git submodule 与 subtree 的异同
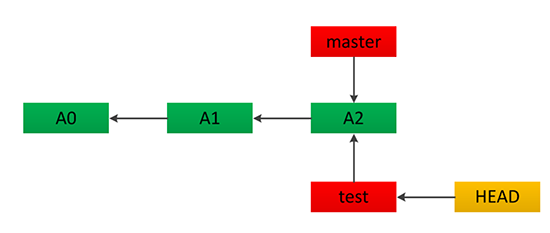
最近有开发者在整理代码仓库、尝试将代码与数据分离时,借助 `filter-repo` 等工具,引发了关于究竟该用 `git submodule` 还是 `git subtree` 的思考。这篇文章就深入对比了这两个看似功能相似、实则内核与适用场景迥异的 Git 功能。 两者最核心的差异在于代码的“存在形式”。`submodule` 像是一个精确的指针,它只在你的主仓库中记录一个指向特定子仓库提交的链接。因此,主仓库保持精简,但每次克隆或拉取后,你都需要额外执行 `git submodule init` 和 `update` 来同步子模块内容,管理上更为“显式”。 相反,`subtree` 则采用“拿来主义”,它将子仓库的代码内容直接合并到主仓库的指定目录下,代码成为主仓库历史的一部分。你无需额外步骤就能看到并编辑全部代码,操作更直接,但代价是主仓库的历史记录会膨胀,且后续同步上游更新时可能产生更复杂的合并。 这种差异直接决定了它们的适用场景。如果你的子项目是清晰分离、需要独立版本管理且上游更新频繁的组件(例如共享库),`submodule` 提供了干净的隔离。若你只是希望将某个外部项目的某次快照代码嵌入你的项目,或对代码的便捷访问和单一仓库管理的需求高于历史清洁度,那么 `subtree` 的“一体化”方案会更简单省心。文章通过一个真实的代码整理场景,清晰地剖析了这两种方案的优劣与选择依据,能帮助开发者在项目管理和代码组织时做出更合适的决策。