Linux下访问文件的基本模式
这篇讲的是Linux内核中几种常见的文件访问方式,作者从底层机制出发,对比了普通模式、同步模式、直接I/O、异步模式以及内存映射这五种模式的运作原理与核心差异。 普通模式依赖页高速缓存,读阻塞、写缓存即返回,是默认的平衡选择。同步模式则通过置位O_SYNC标志,强制写操作直到数据落盘才返回,代价是更高的延迟,但确保了数据持久性。直接I/O(O_DIRECT)完全绕过页高速缓存,在用户空间与磁盘间直接传输,适合数据库等需要自主管理缓存的场景。异步模式通过aio系列系统调用实现非阻塞I/O,进程提交请求后可立即返回处理其他任务,提升了并发处理能力。内存映射则通过mmap将文件映射到进程地址空间,把文件操作转化为内存操作,简化了编程模型并可能提升大文件访问效率。 文章清晰地拆解了每种模式下内核标志位的状态与数据流路径,帮助开发者理解不同I/O策略的适用场景——比如高性能存储系统可能倾向于直接I/O或异步模式,而追求开发简便性的应用则更适合内存映射。通过对比这些模式的适用场景和实现机制,文章为开发者提供了选择I/O策略的清晰指引。
大数据下的工行
这篇讲的是工行2013年那场著名的系统故障,作者从一条已消失的微博切入,还原了事件的全过程。故障发生在计划内数据库升级(DB2从V9升至V10)后的首个业务高峰,暴露出凌晨低负载测试无法完全模拟真实压力的问题。 文章的核心技术分析指出,问题可能源于IBM软件的内存清理缺陷,导致数据库主机CPU和内存迅速耗尽。作者站在DBA视角,还原了故障当时的决策困境:是冒险切换至未经充分验证的灾备中心(可能牺牲数据一致性),还是耗时更长但能保证数据完整地回退版本?理性选择了后者,这符合金融系统对CPA中一致性(C)的严格要求。 文中还穿插了作者亲历的2008年淘宝机房断电惊魂时刻,形成对比——成熟的容灾架构需通过定期实战演习来锻造,而非仅靠昂贵备库。最后,文章对工行将直接原因归咎于IBM软件缺陷的内部通报,留下了耐人寻味的评论。全文通过一个具体故障,探讨了大型系统运维中测试验证、灾备切换与故障复盘的真实逻辑。
解决进程间共享内存,由于某个进程异常退出导致死锁问题
这篇讲的是在进程间共享内存编程中,因某个进程异常退出而导致死锁的经典坑。作者从一个线上服务重启后的超时问题出发,层层排查,最终定位到根源:一个读进程在持有读写锁时突然崩溃,导致锁的计数器(`nr_readers`)没有递减,写进程因此永远等不到锁,共享内存数据无法更新,最终引发服务故障。 作者不仅用测试代码复现了这一问题,更深入探讨了如何解决。读写锁在这种场景下缺乏自动恢复机制。一个巧妙的出路是改用互斥锁,并设置其`PTHREAD_MUTEX_ROBUST_NP`属性(Robust锁)。当持锁进程死亡时,锁不会永久阻塞,而是返回`EOWNERDEAD`,后续线程调用`pthread_mutex_consistent_np`即可修复锁状态,使其恢复正常。此外,作者还提醒,通过共享内存交换数据时,务必增加完成标记,以确保数据在进程崩溃时不会处于不完整的中间状态。 文章从实际故障切入,完整呈现了“发现问题-分析根因-测试验证-寻求方案”的解决链条,特别是对Robust锁的应用,为处理跨进程的异常状态恢复提供了非常实用的思路。
JVM的GC简介和实例
这篇文章从JVM内存布局讲起,重点剖析了Java堆的分代模型——新生代如何划分Eden与Survivor区,以及Minor GC触发时基于复制算法的运作机制。作者通过一段简单代码和jstat监控,演示了在默认配置下,新对象如何优先在Eden区分配,当Eden空间不足时如何触发一次Minor GC,以及部分存活对象如何被直接晋升到老年代。整个过程配合真实的GC日志进行了拆解。 文章还简要介绍了Serial、ParNew、CMS等常见的垃圾收集器,并利用JVM参数(如-Xmn、-XX:SurvivorRatio)调整新生代配置,为后续对比不同收集器的行为埋下伏笔。它并非泛泛而谈理论,而是将“对象优先在Eden分配”、“大对象直接进入老年代”等原则,用可观察的内存变化和日志数据做了印证。对于想理解GC基本行为,或对“Minor GC后对象为何直接进入老年代”感到困惑的初学者,这份实战记录提供了清晰的图示和数据支撑。
数据的存储介质-磁盘的RAID
这篇讲的是如何通过RAID技术将多块磁盘组织起来,从而突破单盘性能与安全性的限制。作者从计算机存储的两个基本要素——通信管道与存储介质出发,引出RAID的核心思想:通过数据分区(Partition)提升吞吐量与IOPS,通过数据复制(Replication)保障安全。 文章清晰地对比了几种经典RAID模式。RAID0纯粹追求并行读写的速度,但毫无冗余;RAID1采用全盘镜像,安全但空间代价高昂。RAID5用XOR校验位巧妙地在安全与空间利用率间取得平衡。而现实中更常用的RAID10(1+0)与理论上更优的RAID01,文章通过图示和坏盘场景分析,点明了为何“先冗余后分区”的RAID10才是工程首选。 更深入一层,文章探讨了实现RAID的两种形态:依赖RAID卡、电池与SSD保障日志的单机方案,以及通过光纤通道、InfiniBand等协议连接的外部盘柜。最后,作者将视角延伸至分布式存储,指出HDFS、GFS等系统本质上借鉴了RAID10的思路,并点明了在上层已做复制切分时,底层再用传统RAID可能带来的冗余与性能损耗。

数据的存储介质-磁盘的硬件特性
这篇讲的是磁盘硬件的核心工作原理,作者从硬件决定软件性能的根本逻辑出发,带我们看懂这个既熟悉又陌生的“老古董”。他从磁盘的老祖宗——磁带机讲起,清晰解释了硬盘为实现“随机访问”而做出的关键设计:让磁介质盘片匀速旋转,由轻量化的磁头臂负责寻道移动,而不是反过来。 文章还深入了一个常被忽视但至关重要的细节:磁盘块的原子写入。它解释了磁盘如何保证在异常断电情况下数据不“写一半”,即通过开机时的检查与清理来维持逻辑一致性。这种“最大努力保证原子性”的思路,是理解单机存储一致性的基础。 对于容易混淆的IOPS(每秒读写操作数)和吞吐量(MB/秒),作者用“飞机运旅客”的生动比喻做了拆解。IOPS看重减少寻道和旋转延迟,适合数据库等小数据随机访问场景;吞吐量则擅长顺序大文件写入,比如视频存储。两者与延迟存在动态权衡关系。 整篇文章用通俗的语言和比喻,把磁盘的机械特性、数据组织方式以及性能指标的内在关联讲得明明白白。对于想优化存储性能或理解上层软件(如数据库、文件系统)行为的工程师来说,这是打下坚实基础的必要一课。

kmemcache源码浅析
这篇讲的是memcache的Linux内核移植版kmemcache的源码实现。作者深入分析了这个不走寻常路的高性能缓存项目,重点剖析了它如何摒弃了常见的epoll通知机制,转而利用网络数据包 skb 的回调函数,实现了更细粒度的 packet 级调度。 文章的核心在于揭示kmemcache独特的网络模型设计:一个dispatcher(调度器)与多个worker(工作线程)协同工作。其中dispatcher专门负责处理TCP和Unix域套接字,并将新建的连接分配给特定的worker;而所有的UDP请求也由这些worker直接处理。 在实现细节上,文章拆解了用户态守护进程umemcached与内核模块kmemcache.ko之间,如何通过Netlink机制完成启动参数传递等关键交互。作者结合具体的代码结构(如cn_entry、cn_queue),清晰地展示了“请求-应答”的同步通信流程,以及其中涉及的序列号管理和回调处理等巧妙设计。 整体来看,这是一篇扎实的内核级源码剖析,它不仅解释了kmemcache“做了什么”,更细致地拆解了它是“怎么做到的”,对于想理解Linux内核网络子系统优化或高性能缓存实现的读者来说,提供了非常具体的参考。
scribe的生产实践总结
作者结合两年生产实践,分享了对Facebook开源日志系统Scribe的应用总结。Scribe以精简稳定著称,作者团队在线上运行超过两年,未曾遭遇其自身进程崩溃。 文章核心聚焦于生产环境中Scribe的关键运维实践。针对Master节点宕机,标准配置是Primary接Secondary文件,故障时日志本地缓存,恢复后自动补发,并可通过一行脚本监控积压。为防止Scribe进程意外阻塞业务,建议采用异步线程写日志。而最棘手的情况是网络拥塞导致日志追送困难,作者提到一项压缩传输的改造尝试。文章最后将Scribe与LinkedIn开源的Kafka进行对比:Scribe如同“激流勇进”的冲锋舟,简单可靠;Kafka则似“航空母舰”,以集群和去中心化设计,对单点故障的容忍度更高。作者认为,对于中心化的日志收集场景,两者各有适用之处。
剖析网页字符集的设置顺序
这篇讲的是作者从一次电商网站数据迁移中遇到的顽固乱码问题出发,深入排查并最终厘清了网页字符集设置的优先级顺序。问题根源在于,影响浏览器字符集解读的因素不止一个,而开发者往往不清楚它们之间的覆盖关系。 作者通过实际测试,逐一验证了五种设置方式:文件编码、Apache2默认配置、PHP.ini配置、PHP脚本中的header函数以及HTML的meta标签。他设计了一个清晰的对比实验,例如同时设置header为gb2312、meta为utf8,观察显示结果,从而确定了基本的优先级。 最关键的发现在于,当服务器端的PHP.ini或Apache配置介入后,情况会变得更复杂。测试表明,php.ini中的默认字符集设置优先级最高,它会覆盖header函数的输出;而Apache2的默认设置优先级则高于meta标签,但低于header函数。 最终,文章得出了一个非常实用的优先级排序:php.ini默认设置 > header函数设置 > Apache2默认设置 > meta标签设置。搞清楚这个顺序,对于彻底解决因字符集配置冲突导致的乱码问题,提供了明确的排查路径。
用unix socket加速php-fpm、mysql、redis的连接
这篇文章探讨了在单机环境下,如何通过unix socket来优化php-fpm、mysql和redis的连接性能。作者从图虫服务器的单机运行现状出发,指出即使使用127.0.0.1本地IP,连接仍需经过TCP/IP层,引入不必要的开销;对于像图虫这样单机日处理2000万+动态请求的服务,切换到unix socket能直接绕过网络栈,实现更快的本地通信。 文章通过一个简单测试展示了立竿见影的效果:200次redis请求耗时从38ms降至27ms,这10毫秒的差距在高并发场景下足以驱动优化。配置方法也被详细列出——对于mysql(PDO),需在DS
中间件和稳定性平台
这篇文章全景式地展示了阿里技术体系中,保障大规模分布式系统稳定运行的核心中间件与平台。它不是一个孤立方案的介绍,而是一张完整的技术地图。 文章从配置、消息、服务、数据到性能监控,分层介绍了多个关键组件。例如,用Diamond实现配置的动态推送与超高可用,用Notify(推模型)和Meta(拉模型)满足不同的消息需求,用HSF统一RPC调用,并依靠eagleeye进行链路跟踪。数据层则通过TDDL实现SQL路由,用精卫、愚公等工具解决数据迁移与扩容难题。最后,持续稳定性平台CSP与TProfiler、Hotspot等工具共同构成了保障系统高可用的“运维三件套”。 整篇文章的价值在于,它清晰地勾勒出了一套应对高并发、大数据挑战的、经过生产验证的全家桶方案。对于希望理解超大规模互联网系统底层基础设施的读者来说,这提供了一个非常直接且具体的参照系。
如何设计一个优秀的API
这篇讲的是如何设计出经得起时间考验的优秀API。作者从两年API维护经验出发,直面了一个核心痛点:API一旦发布,修改成本极高,会直接影响用户信任与业务。因此,好的API设计至关重要。 文章提出了优秀API的几个关键特质:对用户而言要易学习、易使用且难误用;对开发者则要易阅读、易开发。要达到这些目标,作者总结了九条核心设计方法,比如面向用例设计、采用良好思路(如方法优于属性)、避免“必须漂亮”或“必须简单”等极端意见、进行有效评审、保证向后兼容以及把握API的生命周期。 其中,关于“向后兼容”的多层次实现和为API设定“分级”管理以实现平滑演进的观点,给出了非常具象的指导。文章最后还列举了Flickr、Ebay等实践良好的API案例作为参考。对于任何需要设计或维护接口的开发者来说,这篇基于实战的避坑与进阶指南都值得一读。
回调还是消息队列
这篇文章从作者封装Hive socket库时遇到的一个具体问题切入:如何处理底层`poll` API产生的事件。直接注入回调函数虽然直接,但容易引发异常、重入等不可控问题,且会加剧C/Lua边界的性能负担。 作者提出的方案是将事件及数据一次性返回给Lua层处理。为优化此方案可能带来的GC压力,他采用了一个预先传入的消息队列(一个空的Lua table)作为接收结构。在C层,通过高效的`rawseti`操作将消息逐条写入这个结构,并巧妙地利用一个缓存池来复用存储每条消息参数的小table,从而在系统稳定后避免了临时构建大型Lua表。 文章最后,作者还附上了一段极简的Lua消息队列实现代码,展示了其优雅的实现思路。整体而言,文章分享了一个从具体问题出发,在性能与可控性间权衡并最终优化实现的技术决策过程。
了解模块化开发
这篇从前端工程师小A的日常困扰讲起。他为了避免冲突,把公共函数封装到`_`对象里,结果还是和第三方库的`_`撞了车。接着,团队协作中又暴露了另一个大麻烦:组件`tabs.js`依赖另外两个文件,但使用者不仅要手动补全引用,还容易搞错加载顺序。更令人头疼的是,当`tabs.js`新增一个依赖后,所有引用它的页面都得跟着修改。 文章通过这两个具体场景,层层剥开传统前端开发中的痛点:全局变量污染就像房间里的“地雷”,而隐式依赖和脆弱的手动管理,则让代码维护变成了“排雷”与“走钢丝”的混合挑战。作者没有停留在问题表面,而是指向了模块化这个解药——它正是为了实现依赖的清晰声明与自动化管理,从而让代码结构更健壮、团队协作更顺畅。对于仍在为文件加载顺序和命名冲突头疼的开发者来说,理解这些“为什么”至关重要。
说说会话串号
这篇讲的是大型网站(以淘宝为例)中一种令人头疼的故障——“会话串号”,即用户意外登录到他人账号的现象。作者基于亲身的运维经历,剖析了几起真实案例。 文章首先区分了两种串号场景:一种是系统BUG导致的,用户不仅能看到别人页面,还能进行操作;另一种是缓存导致的,用户只能看到别人的页面但无法操作。重点在于前两种技术性串号:第一起源于Jboss的Tomcat在解析Request参数时存在BUG,可能读取到脏数据导致登录串号;第二起则是店铺系统在静态化改造时,缓存服务器错误地缓存了包含Set-Cookie的HTTP头,导致用户获得了一个他人的SessionID。 排查这类问题周期很长,因为难以重现且不易定位根因。为此,文章提出了一种主动防御思路:在Cookie中增加一个签名值,并在服务端会话框架中校验该签名。一旦检测到客户端与服务端的签名不一致,就清空会话并强制用户重新登录。这套机制旨在快速发现并阻断串号,将被动排查转为主动防御。
不同SSD盘组合搜索引擎单机性能测试[2013年版]
作者从搜索引擎单机性能优化的需求出发,在一台配置了24核Xeon E5 CPU、近50GB内存的Linux服务器上,对不同SSD盘组合策略下的HA3引擎性能进行了系统测试。测试数据规模可观,索引达59G,摘要73G。 文章详细对比了多种方案:从全内存基准、单盘SSD,到由两块或三块盘组成的RAID 0、RAID 1,以及不使用硬件RAID而采用软连接或数据分片的方式。测试严格控制了IO调度、预读、线程数等变量,并通过abench工具获取峰值QPS。 核心发现颇具实用价值:当索引量翻倍时,性能近似减半,表明IO是关键瓶颈。单纯增加RAID 0的磁盘数对搜索引擎引擎性能提升有限,瓶颈会转移至CPU锁开销。最引人注目的结论是,两块SSD盘不使用硬件RAID,而是通过软件将数据按term哈希键分片存储,能达到约18%的性能提升,优于RAID 0的12%提升,也远超传统的多段软连接方式。 文章最终给出了分层建议:在CPU性能制约时,应重点解决IO瓶颈(如采用多盘按term切分);当磁盘增多后,则需关注CPU锁优化。对于写入场景,也提出了普通盘与SSD搭配的实践方案。
页缓存概述
这篇讲的是Linux内核中一个关键性能优化组件——页缓存的工作原理与实现。作者将它比作硬件缓存的软件实现,核心思想是利用快速的主存来缓存慢速的磁盘数据,以此大幅减少I/O等待。 文章首先解释了页缓存的读写机制:读取时先查缓存,若未命中则加载并可能长期驻留;写入时则直接修改缓存中的“脏页”,并不立即写回磁盘,而是采用延迟写回的策略来合并多次修改。 实现上,内核面临两大挑战:如何快速找到特定缓存页,以及如何统一管理来自不同源(如文件、设备)的数据。文章深入剖析了address_space结构如何巧妙地解决这两个问题。它内部维护一棵radix优先搜索树,将所有属于同一所有者的缓存页组织起来,支持高效的查找、插入和删除。同时,通过a_ops钩子函数集,为不同数据源定义了统一的操作接口(如readpage、writepage),让上层逻辑与底层具体设备解耦。 最后,文章列出了内核提供的基本操作函数,如查找、分配、添加和移除缓存页,构成了操作页缓存的程序接口。整体来看,这篇文章从概念到实现,清晰地梳理了Linux内存管理中这一精巧的中间层设计。
malloc()之后,内核发生了什么?
作者从一个常见的用户空间操作出发,即进程调用 `malloc()` 后尝试访问内存,一路追踪到内核空间的真实发生过程。文章的核心在于揭示,用户感知到的“内存分配”在内核层面主要通过 `brk` 系统调用来实现,其背后是一套从修改堆描述符到最终响应缺页异常的精密机制。 讲解路径非常清晰:首先,`malloc()` 会触发 `brk` 系统调用,通过 `SYSCALL_DEFINE1(brk,...)` 服务例程来调整进程的堆边界。文中展示了该例程如何检查资源限制、对齐地址,并根据是扩大还是缩小堆,分别调用 `do_brk()` 或 `do_munmap()`。 文章的巧妙之处在于指出,此时内核通常并未立即分配物理内存。`do_brk()` 的核心工作是在进程的虚拟地址空间中分配或合并一个线性区间(VMA),为后续可能的操作“预留地盘”。真正的魔法发生在第二步:当进程首次访问这块新地址时,CPU 会因页表项无效而触发缺页异常。文章接着深入异常处理流程,从 `page_fault` 入口,到 `do_page_fault()` 判断异常类型,最终由 `handle_mm_fault()` 接手。 在 `handle_mm_fault()` 中,内核才开始真正“分配”物理内存——它确保页目录结构完整,然后调用 `handle_pte_fault()` 完成页框的分配与映射。整个过程生动地体现了 Linux 内存管理中“延迟分配”的核心思想:先给予虚拟承诺,待实际使用时再兑现物理资源,从而优化了内存使用效率。这对于理解内存分配的全链路至关重要。
zend php 动态数组
这篇讲的是如何从Zend PHP源码中学习动态数组的C语言实现。作者从C语言静态数组长度固定的痛点切入,指出在很多场景下我们无法预先知道数据规模,但又不想浪费内存预分配一个过大的数组。解决思路就是动态数组:先用malloc分配一块连续内存,通过指针像操作数组一样访问;当空间不足时,用realloc进行扩容(它会保留原有数据)。 文章的核心部分是剖析Zend PHP中动态数组的具体实现。作者展示了完整的头文件和源码,包括初始化、插入、获取、销毁等关键操作。其实现很巧妙:用一个结构体封装数组指针、元素大小、当前元素数和已分配容量;在push时,如果当前容量已满,就将容量翻倍进行realloc,确保了均摊下的高效插入;通过元素大小和偏移量计算,可以泛型地支持任意类型的数组。文末通过一个读取输入并输出的对比实验,直观展示了静态数组(固定缓冲区可能截断数据)和动态数组(随输入自动增长)在实际应用中的行为差异。
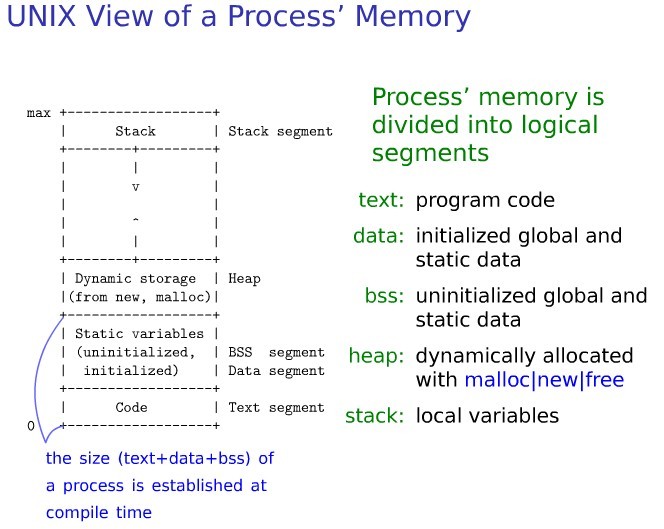
Linux内存点滴 用户进程内存空间
这篇详解Linux用户进程的内存空间,作者从大家熟悉的top命令输出讲起,解释了VIRT、RES等字段背后,其实是进程被内核分配的虚拟内存(VM)这一核心概念。 文章重点梳理了这块内存空间的构成,清晰地区分了Text(代码段)、Data、BSS、Heap(堆)和Stack(栈)这几个段的特性与用途,并通过多个C语言示例,生动演示了不同段数据的生命周期和访问权限差异——比如栈上变量在函数返回后失效,而堆内存则需手动释放以防泄露。 此外,文章还深入到底层,分析了malloc()函数通过brk()和mmap()系统调用分配内存的机制,并解释了“按需缺页”这一精妙的虚拟内存管理策略:首次访问时才分配物理页框,从而高效利用系统资源。最后,通过strace工具跟踪系统调用,直观展示了内存分配的实际过程。对于想从应用层迈向系统内核,理解Linux如何为进程管理内存的开发者,这篇内容提供了非常扎实的起点和细节剖析。