您现在的位置:首页 --> 查看专题: 搜索





随着互联网的兴起及发展,人们获取信息的途径由传统方式逐渐被网络替代。 起初人们主要通过浏览网页来获取所需信息, 但随着Web不断庞大用这种方式来寻找自己所需的信息变得越来越困难。现在大多数的人很大程度上依赖于搜索引擎来帮助自己获取有用信息,因此搜索引擎技术作为最典型的Web信息获取技术 其发展直接影响人们获取信息的质量。 自从1994 年4 月世界上第一个Web 检索工具Web Crawler 问世以来, 目前较流行的搜索引擎已有...



网络爬虫(web crawler)又称为网络蜘蛛(web spider)是一段计算机程序,它从互联网上按照一定的逻辑和算法抓取和下载互联网的网页,是搜索引擎的一个重要组成部分。一般的爬虫从一部分start url开始,按照一定的策略开始爬取,爬取到的新的url在放入到爬取队列之中,然后进行新一轮的爬取,直到抓取完毕为止。 我们看一下crawler一般会遇到什么样的问题吧: 抓取的网页量很大 网页更新量也很大,一般的网站,比如新闻,电子商务网...




附近地点搜索,顾名思义,就是搜索用户附近有哪些地点。随着GPS和带有GPS功能的移动设备的普及,附近地点搜索也变得炙手可热。不过在网上却很少有这方面的讨论。本文的方法并不算最好,但足以应付一般的应用了。本文中,数据库采用MySQL,语言采用python。理论上别的数据库和语言也没问题,但我们要在经纬度上设置两个索引,所以如果你的数据库不支持索引,或者不支持在一个查询中使用两个索引,那就只能想别的办法了。球面...
随着互联网视频越来越多,人们迫切希望能够快速地从众多的视频中精准定位到一些高质量的视频。视频清晰度是评价视频质量的一个重要指标,特别是对于影视剧和动漫类视频来说,高清晰的视频能大大提升用户的体验。所以如何判断视频清晰度,识别出高清晰的视频对于用户和搜索引擎来说是非常有价值的。 和大多数评价机制一样,视频清晰度分为相对清晰度和绝对清晰度。相对清晰度可以理解为视频之间的清晰度排序,而绝...

《从狄仁杰的测字占卜到一淘网的Query分析之大结局》一文在淘宝搜索技术博客发表已经快一个月了,很多看客看了后给我反馈。当然大部分看客看完后会给一个看似褒奖实则中性的评论:屁股上挂暖壶----有一定(腚)的水平。部分看客看完很不爽,说刚看到“美女说不够深入,不能满足欲望”之处便戛然而止,怎么没有帅哥英雄救美,满足所有想法的预期场景出现。我以前的一个同事更是直接抨击:《狄仁杰》一文就是一篇典型的太监文-----下...
这篇论文讲的是,一个全球的搜索引擎,需要在不同的地区布署一套服务,不同地区的索引不同。注:这也很容易理解,首先是带宽的压力,索引一般都是TB级别的,不能到处拷;其次是性能考虑,不同地区用户关注的网页是不同的,把用户不需要的网页也加进索引里,会使得检索性能很差。但是如果要地区的索引不能满足用户的需求,需要读取别的地区的索引的时候,怎么办?需要解决两个问题,一是是否需要读取别的地区的索引,二是读取哪...



百度是张朝阳嘴里所谓战国七雄中最晚成立的公司――2000年1月才有百度公司,但它的流量在中国首屈一指,是中国网站当下在alexa中排名最高的。从吸金能力上讲,根据今年2季度它财报19.14亿元的收入水平,2季度它每秒收入246元人民币(以90天计算),排名第二,次于腾讯。 2010第二季度总收入 折合每秒收入 新浪 9940万美元 12.78美元 搜狐 1.461亿美元 18.79美元 网易 1.99亿美元 25.59美元 盛大 2.01亿美元 25.85美元 腾讯 ...
几种常见的基于Lucene的开源搜索解决方案对比
有一段时间,我曾有这样一个观点:门户是第一代互联网中心,搜索则是第二代,在这两代中心之间,有一次互联网泡沫破灭。而第三代互联网中心,则是社交网络。如果说搜索的目标是信息定位的话,那么,社交网络的目标,就是人的定位问题。 门户的兴起,是因为它解决了当年互联网上没什么信息的状况,而搜索引擎,则解决了如何快速在海量但却杂乱无章的信息海洋中做到信息定位。而UGC为核心的web2.0运动,则让“互联网上没人知道你是条...
首先是排序的问题。Lucene 默认的排序考虑了很多因素,套用到邮箱搜索的结果里,很多时候反而显得结果很混乱,不同文件夹,不同时间,不同主题,不同发件人的邮件混在一起,更严重的是,已读邮件和未读邮件混在一起了:已读和未读邮件的 css 样式是不一样的,混在一起的结果就是,界面看起来非常混乱。
邮箱搜索与其它的搜索引擎最大的区别莫过于每个用户只能搜索自己的邮件内容。搜索引擎一般都是开放性的搜索,每个用户都有权访问所有的索引项目,每次搜索请求都会在所有的索引项目中进行匹配。而邮箱搜索是私密搜索,每个用户只能访问索引中很小的一部分数据,相应的,也就可以将每个用户的索引单独存放,以加快建索引和搜索的速度。
在SNS网站中,“好友的相册”、“好友的日志”、“好友常去的小组”,这样的功能到处都是,如果处理不当,对整个系统的压力都会非同小可。 这里介绍一种利用sphinx的搜索天性,倒排索引群中的人,然后把好友的XX功能化解为或关系的搜索,下面是是一些记录。
PHP中文分词类,主要作用是分析语料库,找出核心主题词,是网页相似度引擎的子模块相比成熟的分词类库,如Lucene,中科院之流 没有任何优势,本类库是实验性项目,效率及算法[trie]并无特殊 ...




知识搜索,就是针对你的提问,直接提供经过精挑细选的高质信息。最大的好处是,你可以尽可能的使用自然语言。国内主要知识搜索引擎有很多,比如新浪爱问,百度知道,天涯问答和搜搜问问,国外的主要有Google Answer(已停止服务),Naver,Yahoo! Answer等。这里打算从细节入手,从最简单的需求“提问”出发,窥探国内经过长足发展之后的四大平台。准备阶段知识搜索引擎 1、新浪爱问知识人(中国鼻祖) 2、百度知道(影响力最大...
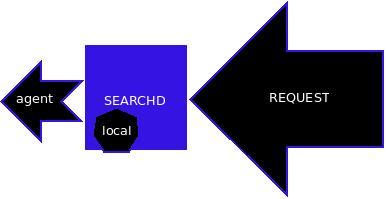
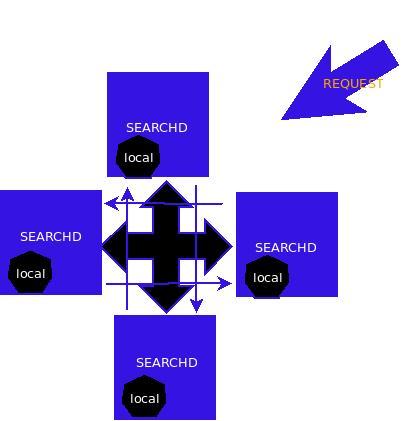
来自俄罗斯的开源全文搜索引擎软件Sphinx,单一索引最大可包含1亿条记录,在1千万条记录情况下的查询速度为0.x秒(毫秒级),实测千万级数据在0.0X秒和0.00X秒占大多数。 Sphinx创建索引的速度为:创建100万条记录的索引只需3~4分钟,实测30W线上复杂的blog数据需要5分钟,创建1000万条记录的索引可以在50分钟内完成,实测时间比这个更长得多,而只包含最新10万条记录的增量索引,重建一次只需几十秒,实测十万条在一分钟不到的时间。 Sphinx 是一个基于 GPL 2 协议颁发的免费开源的全文搜索引擎.它是专门为更好的整合脚本语言和SQL数据库而设计的.当前内置的数据源支持直接从连接到的 MySQL 或 PostgreSQL 获取数据, 或者你可以使用 XML 通道结构(XML pipe mechanism , 一种基于 Sphinx 可识别的特殊xml格式的索引通道) 。

出自俄罗斯的开源全文搜索引擎软件Sphinx,单一索引最大可包含1亿条记录,在1千万条记录情况下的查询速度为0.x秒(毫秒级)。Sphinx创建索引的速度为:创建100万条记录的索引只需3~4分钟,创建1000万条记录的索引可以在50分钟内完成,而只包含最新10万条记录的增量索引,重建一次只需几十秒。

Xapian API是相当复杂的,而且在索引和搜索时,QueryParser,Term,document values 经常困惑着人们.要特别指出的是,Xapian本身并无一个”field”的概念,field这东西是flax的组件做的更高层次的抽象和封装.Xapian只是有Document ,包含一个整数标识ID,document包含:
Terms (通常是词或短语,可以带位置信息,带位置信息的叫POST),
VAlue (通常是一个简短的字符串,也可能是包含的二进制数据),以及
data (可以是任何数据,但往往是一些适合显示的文本)。
为节省存储空间和提高搜索效率,搜索引擎在索引页面或处理搜索请求时会自动忽略某些字或词,这些字或词即被称为Stop Words(停用词)。 Stop Words大致为如下三类: 应用十分广泛,在Internet上随处可见的词,比如“Web”一词几乎在每个网站上均会出现,对这样的词搜索引擎无法保证能够给出真正相关的搜索结果,难以帮助缩小搜索范围,同时还会降低搜索的效率。语气助词、副词、介词、连接词等,通常自身并无明确的意义,只有将...
搜索引擎爬虫蜘蛛的USERAGENT收集
近3天十大热文
-
 [16] Go Reflect 性能
[16] Go Reflect 性能 -
[14] 浏览器的工作原理:新式网络浏览器幕后揭秘
-
[14] iTerm2 (Mac Terminal)
-
[13] iOS可视化编程 Tips 之“无需代码设置
-
[12] iOS下自己动手造无限循环图片轮播
-
[12] 界面设计速成
-
[11] 系统工程师的自我修养- sed篇
-
[11] 浅谈Web安全验证码
-
[11] 最萌域名.cat背后的故事:加泰与西班牙政府
-
[11] iOS并发编程(Concurrency Pr
赞助商广告
