图解微服务架构演进
这篇讲的是随着业务规模扩大,传统单体应用架构如何一步步演进到微服务架构的完整路径。 作者从 Dubbo 用户手册的一句话切入,点明了架构升级的背景:常规垂直应用架构已无法应对互联网发展,服务化改造势在必行。文章核心是梳理了服务化架构的演进阶梯:最初是功能内聚但扩展性差的 **ORM 单体架构**;随后为提升性能,演化出便于前后端分离、加速开发的 **MVC 垂直应用架构**;当应用间交互增多,便抽离核心业务,通过 **RPC 分布式服务框架** 实现复用与整合;随着服务数量激增,需要调度中心进行统一管控,形成了 **SOA 流动计算架构**。 最终,演进到了微服务架构。它的核心思想是将功能进一步拆解为更原子、自治的服务单元进行高密度部署,以实现彻底的解耦。文章也结合敏捷开发、持续交付和容器化(Docker)等趋势,指出微服务是应对复杂度的必然演进方向。整个梳理逻辑清晰,从历史演进的角度为理解微服务提供了一个扎实的上下文。
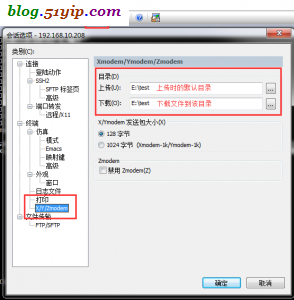
本机暂存