告别死锁和陈旧语法、告别性能瓶颈:三个开源 Skill,新手Gopher 秒变 Go 语言大神
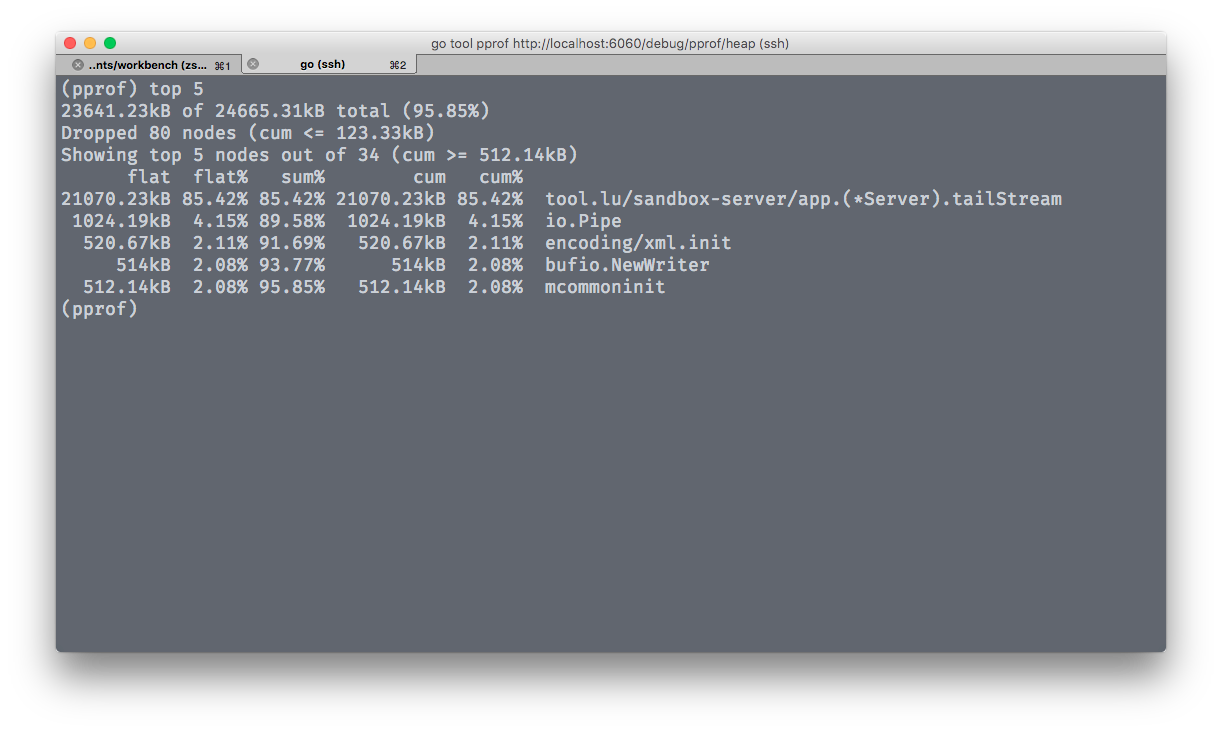
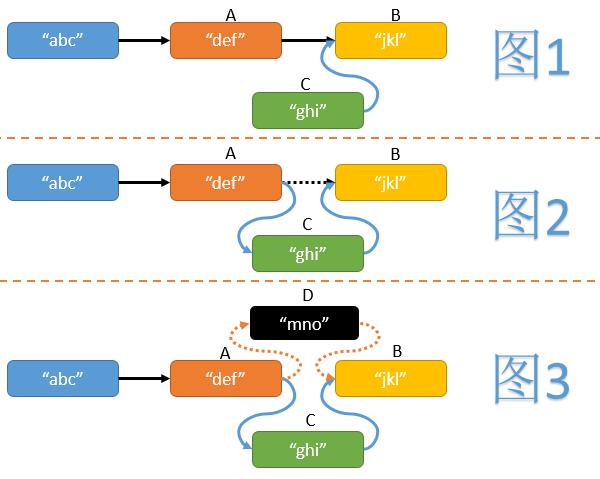
文章聚焦Go语言开发者面临的三大核心挑战:并发死锁与数据竞争、性能瓶颈分析、代码语法现代化。针对并发问题,介绍AI Skill chao-go-sync,它整合并发编程知识,能诊断潜在竞态条件、锁竞争等bug,并推荐如RWMutex或WaitGroup.Go等优化方案。针对性能问题,chao-go-perf Skill提供数据驱动分析,指导基准测试编写、逃逸分析解读、CPU缓存优化及版本感知的性能改进。针对代码现代化,modern-go Skill基于go.mod版本自动应用28种语法转换规则,如将interface{}替换为any、使用slices.SortFunc等,确保代码符合最新Go惯用法。这些Skill嵌入AI编码助手后,可实时辅助开发者:例如分析项目并发缺陷时,提供详细报告和修复建议;检查性能问题时,指出热点函数和内存分配;升级旧代码时,自动执行转换并输出变更总结。文章通过实际案例演示Skill功能,并给出安装命令,强调这些开源工具如何降低Go开发门槛,提升效率与代码质量。