您现在的位置:首页
--> MySQL

我们公司新配置了一台服务器,使用的MYSQL5.5,当时并没考虑到会有GBK的网站放上来,本来UTF8网站都运行正常,后来有两台服务器合并,把老服务器拿回来了,老服务器上的网站全部放到新服务器上,这样就麻烦大了。老网站大量使用的是GBK版本,在新服务器上全部乱码。 执行时还会报GBK字符集不支持的错误,查看了一下字符集,MYSQL5.5确实默认情况下不支持GBK,那只好重新装了。 把MYSQL,deinstall后,执行make WITH_CH...




Infobright是一款开源列式数据仓库引擎,采用他们自己的Knowledge Grid架构(一直没有明白这两个单词),该引擎采取内部管理自身优化查询的方式,给用户带来更为轻松的体验。我们所要做的就是写出“漂亮”的SQL,后面我会关于SQL语句说点有趣的东西。Infobright像很多优秀的开源软件一样,也都具有两个版本,社区版(ICE)和企业版(IEE),多数情况下,如果免费的能满足我们的实际需求,领导更愿意采用社区版;企业版需要付费,那...
mysql的执行计划:explain显示了mysql如何使用索引来处理select语句以及连接表。可以帮助选择更好的索引和写出更优化的查询语句。使用方法,在select语句前加上explain就可以了:如:explain select * from test1EXPLAIN列的解释:table:显示这一行的数据是关于哪张表的type:这是重要的列,显示连接使用了何种类型。从最好到最差的连接类型为const、eq_reg、ref、range、indexhe和ALLpossible_keys:显示可能应用在这张表中的...
1.MySQL注重查询速度,而PostgreSQL注重于标准化。 2.MYSQL的MYISAM机制比较快,同时count(*)比PostgreSQL快,同时牺牲了支持事物、外键、数据持久性等特性,而PostgreSQL的Count(*)比较慢,是因为它的并发机制。 3.数据压缩性:PostgreSQL更佳(LOW_FORMAT)。 4.多核处理:PostgreSQL的多核处理更好,在Windows环境下启动服务的时候同时启动5个进程,而MySQL只有一个。 5.并发数:PostgreSQL支持更佳,8.3版本的可以达到5000个并...
最近经常有人问我 MySQL Query Cache 相关的问题,就整理一点 MySQL Query Cache 的内容,以供参考。顾名思义,MySQL Query Cache 就是用来缓存和 Query 相关的数据的。具体来说,Query Cache 缓存了我们客户端提交给 MySQL 的 SELECT 语句以及该语句的结果集。大概来讲,就是将 SELECT 语句和语句的结果做了一个 HASH 映射关系然后保存在一定的内存区域中。在大部分的 MySQL 分发版本中,Query Cache 功能默认都是打开的,我们...
Mysql的 Replication 是一个异步的复制过程,从一个 Mysql instace(我们称之为 Master)复制到另一个 Mysql instance(我们称之 Slave)。在 Master 与 Slave 之间的实现整个复制过程主要由三个线程来完成,其中两个线程(Sql线程和IO线程)在 Slave 端,另外一个线程(IO线程)在 Master 端。
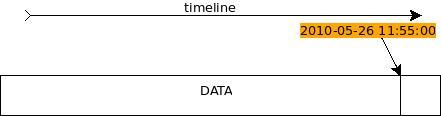
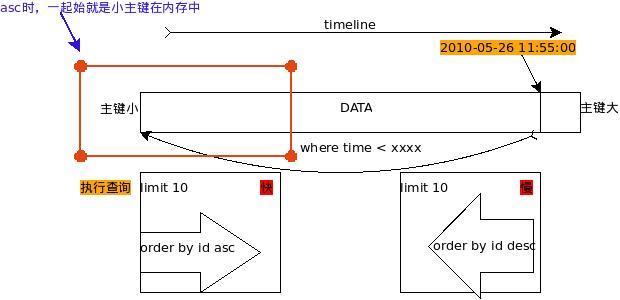
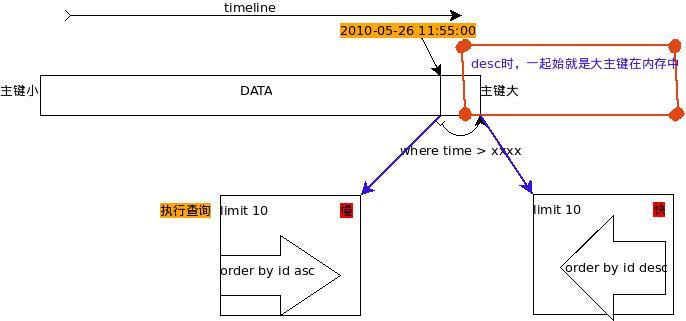
在实际工作中遇到下面一个问题:有一个表,存有2000万数据。主键为ID bigint(20) NOT NULL auto_increment 另有一字段time timestamp NOT NULL default CURRENT_TIMESTAMP 故事从这两个字段说起: sql1需要从这个表...
今天有个产品找我,说新手卡录入后台报错。先简单介绍一下这个新手卡录入后台,这个后台是提供给产品人员使用。可以向某个游戏的某个特定分区批量录入新手卡信息,方便玩家获取。后台设置的一次性最大录入量为500。先看日志吧,报错的内容和日志的相同: Error: SQLSTATE[HY000]: General error: 2006 MySQL server has gone away 这个错误信息很好的描述了是数据库超时引起的。以前听前辈说过,应该是wait_timeout环境变量设...
select distinct可以去掉重复记录。 disctinct将重复的记录忽略,但它忽略的是完全一致的重复记录,而不是其中某个字段重复的记录,或者说,distinct查询一个字段时好使,多个字段就不好使。所以用聚合函数和group by实现注意:group by只能跟聚合函数搭配使用
端午节到了,3天的假期可以好好放松下紧张了又一个月的神经,同时也可以总结一下近期的工作;遗憾的是,自从工作了就再也没能吃到老妈包的粽子了(姜米配上红豆、花生、大红枣,我的最爱)。DBA的工作不知不觉已经经历了第二个月,比第一个月更加“凶险”――死里逃生(未知),我似乎成为了运维部的【问题焦点】,信任、仔细、积极、能力、诚实等等属性都面临着各方面的考验。曾经一度想逃离,工作的郁闷,自己内心的沉重,问题冒...
存储引擎是什么? MySQL中的数据用各种不同的技术存储在文件(或者内存)中。这些技术中的每一种技术都使用不同的存储机制、索引技巧、锁定水平并且最终提供广泛的不同的功能和能力。通过选择不同的技术,你能够获得额外的速度或者功能,从而改善你的应用的整体功能。例如,如果你在研究大量的临时数据,你也许需要使用内存存储引擎。内存存储引擎能够在内存中存储所有的表格数据。又或者,你也许需要一个支持事务处理的数据库(以确...




在写SQL语句的时候,用的最多的条件子句就是”where”,而”having”也是条件子句。二者相似,却也有不同。让我们简单了解一下。 where和having的区别是where子句对一个表的所有记录进行操作,只搜索与指定条件相匹配的记录。而having子句只对经过操作的表记录进行检索,对结果集进行更进一步的筛选。通常,having子句和group by子句相连,而where子句和select,delete和update语句相连。
最近接到了大量的需求,需要每天定时的从oracle导到Mysql生产服务器上,数据量还比较大,大概在5亿,90G左右,数据量太大了,需要进行分表,小表跑的快,失败的几率也小一些。1.分表,单个表数据量控制在5G(个人随意指定)2.找一台中转服务器,需要安装oracle和mysql的客户端,这台服务器需要从源oracle数据库上导出数据,然后导到目标mysql服务器中3.通过sqluldr从源oracle把数据导出来,导成txt文件 mytest:/bak1/tmp_dy>$...
昨天折腾了一下自己的网站,试图进行一些迁移工作,这其中遇到的首要问题是Mysql的乱码问题。由于Mysql是从版本 4迁移到Version 5的,原来的字符集是latin1,现在是UTF8,这就遇到了经典的乱码问题,即使通过phpadmin来访问,也是一片纷乱,还好在前端的展现正常。 在网上搜一下,很多帖子和方法,最后我通过如下步骤,终于纠正了多年来的乱码问题。
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。 2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如: select id from t where num is null 可以在num上设置默认值0,确保表中num列没有null值,然后这样查询: select id from t where num=0 3.应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全...
在LAMP阵营中,MySql占有很大比重,经常都会对数据库进行操作,但若不注意一些细节,很可能导致不必要的麻烦!这里就将谈谈MySql的相关优化问题,主要是从提高MySql数据库服务器的性能的思路进行考虑,主要包含以下8个方面的优化:1、选取最适用的字段属性; 2、使用连接(JOIN)来代替子查询(Sub-Queries); 3、使用联合(UNION)来代替手动创建的临时表; 4、事务; 5、锁定表; 6、使用外键; 7、使用索引;...
其实很简单,就是利用正则表达式,从文件中抽取,可以用awk或sed.
今天在把django开发的系统从开发环境搬到外网的时候,发现凡是中文写入Mysql的时候,都会报错: Data truncation: Data truncated for column xxx 网上搜了一下,排除了字段本身长度不够,剩下只能是因...
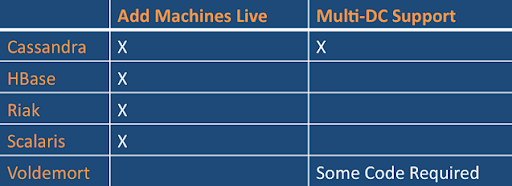
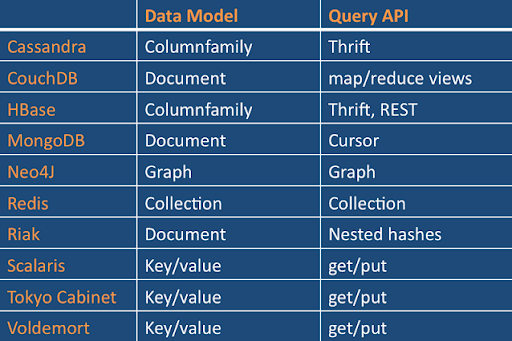

空前的数据量正在驱动商业寻找传统关系型数据库的替代方案,它已经为我们服务30多年了(今年5月份ACM刚刚给关系型数据庆祝40岁生日).总体来讲,这些替代方案就是目前知名的“NoSQL数据库.”关系型数据库的基本问题是无法处理许多现代的工作负载.有三个具体的问题领域:向外扩展(Scale out)类似于Digg(3TB的绿色徽章 数据)或Facebook(50T 的收件箱搜索数据)或Ebay(总共2PB的数据)的数据集,单机性能限制以及僵化的概要设计.
近3天十大热文
-
 [18] [译]Google Chrome中的高性能网
[18] [译]Google Chrome中的高性能网 -
[16] Linux常用系统信息查看命令
-
[16] 关于Linux的文件系统cache
-
[16] 在FreeNAS/BSD搭建基于Nginx+
-
[15] 最近总结的一些技巧(vim,python,s
-
[11] PHP加速器 eaccelerator 缓存
-
[11] Buffer和cache的区别是什么?
-
[10] Go Reflect 性能
-
[9] base64_encode 和 urlenc
-
[9] Linux(Ubuntu 10.04)上安装
赞助商广告
