保障IDC安全:分布式HIDS集群架构设计
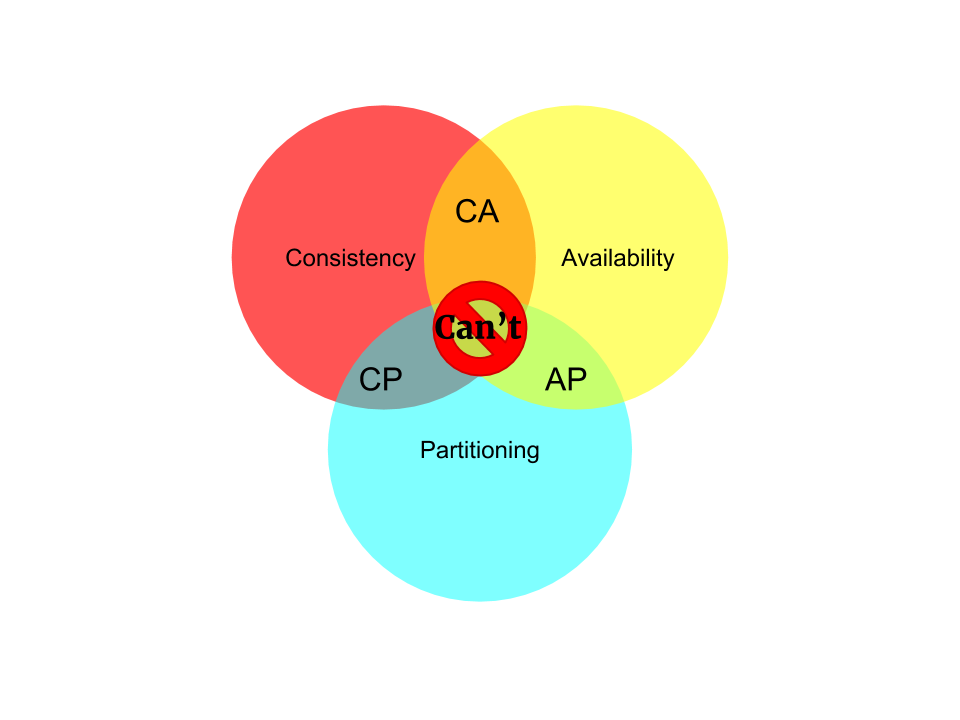
面对百万级服务器规模的IDC环境,如何设计一套既可靠又高效的主机入侵检测系统(HIDS)集群?这篇文章从美团安全部的实际需求出发,剖析了在如此大规模下HIDS Agent管理面临的核心挑战——包括如何实现低损耗部署、集群的快速精准控制、配置一致性保障,以及Agent与服务器间通信的安全性。 作者详细阐述了架构选型的思考过程。在分布式系统的CAP定理框架下,为保障控制指令的最终一致性(即下发关停时,Agent必须执行),团队果断选择了CP架构。通过对比etcd、ZooKeeper与Consul,最终选定etcd作为核心组件,利用其Watch机制实现实时配置下发、Lease租约感知主机下线、以及细粒度的TLS加密与RBAC权限控制。 文章不止于理论,更深入到实战层面,分享了基于etcd的Key前缀设计策略,以及为应对DNS故障而采用的IP与域名混合部署的集群管理实践。对于从事大规模运维或安全架构设计的工程师而言,文中关于“如何在有限资源下管理百万级终端”的具体思路与踩坑经验,具有很强的参考价值。