您现在的位置:首页 --> 查看专题: spark





Facebook 经常使用数据驱动的分析方法来做决策。在过去的几年,用户和产品的增长已经需要我们的分析工程师一次查询就要操作数十 TB 大小的数据集。我们的一些批量分析执行在古老的 Hive 平台( Apache Hive 由 Facebook 贡献于 2009 年)和 Corona 上——这是我们定制的 MapReduce 实现。Facebook 还不断增加其对 Presto 的用量,用于对几个包括 Hive 在内的内部数据存储的 ANSI-SQL 查询。我们也支持其他分析类型,比如图数据库处理(graph processing)和机器学习(Apache Giraph)和流(例如:Puma、Swift 和 Stylus)。
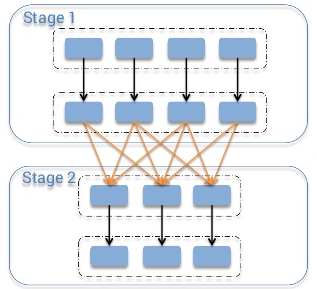
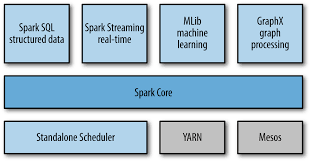
本文将教大家怎样用10个步骤完成给Apache Spark贡献代码这个任务:)




Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于map reduce算法实现的分布式计算,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出和结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的map reduce的算法。
希望能够给希望尝试Spark的朋友,带来一些帮助。目前的版本是0.5.0 Spark开发指南 从高的层面来看,其实每一个Spark的应用,都是一个Driver类,通过运行用户定义的main函数,在集群上执行各种并发操作和计算 Spark提供的最主要的抽象,是一个弹性分布式数据集(RDD),它是一种特殊集合,可以分布在集群的节点上,以函数式编程操作集合的方式,进行各种各样的并发操作。它可以由hdfs上的一个文件创建而来,或者是Driver程序中,从一个已经存在的集合转换而来。用户可以将数据集缓存在内存中,让它被有效的重用,进行并发操作。最后,分布式数据集可以自动的从结点失败中恢复,再次进行计算。
[ 共6篇文章 ][ 第1页/共1页 ][ 1 ]
近3天十大热文
-
 [853] WordPress插件开发 -- 在插件使用
[853] WordPress插件开发 -- 在插件使用 -
[55] cookie窃取和session劫持
-
[53] 你必须了解的Session的本质
-
[52] 最萌域名.cat背后的故事:加泰与西班牙政府
-
[50] 解读iPhone平台的一些优秀设计思路
-
[50] 一句话crontab实现防ssh暴力破解
-
[48] Linux如何统计进程的CPU利用率
-
[47] 关于IO的同步,异步,阻塞,非阻塞
-
[47] Rax 系列教程(长列表)
-
[44] 豆瓣是啥?
赞助商广告
