您现在的位置:首页
--> 算法
VLA (可变长度数组) 是 C 语言在 C99 之后加入的一个很方便的语言特性,但是 MSVC 已经明确不支持 VLA 了。而且 Linux 的内核代码中曾经使用过 VLA ,而现在已经移除了 VLA 。看起来,VLA 带来的安全问题比它的便利性要多。
但是,日常用 C 语言做开发时,经常还是需要变长数组的。既然直接用 C 语言的 VLA 有诸多问题,那么还是需要额外实现一个比较好。C 没有 C++ 那样的模板支持,一般的通用 VLA 实现很难做到类型安全。即使用 C++ ,STL 中的 vector ,这个最常用的 VLA 实现,也不总是切合应用场景的。比如,std::vector 它的数据一般还是分配在堆上,而不是栈上。相比原生创建在栈上的数组,它可能性能有影响且有可能制造更多的堆内存碎片。
今天在扩展我们游戏中的管道系统时,又遇到了实现一个无向图的问题。
之前的管道系统,每节管道的邻接管数量有限,所以我用了类似树的方式储存,在每节管道上直接放了一个固定大小的数组,保存该节管道的上下游节点。对于液体管道系统,这套数据结构工作的很好。
今天,我们的另一个系统需要一个有点不一样的管道。它没有方向,每个节点可以有很多的邻接点。例如电线拉成的网络、导热管构成的网络,都是这样的。这是典型的无向图结构。
我重新考虑了数据结构,用邻接表实现了一版。
我把节点的数据和节点的邻接关系分开到不同的数据结构中,这样方便单独把管道连接模块独立出来复用。
首先,用一个有序的数字 id 表示图中的节点。由于我们的图规模不会太大,16bit 的 id 就够用了。那么,相邻节点的连接关系就是图中的边,它可以用两个 id 连起来共 32bit 表示。由于是无向图,我们

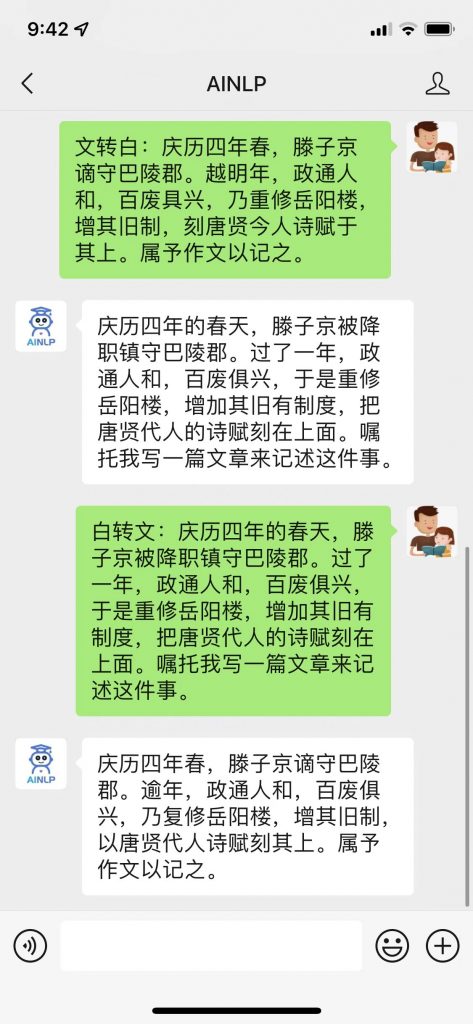
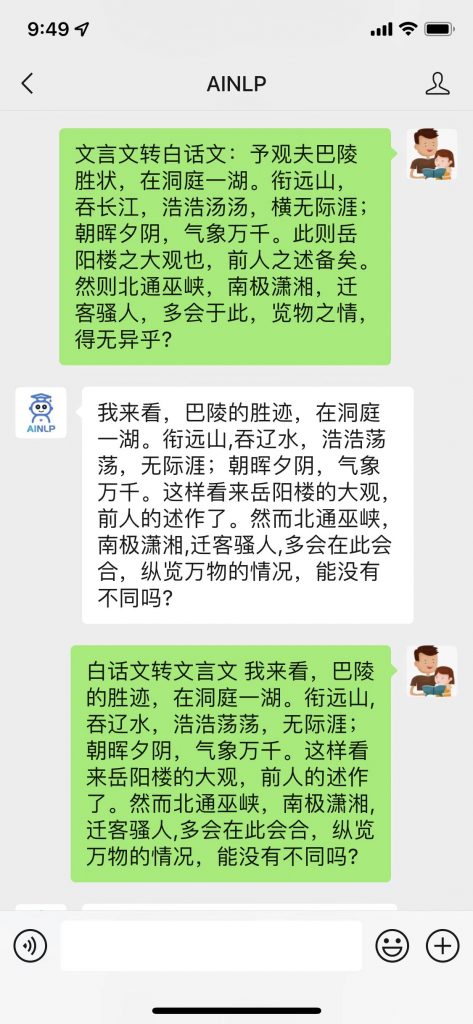
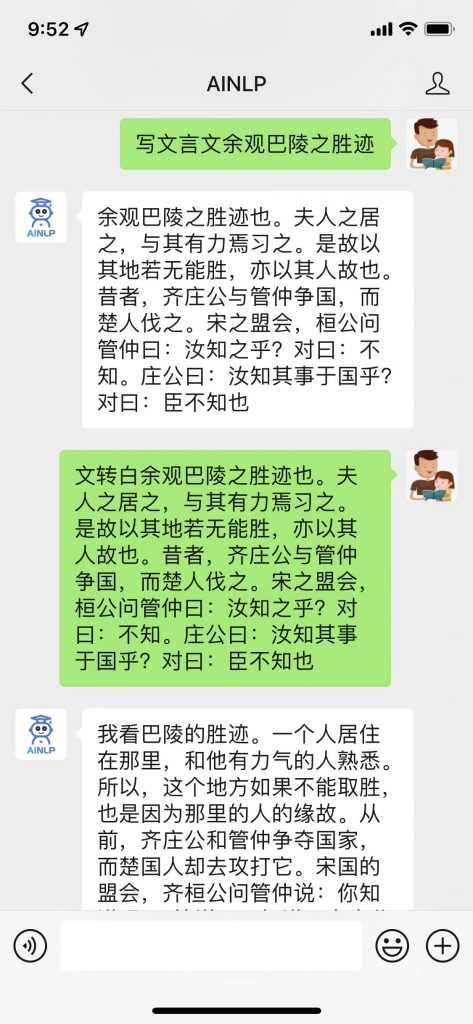
前几天,看到了东北大学小牛翻译团队开源的语料项目:文言文(古文)-现代文平行语料 ,这个项目整理了非常全的文言文(古文)- 现代文(白话文)对齐数据,基本涵盖了大部分经典古籍著作,并且对原始爬取的篇章级对齐数据进行了断句及人工校对,形成了共计约96万句对的文言文-白话文对齐(平行)语料。
这份语料数据很珍贵,看到的第一眼想到就是用这份文言文现代文对齐语料训练一个文言文白话文转换器:文言文转白话文,文言文转现代文,白话文转文言文,现代文转文言文,古文转白话文,白话文转古文,古文转现代文,现代文转古文。
• 不变量及运算优化
去年的时候,我们对正在开发中的游戏引擎做了一点 profile 工作。后来发现,在场景中对象很多的时候,有一处运算占据了 10% 以上的 cpu 时间。当时我的判断是,这处地方值得优化,但并不是工作重点,所以就搁置了。
问题的具体描述是这样的:
我们的引擎每帧会将场景中的对象依次提交到一个渲染队列中,每个可渲染物件,除了自身的网格、材质外,还有它自身的包围盒(通常是 AABB),以及它在世界空间中的矩阵。
我们有一套资源系统,场景中的对象会引用资源系统中的对象,这些资源对象是一个不变量,会被多个场景对象所引用。而资源对象又可以是一个树结构,比如一个模型就可以由若干子模型所构成。提交到最终渲染队列中的是不可再拆分的子模型的信息。
也就是说,在场景管理的层次,对象的数量是远少于提交到渲染队列中的对象数量的。这就是为什么我们渲染每次重建渲染队列,而没有将每帧提交给渲染队列的列表持久化为一
一个好的视觉对话模型不仅需要理解来自视觉场景、自然语言对话两种模态的信息,还应遵循某种合理的策略,以尽快地实现目标。同时,目标导向的视觉对话任务具有较丰富的应用场景。例如智能助理、交互式拾取机器人,通过自然语言筛查大批量视觉媒体信息等。
• 位运算技巧整理
位运算技巧整理。


在电商行业,线上的营销活动特别多。在移动互联网时代,一般为了活动的快速上线和内容的即时更新,大部分的业务场景仍然通过 Web 页面来承载。但由于 Web 页面天生“环境透明”,相较于移动客户端页面在安全性上存在更大的挑战。本文主要以移动端 Web 页面为基础来讲述如何提升页面安全性。
这是笔者一个好友面试阿里时,被问及的一个问题,应该不少人看到这个问题都会一面懵逼。因为,大部分的文章都是分析链表是怎么转换成红黑树的,但是并没有说明为什么当链表长度为8的时候才做转换动作。笔者第一反应也是一样,只能初略的猜测是因为时间和空间的权衡。




这篇文章我们继续学习一下GBDT模型的另一个进化版本:LightGBM。LigthGBM是boosting集合模型中的新进成员,由微软提供,它和XGBoost一样是对GBDT的高效实现,原理上它和GBDT及XGBoost类似,都采用损失函数的负梯度作为当前决策树的残差近似值,去拟合新的决策树。
前两天在AINLP公众号上发起了一个话题留言活动:你是如何了解或者进入NLP这个领域的?没想到,活动发布后,大家参与的热情极高,收到了200多条留言,但是限于微信公众号留言只能精选100条放出,所以有些遗憾,很多后来的同学的留言虽然写得很好,但是没有办法放出来了。今天是周末,我又认真的从前到后读了一遍,感慨每个人都有自己的NLP故事,这里做一次汇总,尽量把留言都放出来,就不一一回复了,感谢大家的支持与参与。
这篇文章是stackoverflow的一篇帖子。上面提到了很多有用的数据结构。有的听过了,经常用,有的没有听过,记录下来。
• 图数据库简介

在记录的关键字与记录的存储地址之间建立的一种对应关系叫哈希函数。
哈希函数就是一种映射,是从关键字到存储地址的映射。
通常,包含哈希函数的算法的算法复杂度都假设为O(1),这就是为什么在哈希表中搜索数据的时间复杂度会被认为是”平均为O(1)的复杂度”.













马氏距离(Mahalanobis Distance)是由印度统计学家马哈拉诺比斯(P. C. Mahalanobis)提出的,表示数据的协方差距离。有时也被称为马哈拉诺比斯距离。它是一种有效的计算两个未知样本集的相似度的方法。与欧氏距离不同的是它考虑到各种特性之间的联系(例如:一条关于身高的信息会带来一条关于体重的信息,因为两者是有关联的)并且是尺度无关的(scale-invariant),即独立于测量尺度。




切比雪夫距离起源于国际象棋中国王的走法,国际象棋中国王每次只能往周围的8格中走一步,那么如果要从棋盘中A格(x1, y1)走到B格(x2, y2)最少需要走几步?你会发现最少步数总是max(| x2-x1 |,| y2-y1|) 步。有一种类似的一种距离度量方法叫切比雪夫距离。




在前面介绍的DBSCAN算法中,有两个初始参数Eps(邻域半径)和minPts(Eps邻域最小点数)需要手动设置,并且聚类的结果对这两个参数的取值非常敏感,不同的取值将产生不同的聚类结果。为了克服DBSCAN算法这一缺点,提出了OPTICS算法(Ordering Points to identify the clustering structure),翻译过来就是,对点排序以此来确定簇结构。
OPTICS是对DBSCAN的一个扩展算法。该算法可以让算法对半径Eps不再敏感。只要确定minPts的值,半径Eps的轻微变化,并不会影响聚类结果。OPTICS并不显示的产生结果类簇,而是为聚类分析生成一个增广的簇排序(比如,以可达距离为纵轴,样本点输出次序为横轴的坐标图),这个排序代表了各样本点基于密度的聚类结构。它包含的信息等价于从一个广泛的参数设置所获得的基于密度的聚类,换句话说,从这个排序中可以得到基于任何参数Eps和minPts的DBSCAN算法的聚类结果。




ISODATA算法(Iterative Self Organizing Data Analysis Techniques Algorithm,迭代自组织数据分析方法)和K-Means算法是相似的算法,都是属于无监督的聚类分析方法,但是
在之前介绍的K-Means算法中,有两大缺陷:
1、K值需要预先设定;
2、随机的初始中心选择对计算结果和迭代次数有较大的影响;
近3天十大热文
-
 [340] Go Reflect 性能
[340] Go Reflect 性能 -
[14] [译]Google Chrome中的高性能网
-
[11] Linux Used内存到底哪里去了?
-
[10] webapp网页调试工具Chrome Dev
-
[10] 精于图片处理的10款jQuery插件
-
[10] Mac下.apk的反编译
-
[9] rsync同步的艺术
-
[9] 在FreeNAS/BSD搭建基于Nginx+
-
[9] 程序中的“多线程”
-
[9] jQuery性能优化指南
赞助商广告
