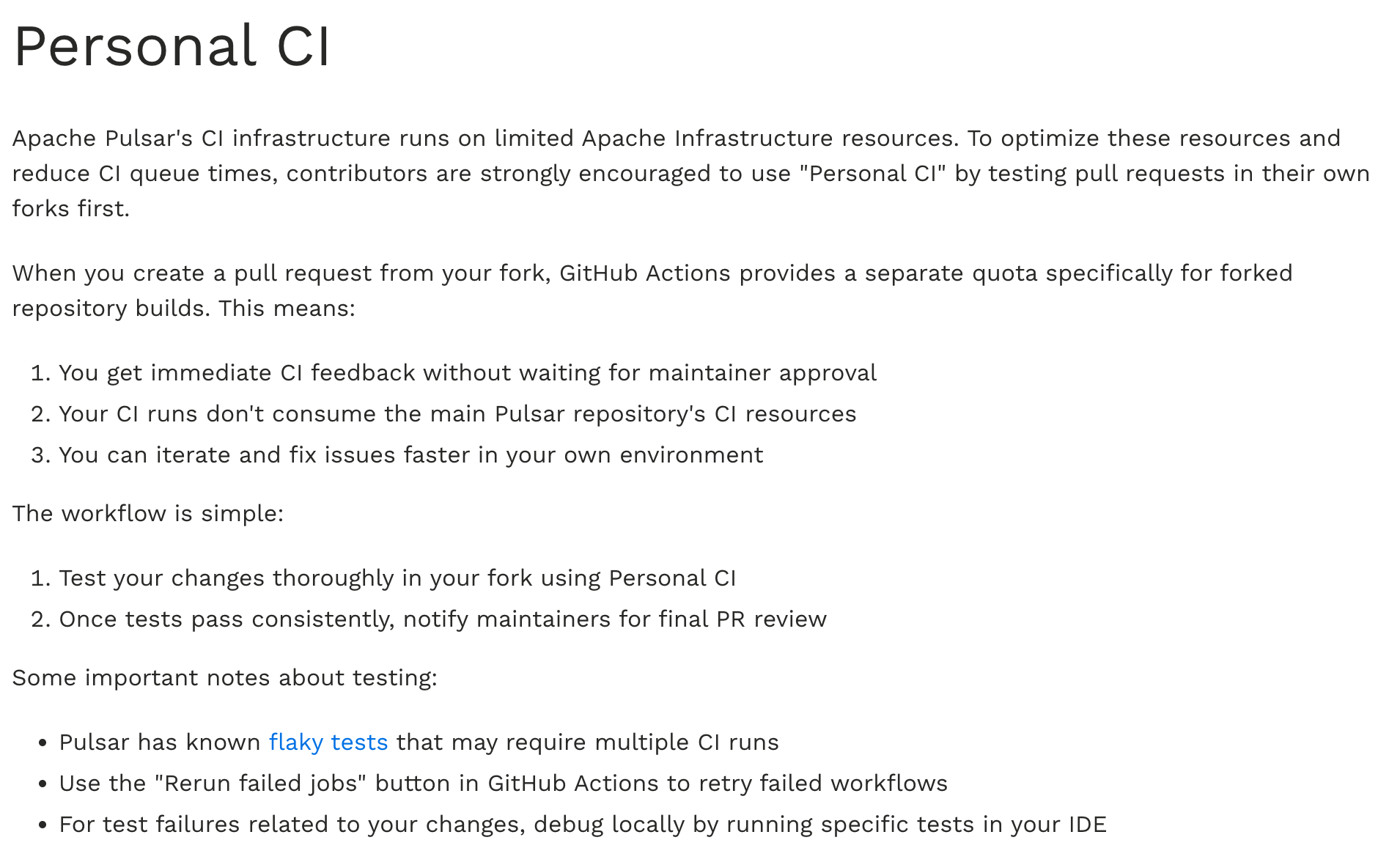
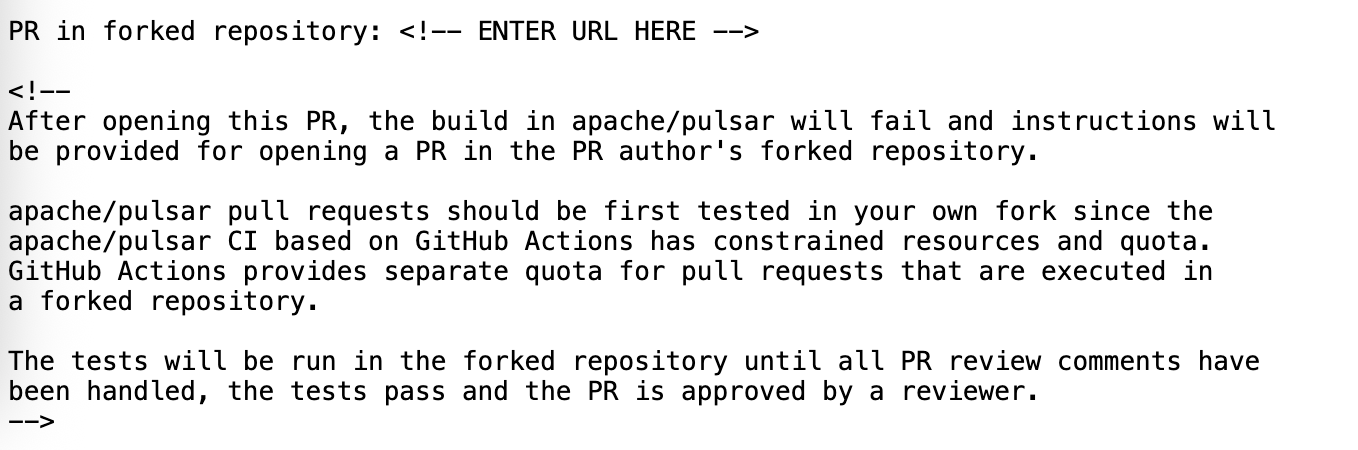
同时在 PR 模板里也有提到,建议先在自己的 fork 的 repo 里完成 CI 之后再提交到 upstream。
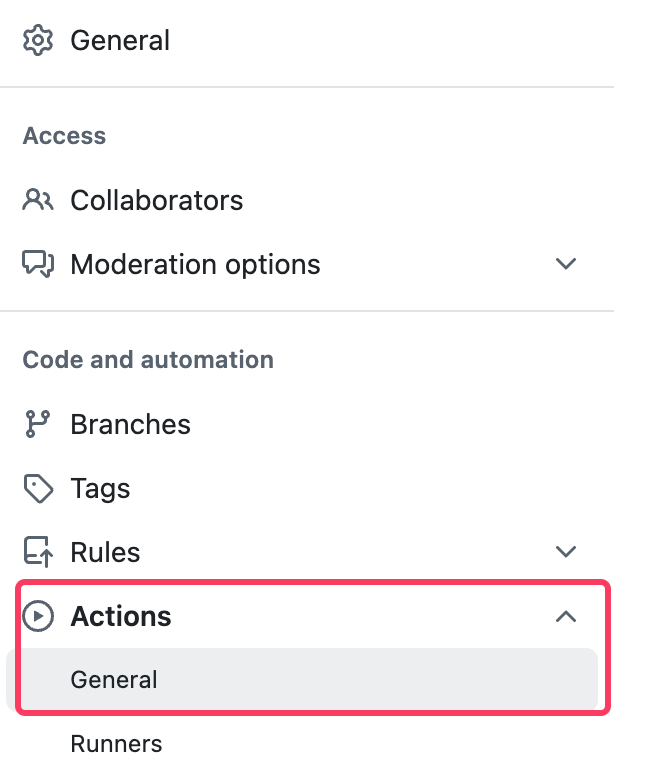
这个其实也很简单,我们只要给自己的 repo 提交一个 PR,然后在 repo 设置中开启 Action,之后就会触发 CI 了。
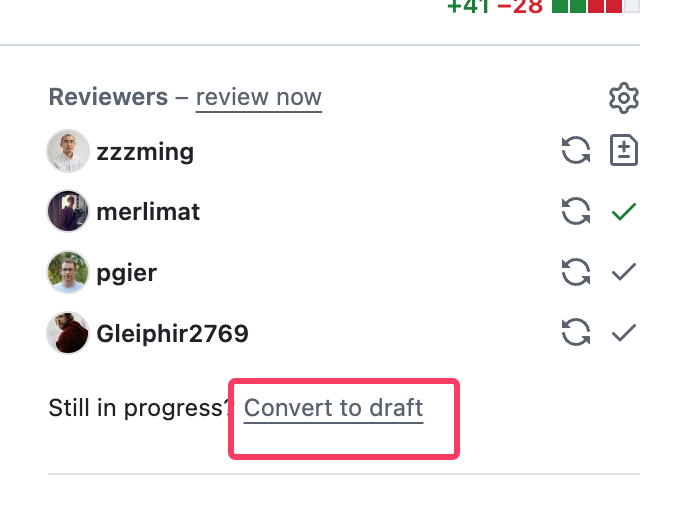
如果自己的 PR 还需要频繁的提交修改,那建议可以先修改为 draft,这样可以提醒维护者稍后再做 Review。
同时也不建议提交一个过大的 PR,尽量控制在 500 行改动以内,这样才方便 Review。
Review 代码

Github 有提供代码对比页面,但也只是简单的代码高亮,没法像 IDE 这样提供函数跳转等功能。

所以对于 Reviewer 来说,最好是在本地 IDE 中添加 PR 的 repo,这样就可以直接切换到 PR 的分支,然后再本地跟代码,也更好调试。
有相关的修改建议可以直接在 github 页面上进行评论,这样两者结合起来 Review,效率会更高。
Review 代码其实不比写代码轻松,所以对免费帮你做 Review 的要多保持一些瑞思拜。
AI Review
现在 Github 已经支持 copilot 自动 Review 了,它可以帮我们总结变更,同时对一些参加的错误提供修改建议。
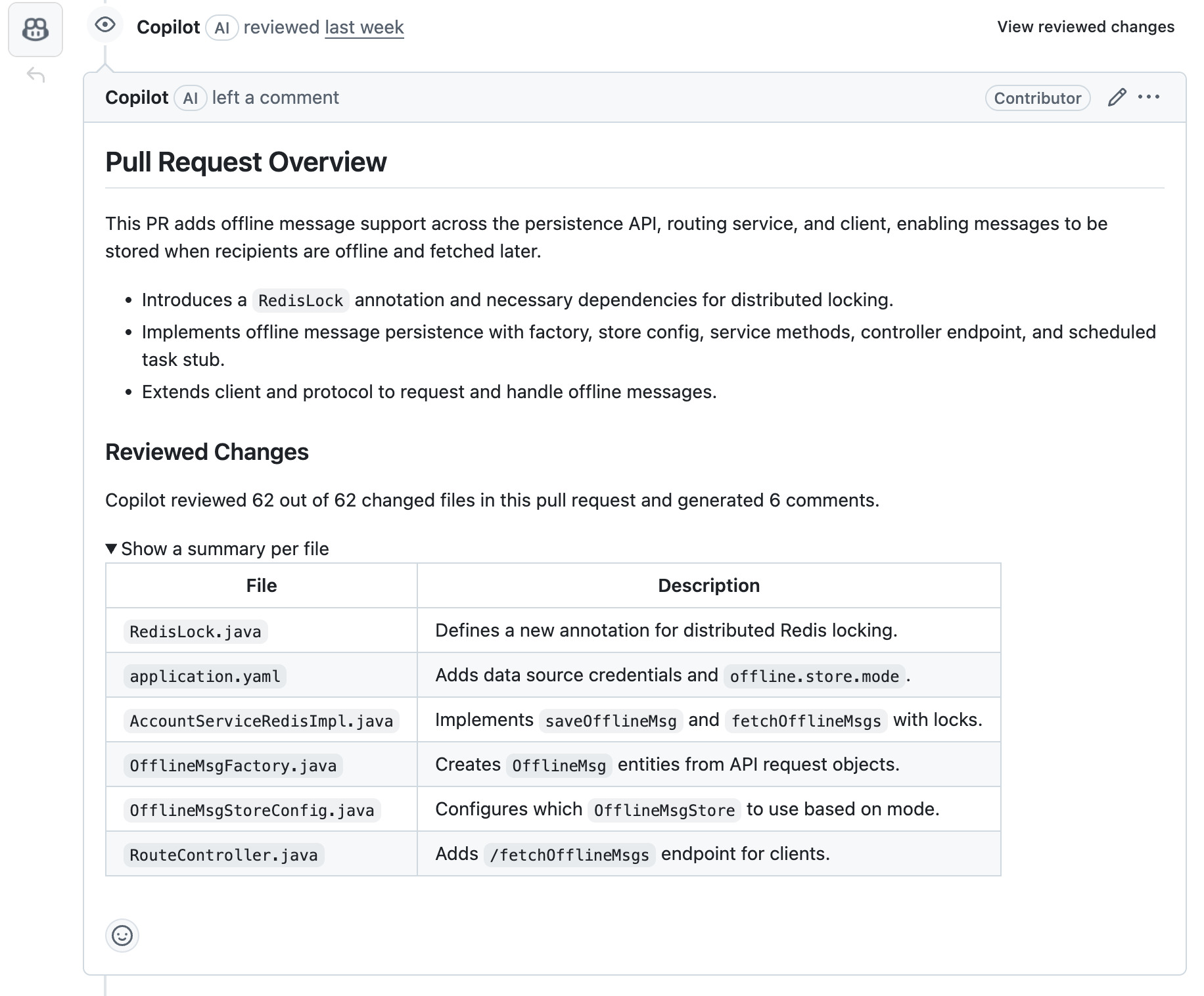
使用它还是可以帮我们省不少事情,推荐开启。
企业内部
在企业内部做 Code Review 流程上要简单许多,毕竟沟通成本要低一些,往往都是达成一致之后才会开始开发,所以重点就是 Review 的过程了。
既然是在公司内部,那就要发挥线下沟通的优势了;当然在开始前还是建议在内部的代码工具里比如说 gitlab 中提交一个 MR,先让参会人员都提前看看大概修改了哪些内容,最好是提前在 gitlab 中评论,带着问题开会讨论。
实际 Review 过程应该尽量关注业务逻辑与设计,而不是代码风格、格式等细枝末节的问题。
提出修改意见的时候也要对事不对人,我见过好几次在 Review 现场吵起来的场景,就是代入了一些主观情绪,被 Review 的觉得自己能力被质疑,从而产生了一些冲突。
Code Review 做得好的话整个团队都会一起进步,对个人来说参与一些优质开源项目的 Code Review 也会学到很多东西。
本机暂存