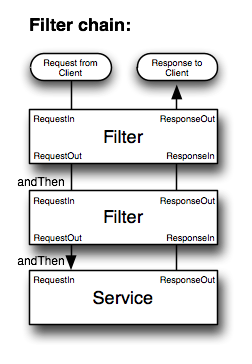
标准化与可复用杂谈
这篇讲的是从一次具体的线上问题排查说起,引申出对软件工程中“标准化”与“可复用”的思考。作者描述了一个典型场景:用户反馈的问题经过层层传递,工程师最后发现是某台服务器在特殊情况下启动了错误版本,导致返回数据异常。这背后暴露的是从代码测试、服务调用到上线发布的全流程中,处处依赖人工细心所潜藏的高风险。 文章的核心观点在于,将全流程中那些不易变的单元(如测试、服务交互规范、发布步骤)进行标准化,并用程序来控制,可以从源头减少低级错误。作者以一个深度使用消息队列但因标准化和抽象不足,导致经验难以复用的团队为例,说明了这一点。同时,文章也对比了国内外对工程师严格要求的差异,指出在业务驱动、快速交付的压力下,形成高质量代码共识与推动标准化建设的不易。 文章的启发在于,它并非空谈架构,而是从运维和开发的共同痛点出发,论证了标准化对于解放工程师精力、提升系统可靠性的实际价值,尤其适合那些正被重复性故障和低效协作困扰的技术团队反思。
本机暂存