JavaScript原型之路
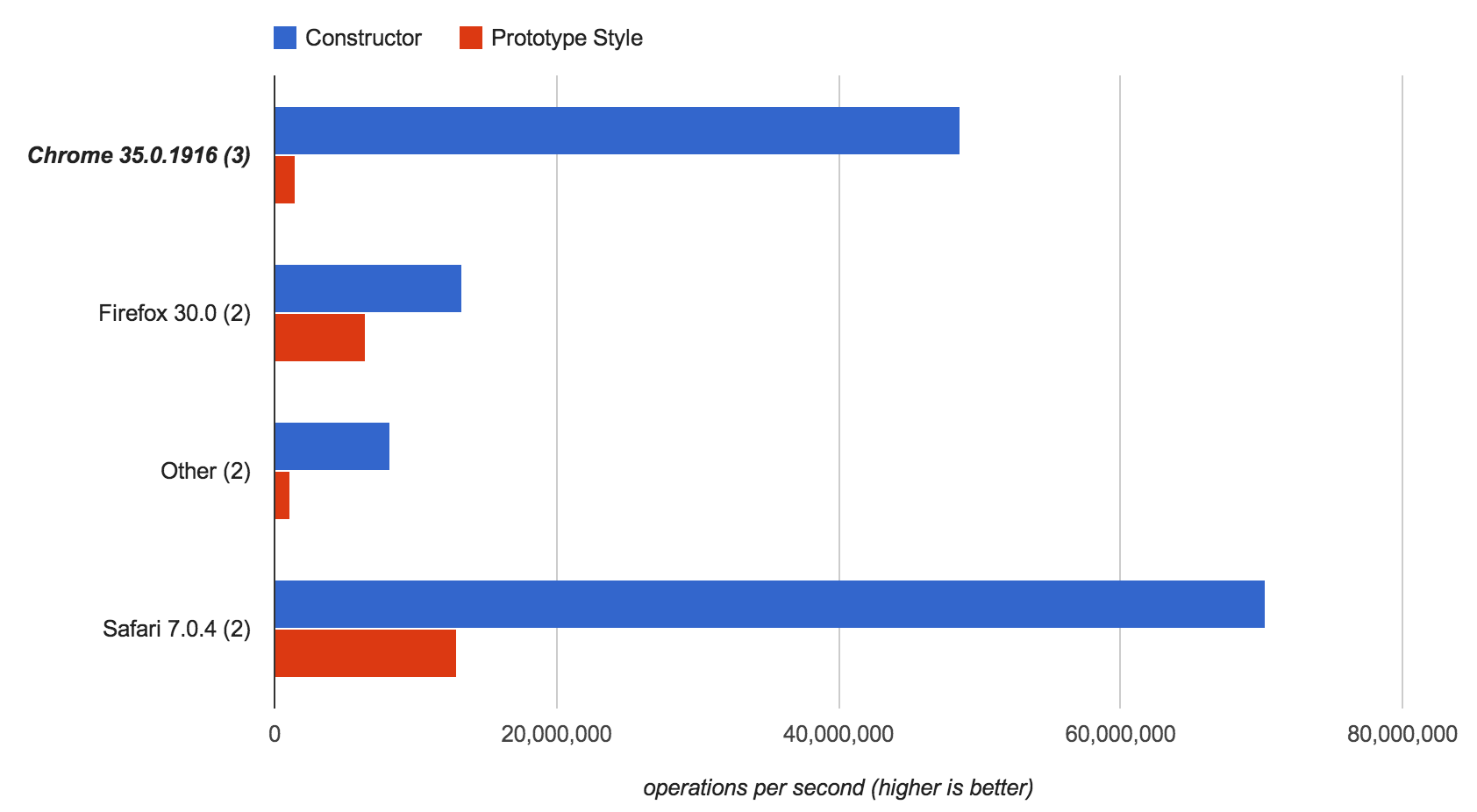
这篇文章探讨了JavaScript中两种对象创建方式的差异与选择:传统的构造函数方法与更纯粹的原型(OLOO)方法。 作者从Frontend Masters的教程和一篇经典博文出发,对比了这两种路径。标准方法通过构造函数和原型链建立继承,是目前大多数教程和框架(如Angular)所要求的。而纯原型方法则利用`Object.create()`直接克隆对象,语法上更接近IO这类原生原型语言,显得更直接和动态。 然而,文章指出一个关键的现实考量:性能。测试显示,纯原型的实现在某些操作上可能比构造函数方式慢数十倍,这是JavaScript引擎优化导致的结果。此外,ES6引入的`class`语法本质上仍是构造函数的语法糖,并未改变原型的底层机制。 作者的结论反映了实践中的权衡:个人偏好纯原型的表现力和趣味性,但在追求性能的生产代码中,会继续采用构造函数方法,并期待未来能更广泛地使用ES6的类语法。
本机暂存