您现在的位置:首页 --> 查看专题: IO

昨天在群中,又有很多人在问,我的服务器跑不上量,我的服务器只能跑十几M 流量,为什么别人能跑上 G 的流量。为什么? 服务器基本很少是为了跑量的,只有到了最后,追求成本的时候这...
目前磁盘都是机械方式运作的,主要体现在磁盘读写前寻找磁道的过程。磁盘自带的读写缓存大小,对于磁盘读写速度至关重要。读写速度快的磁盘,通常都带有较大的读写缓存。磁盘的寻道过程是机械方式,决定了其随机读写速度将明显低于顺序读写。在我们做系统设计和实现时,需要考虑到磁盘的这一特性。 FastDFS是一个开源的高效分布式文件系统,它最初的实现,文件是按hash方式随机分布到多个目录中的,后来增加了顺序存放的做...
我们在调优IO 密集型的应用是通常需要知道IO的使用情况. 但是iostat只能知道系统全局的,iotop只能知道每个应用的, 我们有时候需要细化到每个应用对每个设备的使用情况. 比如说mysql数据库我们通常把日志和数据分开到不同的设备, 那我们需要知道数据读写多少,日志读写多少,分开的了解. 目前还没有工具能够很轻松的了解. 幸运...
当多核解决了 CPU 运算能力问题,当 64 bit 系统解决了内存不足问题,IO 问题依然让人困扰。 梦幻西游的服务器从更早的产品延续,已经跑了 10 年了。当初之求快速把项目做出来,用最简单的方法做出来,保证稳定可以用,自然遗留了无数问题。逻辑脚本中充斥随手可见的磁盘操作。 最终,当磁盘操作堆积起来,尤其是阻塞方式请求,并行的过程全部都在磁盘访问处串行起来了。固然整个系统的处理能力并没有下降。但用户的反应时间却会...
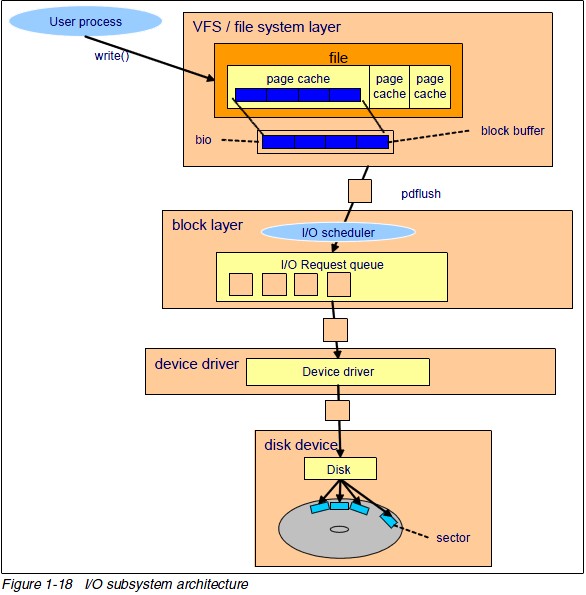
I/O模型: I/O操作需要内核系统调用来完成,系统调用需要Cpu来调度,而Cpu的访问速度相对于I/O来说比较快,所以Cpu不得不浪费Cpu时间来等待慢速I/O操作. 通过多进程方式来充分利用CPU资源,当还是希望让Cpu花费少的时间在I/O操作的调度上,这样就可以有更多的Cpu来完成I/O操作. 很多技术和策略都围绕如何让高速的Cpu和慢速的I/O设备更好的协调工作. I/O操作主要是网络数据的接收和发送,以及磁盘文件的访问.归纳为多种模型称为I/O模...
这季度学习java nio及其相关的内容和框架,所以就想先看看Unix下的一些IO模型。结合网络上的资料进行学习,自己也写篇日志,加强一下理解吧。 POSIX中对同步IO和异步IO的规定: 同步IO操作:引起进程的阻塞直到IO操作完成 异步IO操作:IO操作不会引起进程阻塞 在UNIX下,有5中操作模型: 阻塞IO 非阻塞IO IO复用 信号驱动IO 异步IO 按照网络上的说法,前四种是属于同步IO,第五种才属于异步IO,对于这个结论,我的理解是根据用户进...
我们在做IO密集型的应用程序的时候,比如MySQL数据库,通常系统的表现取决于workload的类型。 比如我们要调优,我们就必须非常清楚的知道数据的访问规律,收集到足够的数据,用来做调优的依据。 有很多工具可以收集系统层面的,设备层面的,进程层面的IO数据,但是没有一个现成的工具可以回答我们比如应用打开了多少文件,文件的读和...
关注梦幻西游服务器的性能问题,是源于前几天跟同事的聊天。谈到能否把梦幻西游服务器做成无盘站,或是放进虚拟机里,便于日常维护管理。意外的了解到,现在磁盘 IO 性能居然成了梦幻西游服务器的瓶颈。而不是 CPU 或是网络带宽。据我所知,梦幻西游的服务器数据储存是这样做的:主游戏进程不负责储存,一切都在内存中。所有玩家的数据就是内存数据结构。只是在玩家登陆的时候去读取一下本地的文本文件,以及登出的时候把数据序列...
CPU时间采集从10G开始,oracle引入了时间模型,我们可以从oracle的角度来看CPU的使用程度先说说几个概念 db time:oracle数据库消耗的时间,这个范围比较大,包括了CPU使用,等待IO子系统返回,网络处理等 db cpu:指oracle单纯消耗CPU,做CPU运算的时间,关于IO,网络的等待都不在这个范围内,用它来统计真实CPU的消耗比较准确 CPU TIME:这个是我取的名字,表示CPU能给你提供的最大时间,比如你有4个cpu/core,那么1小时内,CPU T...
在实际的编程中, 有两个问题要处理, 一个是如何找出磁盘, 并将分区过滤掉, 因为Linux会同步更新磁盘分区及磁盘的数据, 如果不加区分, 数据就会不准确, 这个可以通第2列及第3列加以区分, 第二列为16的倍数的表示是磁盘而非分区, 第三列是磁盘名字, 一般的系统中磁盘都是小写的sd开头的. 对于普通的scsi磁盘, 只要找出第二列是16的倍数, 并且第三列前两个字母是”sd”的, 就表示是真正的磁盘, 比如前面的数据中, 只能取第一行. 为什么是16的倍数, 估计和一块盘最多有16个分区有关吧.
[ 共31篇文章 ][ 第2页/共2页 ][ 1 ][ 2 ]
近3天十大热文
-
 [92] Go Reflect 性能
[92] Go Reflect 性能 -
[15] 我的git笔记
-
[13] 公钥私钥加密解密数字证书数字签名详解
-
[13] osx平台上lol英雄联盟launcher启
-
[13] 基于HTTP缓存轻松实现客户端应用的离线支持
-
[12] 正态分布的前世今生(一)
-
[12] iTerm2 (Mac Terminal)
-
[11] Joomla反序列化漏洞的查漏补缺
-
[11] Linux内存中的Cache真的能被回收么?
-
[11] 在JavaScript中什么时候使用==是正
赞助商广告
