本文已经首发于InfoQ中文站,版权所有,原文为《解读NoSQL技术代表之作Dynamo》,如需转载,请务必附带本声明,谢谢。
InfoQ中文站是一个面向中高端技术人员的在线独立社区,为Java、.NET、Ruby、SOA、敏捷、架构等领域提供及时而有深度的资讯、高端技术大会如QCon、免费迷你书下载如《架构师》等。
NoSQL在过去的一年里,逐渐已经成为了家喻户晓的东西,我(54chen)自从去年开始人人网的NoSQL系统Nuclear的研发以来,一直看着NoSQL越来越热,越来越引来大家的围观。受infoQ霍师傅之托,特作此文,一来作过去一年的总结,二来希望以平白的话语对NoSQL系统在国内的发展献绵薄之力。
1.我眼中的两种模式
NoSQL其实并不是什么妖魔鬼怪,相反的,NoSQL的真谛其实应该是Not Only SQL,其产生是在数据量和访问量的增大下,人为地去添加机器、切分数据到不同的机器,变得越来越困难,人力成本越来越高,于是便开始有了这样的项目,本意是提高数据存储的自动化程度,减少人为干预的时间,让负载更加均匀。在国际上,真正的代表之作有来自Google的 BigTable 和Amazon 的Dynamo,他们分别使用了不同的基本原理。
1.1 MapReduce
这是历史最久的一种模型,典型的代表是BigTable。Map表示映射,Reduce表示化简。MapReduce通过把对数据集的大规模操作分发给网络上的每个节点实现可靠性(Map);每个节点会周期性的把完成的工作和状态的更新报告回来(Reduce)。大多数分布式运算可以抽象为MapReduce操作。Map是把输入Input分解成中间的Key/Value对,Reduce把Key/Value合成最终输出Output。这两个函数由程序员提供给系统,下层设施把Map和Reduce操作分布在集群上运行。
1.2 dynamo
我把dynamo专门归纳成为了一种,的确是这样的,它与MapReduce不同,自成一派。来说历史,Amazon于2006年推出了自己的云存储服务S3,2007年其CTO公布了S3的设计方案,从此江湖中就不再太平了,开源项目一个个如雨后春笋般地出现了。比较常见的有facebook开发的Cassandra(如果没有记错,在去年来到他们的项目网页的时候,上面还写着他们之中的一个开发人员是dynamo的设计人员,现在风头紧了,去掉了),还有linkedin的voldemort,国内的话,有豆瓣网的beansDB,人人网的nuclear等等。这次主要讲的也是dynamo的方案细节。
2.入门基础
Dynamo的意思是发电机,的确,这一整套的方案都像发电机一样,源源不断地提供服务,永不间断。以下内容看上去有点教条,但基本上要理解原理,这每一项都是必须知道的。
2.1 CAP原则
先来看历史,Eric A. Brewer教授,Inktomi公司的创始人,berkeley大学的计算机教授,Inktomi是雅虎搜索现在的台端技术核心支持。最主要的是,他们(Inktomi公司)在最早的时间里,开始研究分布计算。CAP原则的提出,可以追溯到2000年的时候(可以想象有多么早!),Brewer教授在一次talk中,基于他运作inktomi与在伯克利大学里的经验,总结出了CAP原则(后附当年的slide)。图2.1来自Brewer教授当年所画的图:

图2.1
Consistency(一致性),数据一致性,简单的说,就是数据复制到了N台机器,如果有更新,要N机器的数据是一起更新的。
Availability(可用性),好的响应性能,此项意思主要就是速度。
Partition tolerance(分区容错性),这里是说好的分区方法,体现具体一点,简单地可理解为是节点的可扩展性。
定理:任何分布式系统只可同时满足二点,没法三者兼顾。
忠告:架构师不要将精力浪费在如何设计能满足三者的完美分布式系统,而是应该进行取舍。
2.2 DHT
DHT(Distributed Hash Table,分布式哈希表),它是一种分布式存储寻址方法的统称。就像普通的哈希表,里面保存了key与value的对应关系,一般都能根据一个key去对应到相应的节点,从而得到相对应的value。
这里随带一提,在DHT算法中,一致性哈希作为第一个实用的算法,在大多数系统中都使用了它。一致性哈希基本解决了在P2P环境中最为关键的问题――如何在动态的网络拓扑中分布存储和路由。每个节点仅需维护少量相邻节点的信息,并且在节点加入/退出系统时,仅有相关的少量节点参与到拓扑的维护中。至于一致性哗然的细节就不在这里详细说了,要指明的一点是,在Dynamo的数据分区方式之后,其实内部已然是一个对一致性哈希的改造了。
3.进入Dynamo的世界
有了上面一章里的两个基础介绍之后,我们开始进入Dynamo的世界。
3.1 Dynamo的数据分区与作用
在Dynamo的实现中提到一个关键的东西,就是数据分区。
假设我们的数据的 key 的范围是0到2的64次方(不用怀疑你的数据量会超过它,正常甚至变态情况下你都是超不过的,甚至像伏地魔等其他类Dynamo系统是使用的2^31-1),然后设置一个常数,比如说1000,将我们的key的范围分成1000份。然后再将这1000份key的范围均匀分配到所有的节点(s个节点),这样每个节点负责的分区数就是1000/s份分区。
如图3.1,假设我们有A、B、C三台机器,然后将我们的分区定义了12个。
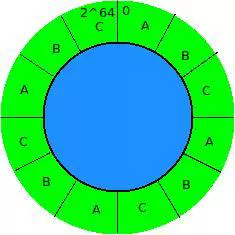
图3.1
因为数据是均匀离散到这个环上的(有人开始会认为数据的key是从1、2、3、4。。。这样子一直下去的,其实不是的,哈希计算出来的值,都是一个离散的结果),所以我们每个分区的数据量是大致相等的。从图上我们可以得出,每台机器都分到了三个分区里的数据,并且因为分区是均匀的,在分区数量是相当大的时候,数据的分布会更加的均匀,与此同时,负载也被均匀地分开了(当然了,如果硬要说你的负载还是只集中在一个分区里,那不是这里讨论的问题了,有可能是你的哈希函数是不是有什么样的问题了)。
为什么要进行这样的分布呢,分布的好处在于,在有新机器加入的时候,只需要替换原有分区即可,如图3.2所示:
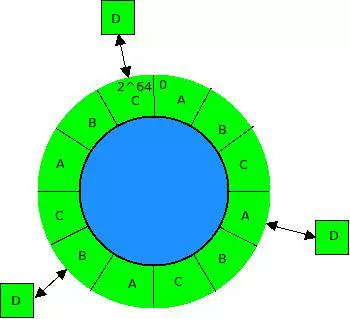
图3.2
同样是图3.1里的情况,12个分区分到ABC三个节点,图3.2中就是再进入了一个新的节点D,从图上的重新分布情况可以得出,所有节点里只需要转移四分之一的数据到新来的节点即可,同时,新节点的负载也伴随分区的转移而转移了(这里的12个分区太少了,如果是1200个分区甚至是12000个分区的话,这个结论就是正确的了,12个分区只为演示用)
3.2 从Dynamo的NRW看CAP法则
在Dynamo系统中,第一次提出来了NRW的方法。
N - 复制的次数
R - 读数据的最小节点数
W - 写成功的最小分区数
这三个数的具体作用呢,是用来灵活地调整Dynamo系统的可用性与一致性的。
举个例子来说,如果R=1的话,表示最少只需要去一个节点读数据即可,读到即返回,这时是可用性是很高的,但并不能保证数据的一致性,如果说W同时为1的话,那可用性更新是最高的一种情况,但这时完全不能保障数据的一致性,因为在可供复制的N个节点里,只需要写成功一次的话就返回了,也就意味着,有可能在读的这一次并没有真正读到需要的数据(一致性相当的不好)。如果W=R=N=3的话,也就是说,每次写的时候,都保证所有要复制的点都写成功,读的时候也是都读到,这样子一定读出来的数据是正确的,但是这中间的性能大打折扣,也就是说,数据的一致性非常的高,但系统的可用性却非常低了。如果R + W > N能够保证我们“读我们所写”,Dynamo推荐使用322的组合使用可。
Dynamo系统的数据分区让整个网络的可扩展性其实是一个固定值(你分了多少区,实际上网络里扩展节点的上限就是这个数),通过NRW来达到另外两个方向上的调整。
3.3 Dynamo的一些增加可用性的补救
针对一些经常可能出现的问题,Dynamo还提供了一些解决的方法。
第一个是hinted handoff数据的加入:在一个节点出现临时性故障时,数据会自动进入列表中的下一个节点进行写操作,并标记为handoff数据,在收到通知原节点恢复时重新把数据推回去。这能使系统的写入成功大大提升。
第二个是向量时钟来做版本控制:用一个向量(比如说[a,1]表示这个数据在a节点第一次写入)来标记数据的版本,这样在有版本冲突的时候,可以追溯到出现问题的地方。这可以使数据的最终一致成为可能。?assandra未用vector clock, 而只用client timestamps也达到了同样效果。)
第三个是Merkle tree来提速数据变动时的查找:使用Merkle tree为数据建立索引,只要任意数据有变动,都将快速反馈出来。
第四个是Gossip协议:一种通讯协议,目标是让节点与节点之间通信,省略中心节点的存在,使网络达到去中心化。提高系统的可用性。
关于作者
54chen(陈臻),人人网分布式存储研究人员,业余时间混迹于各技术组织且乐此不疲。目前关注实施PHP培训。对flex等前端技术有一点研究。个人技术站点:http://www.54chen.com/ 。可以通过电子邮件 czhttp@gmail.com 联系到他。
参考的网站
http://project-voldemort.com/
http://cassandra.apache.org/
http://s3.amazonaws.com/AllThingsDistributed/sosp/amazon-dynamo-sosp2007.pdf
http://timyang.net/data/dynamo-flawed-architecture-chinese/
http://www.cs.berkeley.edu/~brewer/
http://www.54chen.com/document/dynamo-based-systems.html
http://www.cs.berkeley.edu/~brewer/cs262b-2004/PODC-keynote.pdf
http://en.wikipedia.org/wiki/Distributed_hash_table
http://en.wikipedia.org/wiki/Consistent_hashing
标签:dynamo, nuclear