系统工程师的自我修养- sed篇
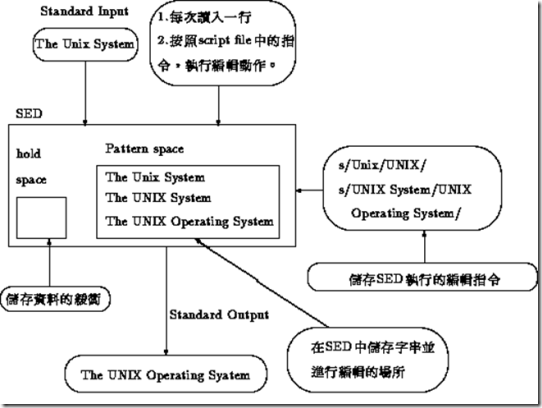
这篇文章系统地梳理了传统UNIX环境下的sed工具,从底层原理讲起,特别强调了其基于pattern space逐行处理的核心机制,与GNU版本做了区分。作者清晰地界定了sed与awk的适用场景:sed长于行内的强大替换与编辑,适合做“文本编辑器”;而awk更擅长列的提取与格式化,是“信息处理器”。 文章没有堆砌所有命令,而是直接从实战出发。在讲解了如何用SELECTION(行号、正则)精确选取目标文本后,通过一系列电话簿、路径、配置文件的示例,演示了打印(-p)、插入(i)、追加(a)和替换(c)这些最常用的操作。作者的讲解紧密结合了sed“读取-处理-输出”的工作流程,比如在解释`-n`选项时,就回溯到默认输出pattern space的原理,让读者知其然更知其所以然。 整体来看,这是一篇不求大而全,但求小而精的实践指南。它把sed的核心骨架和最实用的“几把刷子”清晰地呈现出来,非常适合想要快速掌握sed行处理精髓的系统工程师作为入门和速查参考。
本机暂存