Linux下的CPU使用率与服务器负载的关系与区别
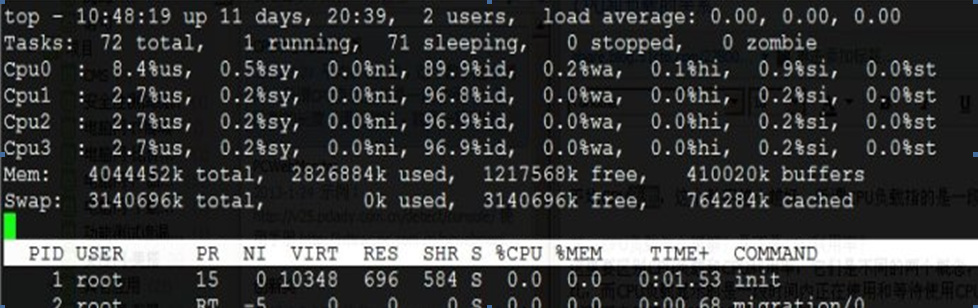
这篇技术文章深入辨析了Linux系统中CPU使用率与服务器负载这一经典混淆点。作者从top命令显示的load average切入,明确指出负载并非使用率,而是CPU任务队列长度的统计——它反映了正在处理以及等待处理的任务数之和。 关键差异在于:CPU使用率衡量的是程序实时占用CPU的百分比,而负载则体现了一段时间内任务的拥挤程度。文章用了一个生动的打电话比喻来阐明:电话(CPU)被一人独占时使用率100%但负载仅为1,若四人排队等待则负载升至4。这形象地说明高使用率不一定意味着高负载,反之亦然。 文章进一步探讨了理想状态:一般认为每个CPU内核的负载在0.7左右较为健康,因此一个4核服务器的总负载在3.0以下即可接受。对于降低负载,作者指出最根本的方法是升级硬件(如增加CPU核心数),因为负载本质上与内核数挂钩。同时,文中也提到传统上使用率60-80%常被视为瓶颈,但更应结合负载综合评估。 通过对比概念、提供具体阈值并辅以贴切比喻,这篇文章帮助运维人员更精准地解读系统指标,避免将负载高简单等同于CPU繁忙,从而做出更合理的优化决策。