Erlang集群全联通问题及解决方案
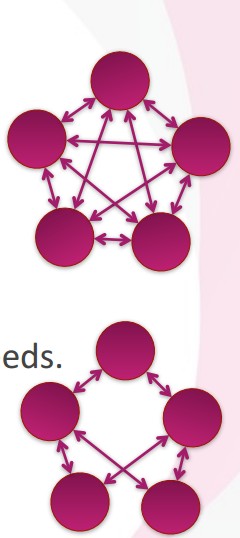
这篇讲的是Erlang集群一个看似“贴心”但可能致命的设计:默认全联通。 作者从Erlang集群节点加入时的“引荐”机制讲起,新节点会被介绍给所有现有节点,从而建立一个完全连接的网状拓扑。问题在于,这种全联通连接数(N*(N-1)/2)会随节点数增加而爆炸式增长,不仅消耗大量系统资源,更因定期的心跳检测引发网络风暴,严重制约集群规模。 解决这个问题的方案出人意料地简单:在节点启动参数中加入“-hidden”标志,使其成为“隐藏节点”。如此一来,节点间的连接不会被主动发布,从而有效避免了不必要的全联通。 不过,作者特别提醒了一个关键细节:隐藏节点的行为是“或”逻辑——只要通信双方中有一方是隐藏节点,global模块就不会进行自动引荐。这个特性在实际部署和故障排查时必须留意。文章最后指出,社区已开始正视并规避这一设计带来的问题,对从事大规模分布式Erlang开发的工程师来说,这个经验颇具价值。