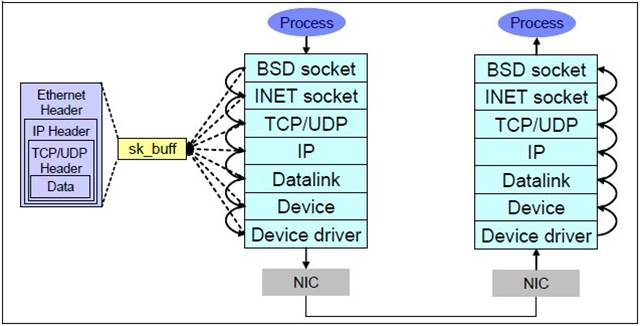
JVM垃圾收集器
这篇讲的是JVM中垃圾收集器的原理与选型。作者从垃圾收集是算法的具体实现出发,系统梳理了JDK 1.6时代的六种主流收集器。 文章的核心在于对比。它首先指出没有万能收集器,只有最合适的。Serial作为单线程基础款,适合客户端;ParNew是其多线程升级版,主要为了配合CMS;Parallel Scavenge则专注于吞吐量,适合后台计算任务。在老年代,Serial Old是单线程整理,Parallel Old实现了多线程整理以贯彻高吞吐思路。 重点落在两种并发收集器上。CMS以最短停顿为目标,通过并发标记清除实现,但面临CPU敏感、浮动垃圾和空间碎片问题。G1则带来了革命性改进:基于标记-整理,不产生碎片;通过将堆划分为多个Region并优先回收垃圾最多的区域,实现了可预测的、精确的停顿时间控制。 文章结合图示,清晰地展示了各收集器的适用年代、组合方式以及从Serial到G1,用户线程停顿时间不断缩短的发展脉络,为理解JVM内存管理提供了扎实的入门图景。
Servlet线程安全问题
这篇讲的是开发中容易踩到的陷阱:Servlet的线程安全问题。文章从Servlet默认的多线程执行模型切入,指出当多个线程并发访问同一个Servlet实例时,如果代码不当,会产生难以复现的bug。 作者用了一个很直观的代码案例:在service方法中使用了一个实例变量PrintWriter。当用户a和b几乎同时请求时,由于线程调度和共享实例变量,用户a的浏览器收到了空白页,而a的信息却错误地显示在了用户b的页面上。文章进而从Java内存模型(JMM)的角度,分析了线程工作内存与主内存的同步延迟,如何导致了这一问题的随机性与危险性。 针对该问题,文章总结了三种解决方案:一是实现SingleThreadModel接口(但已被废弃,且不能解决所有问题);二是使用synchronized关键字同步代码块;最根本的,是避免在Servlet中使用实例变量,将需要的数据作为局部变量处理。这对于理解Web容器如何执行Servlet,以及如何编写可靠的并发代码,都是很好的一课。
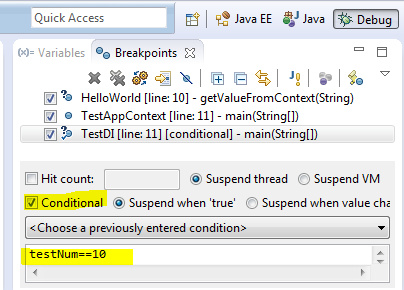
Java程序员应该知道的10个eclipse调试技巧
这是一篇面向Java开发者的Eclipse调试技巧系统性梳理。文章开篇就给出了三个高优先级建议:放弃System.out.println,转而启用并分析组件日志。核心内容则围绕十个具体、可操作的调试功能展开。 作者从基础的条件断点、异常断点讲起,逐步深入到监视点、变量值修改等高级操作。特别值得一提的是对“Drop to Frame”(返回堆栈帧)功能的讲解,它能让程序状态“回档”以便重复调试,但作者也提醒了其可能带来的副作用。最后,文章对F5、F6、F7、F8这四个最核心的调试快捷键进行了清晰归类,是入门和巩固的必备知识。 整篇文章的实用性很强,不仅罗列了“是什么”,更通过具体场景说明了“怎么用”以及“注意什么”,旨在帮助开发者更高效、精准地定位代码问题。
java中byte转换int时为何与0xff进行与运算
这篇讲的是Java开发中一个具体但容易踩坑的技术点:将byte数组转换为十六进制字符串时,为何要对每个字节先进行与`0xFF`的按位与运算。 作者直接从代码出发,点出看似多余的`& 0xFF`操作,并设问为何不能简单地将byte强转为int。其核心原因在于Java中byte(8位)与int(32位)的位数差异,以及计算机采用补码表示负数。当一个负数byte(如`-1`,二进制补码为`11111111`)被扩展为int时,会进行符号位填充,得到`0xFFFFFFFF`,这显然不是我们期望的原始字节对应的无符号数值。 与`0xFF`(二进制低8位为1,高24位为0)进行与运算,正是为了清除扩展产生的高位比特,强制将结果限制在低8位内,从而确保得到的是字节的正确无符号值(如`255`)。文章通过复习补码知识和举例说明,清晰地阐释了这一操作的必要性,是理解Java基本数据类型转换细节的一个好示例。
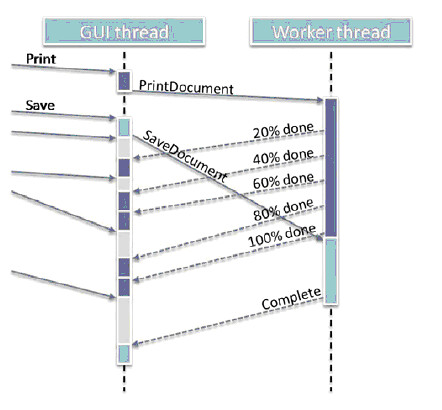
多核与异步并行
这篇讲的是如何通过异步并行编程技术来充分利用多核CPU,解决现代应用程序面临的延迟、吞吐量和响应度问题。 作者从一个经典矛盾切入:当程序调用耗时的I/O操作(如写文件)时,同步等待会让宝贵的CPU资源闲置。而异步调用允许调用线程立即返回继续工作,让耗时的任务在后台完成,从而“掩盖”了I/O延迟。 文章重点分析了GUI线程的异步并行设计,这是一个对响应度要求极高的场景。作者对比了三种将耗时操作(如保存、打印)从GUI线程转移出去的方式:使用一个专用工作线程顺序处理、为每个请求启动新线程并行处理,以及使用线程池来平衡资源利用与并行度。每种方式都附有清晰的示意图和伪代码,直观展示了其工作原理与权衡。 最后,文章以苹果的Grand Central Dispatch (GCD) 为例,说明了这一理念在现代平台上的成熟应用——开发者只需将任务块投入队列,系统便能自动利用多核资源进行高效调度。整体而言,这是一篇从原理到实践、讲解异步并行如何化阻塞为并发的技术入门好文。
程序语言之争与Java社区文化
这篇文章从持续不断的程序语言之争出发,探讨了技术选型的核心困惑:语言A能做的事,语言B是否也能做?如果都能,哪个更方便?作者没有用图灵机理论来论证,而是以JVM平台上的Java、Groovy、Scala为例,从技术与非技术两个层面展开了一场深入对比。 在技术层面,文章聚焦于动态与静态语言的权衡,以及Visitor模式与函数式语言模式匹配在不同场景下的优劣。作者指出,语言的特性多寡、将功能实现在语言层还是框架层,都是设计时需要考量的哲学问题。例如,C#倾向于将特性集成到语言中,而Java则更依赖于框架生态。 文章的落脚点在于Java独特的社区文化。作者认为,Java语言本身的“简单死板”反而成就了一个分工明确、层次丰富的生态系统:语言保持基础,由IDE弥补开发体验,由框架提供高级抽象,最终让各层次的开发者各司其职。这种“君弱臣强”的模式,与微软社区“君强臣弱”的模式形成有趣对比,为理解技术生态的演化提供了独特的视角。
HTTP协议Keep-Alive模式详解
这篇讲的是HTTP协议中的一个关键性能优化机制——Keep-Alive模式。作者从HTTP“请求-应答”的本质出发,对比了默认断开的普通连接和持久化的Keep-Alive连接。 在普通模式下,每一次请求都要单独建立和关闭TCP连接,开销很大。而启用Keep-Alive后,连接会被重用,避免了重复握手的损耗。文章指出,HTTP 1.0默认关闭此特性,需要手动开启;而从1.1开始,这已是默认行为,服务器是否支持决定了实际效果。 文章的重点分析了Keep-Alive如何判断消息传输完成。由于连接不会自动断开,不能依赖EOF信号。作者详细解释了两种标准方法:一是通过`Content-Length`头部明确告知数据长度;二是使用`Transfer-Encoding: chunked`进行分块编码传输,尤其适用于动态生成的内容。文中甚至给出了chunk编码的具体格式示例。 此外,文章还梳理了RFC标准中消息长度的优先级判定规则,并附录了常见的HTTP头字段解释。可以看出,Keep-Alive并非简单的“保持连接”,而是一套涉及连接复用、数据完整性和协议协商的完整方案,其优势在于节省CPU与内存、支持请求管道化、降低网络拥塞和延迟。理解它,是深入掌握现代HTTP性能调优的基础。
JVM内存分配与回收策略
这篇讲的是JVM中对象内存分配的“潜规则”,作者从最基础的规则出发,通过具体的代码示例和GC日志,带你看清内存分配的真实行为。 文章核心围绕三个关键策略展开:一是对象优先在Eden区分配,当Eden空间不足时就会触发Minor GC;二是大对象会绕过新生代,直接被“安置”在老年代,这可以通过`-XX:PretenureSizeThreshold`参数来控制;三是长期存活的对象会从新生代“晋升”到老年代,其阈值由`-XX:MaxTenuringThreshold`决定。 作者并没有停留在理论描述,而是为每个规则都准备了可运行的代码和对应的GC输出日志。比如,通过对比设置`MaxTenuringThreshold`为1和15时不同的GC结果,你能直观地看到对象年龄计数器如何影响晋升行为。这种用实验数据说话的方式,让这些抽象的内存管理机制变得非常具体和可验证。
需不需要备案、应该怎么备案、备案应该找谁?(2013年版)
国内站长对备案常感困惑,政策复杂,难以理清。这篇文章就从这个常见痛点出发,通过大量实例,把备案的规则讲透了。 文章的核心观点非常明确:备案的本质不是备域名或主机,而是“备人”——即在中国境内提供web服务的网站所有者,需要向主管机关报备。理解这一点,是厘清所有问题的关键。 接着,文章通过“张三”、“李四”等不同角色的具体案例,清晰对比了何时需要备案、何时不需要。例如,使用境外或香港服务器则无需备案,而使用境内服务器就必须备案;即使是.cn域名,也可以通过申请“境外解析”来避免备案。这些例子让抽象的政策变得一目了然。 对于站长最关心的“找谁备案”问题,文章也给出了直接答案:备案必须通过接入商(主机商)进行,而域名注册商不提供此服务。所需资料因地区而异,个人通常需身份证和照片。 最后,文章还特别澄清了“大中华cn域名必须备案才能解析”的坊间传闻,指出注册者可以申请境外解析或非网站用途解析。
并发框架Disruptor译文
这篇讲的是Martin Fowler撰文推荐的高性能并发框架Disruptor,它正是LMAX交易系统能实现每秒600万订单的核心引擎。作者从“为什么会这么快”切入,剖析了传统锁机制的缺点,然后详细拆解了Disruptor的几大“魔法”:通过精心的缓存行填充避免伪共享、利用内存屏障保证无锁操作的正确性,并深入讲解了RingBuffer这个核心数据结构如何实现高效的读写。 文章不仅解释了原理,还提供了具体的使用指南,涵盖了从RingBuffer读取、写入到版本演进的完整路径。最后,通过LMAX架构和实际处理百万TPS的案例,展示了它在解决高并发、低延迟场景下的巨大价值。对于想理解无锁编程和设计高性能内存队列的开发者,这组系统性的译文提供了从理论到实践的清晰线索。
Nginx模块fastcgi_cache的几个注意点
这篇讲的是,作者在配置Nginx的fastcgi_cache模块时,明明参数都设对了,缓存却一直不生效、状态始终是MISS的诡异经历。通过strace工具抓包后,他发现是Discuz论坛程序默认返回的 `Cache-Control: no-cache` 响应头,直接导致Nginx放弃了缓存。 作者没有停留在表面,而是深入到Nginx源码层面,找到了关键的判断逻辑。他总结出:当fastcgi响应头中包含 `Set-Cookie`、`Expires` 时间过早或 `Cache-Control` 指向不缓存时,即使配置了cache,Nginx也会直接跳过。文章清晰地展示了从“配置无误却不生效”到“抓包定位干扰源”,再到“查阅源码验证规则”的完整排查链路。 对于实际运维或开发人员,这提醒我们:缓存是一个“端到端”的决策过程,上游应用的“不缓存”响应头拥有最高优先级。文末附带的Nginx配置示例和缓存状态头调试方法,也为快速定位类似问题提供了实用工具。
VIM插件管理及python开发环境配置
这是一篇作者在公司内部做的技术分享,核心是解决新手面对VIM时无从下手、Python开发环境配置繁琐的痛点。文章没有停留在理论层面,而是直接提供了一套经过实践检验的“抄作业”方案。 作者首先建议备份原有配置,然后详细展示了自己的.vimrc文件配置过程。关键点在于使用Vundle这个插件管理器,通过几行命令即可自动安装和管理如jedi-vim(Python智能补全)、nerdtree(文件树)、ctrlp(模糊文件搜索)等一系列提升编码效率的必备插件。配置中还包含了实用的基本设置,比如用空格代替Tab、配置状态栏显示Git和语法检查状态等。 这套方案的目的很明确:让开发者能快速跳过繁琐的“造轮子”阶段,获得一个开箱即用的高效开发环境。对于希望利用VIM进行Python开发,但又被初始配置劝退的读者来说,这份可直接复用的配置清单和配套PPT提供了清晰的行动路径。
发布及其检查的自动化实践
这篇讲的是,一个服务实例超过35K的大型Dubbo注册中心,在频繁发布中遇到的棘手挑战及其实战解决方案。作者从一次因人工配置错误导致的严重事故出发,分享了如何通过持续的自动化改进,让发布过程从“危险重重”变得可靠。 文章聚焦四个具体痛点:数据库配置错乱、发布前后服务数据一致性核对、运行时状态报告集成,以及重启引发的动态数据风暴。针对每个问题,都给出了清晰的“解决方法”和提炼出的“原则”。例如,通过监控配置文件的值来防止环境错配;在发布脚本中集成数据Dump和Diff,实现Provider列表的自动核对;将关键状态汇总到一个URL,方便监控;并设计了“warm-up”机制来平滑重启过程。 作者强调,核心思路是将“人操作可能出错”的环节,逐步转化为可监控、可自动执行的脚本。最终目标是让发布回归极简,理想情况下仅需运行一条命令,而把异常情况下的排查留给必要的时候。整个过程体现了从发现问题、分析根因到工具化、自动化解决的工程化实践闭环。
Sentry: 错误日志集中管理
这篇讲的是如何用Sentry搭建一个集中式的错误日志管理系统。Sentry本身是一个Python编写的开源项目,它能捕获程序运行中的错误详情,并提供一个清晰的Web界面进行查看和分析,支持Python、PHP、Ruby、iOS等多种语言。 文章的核心是手把手介绍如何部署和使用。作者从安装开始讲起,用`pip install sentry`即可启动安装流程,但也提到了实际过程中可能遇到依赖问题,比如Django版本不匹配,可能需要手动处理依赖或使用virtualenv来隔离环境。配置部分展示了如何生成配置文件并调整启动参数,例如设置为daemon模式后台运行。 配置完成后,只需一条`sentry start`命令就能启动服务。文章还以Django项目为例,说明了客户端如何集成——通过安装raven客户端并在配置中加入Sentry的DSN密钥,就能自动将应用异常上报到服务器。对于不想自建服务器的用户,作者也提及可以考虑使用Sentry的官方托管服务。 整个过程体现了Sentry的价值:把分散在各处的错误“一站式”管理起来,降低排查成本。对于团队协作和运维监控来说,是一个很实用的基础设施。
内存异常排查
这是一篇典型的故障排查与技术思考文章。作者参与排查一个C++程序的崩溃问题:一个包含百余个对象指针的vector,在对象析构时发现第95个指针异常,偏移了1-3字节,导致程序崩溃。 文章的核心在于作者层层递进的推断逻辑。从对象声明为const、仅读取的特性,排除了人为改写和常见的内存越界写入可能。指针地址非对齐(变为奇数)且仅此一处异常,让作者将怀疑重点转向了更隐蔽的“悬空指针”问题。他推断,可能是某个已被引用计数机制正确析构释放的对象,其内存被新对象复用后,残留的旧指针在析构链中被意外调用,其减引用操作误将后来对象的数据当作计数值进行递减,最终导致了这起离奇的崩溃。 作者最终给出的排查建议也极具针对性:为所有涉及引用计数的操作(包括标准库智能指针)添加断言,确保引用值在合理范围内,以防悬空指针的二次破坏。文章结尾,作者还延伸吐槽了C++生态中项目对高性能内存分配器的强依赖,并反思了语言“信任程序员”背后可能引致的工程混乱问题。
HTTP KeepAlive,开启还是关闭
这篇文章讨论了HTTP KeepAlive在现代网络环境下的实际价值。作者从传统的认知出发——即开启Keep-Alive可以通过复用TCP连接来减少开销,提升用户体验——但随即结合高带宽低延迟的现实条件和现代浏览器的并行加载策略,对这一观点提出了质疑。 文中通过展示一台Nginx服务器的Status数据,给出了一个非常具象的反例:该服务器开启KeepAlive后,平均每个连接只处理了约1.01个请求,几乎没有实现有效的连接复用。由此引出一个关键洞察:KeepAlive的益处并非普适。对于客户端偶尔访问一次的WebService类应用,维持长连接反而会浪费服务器资源,此时关闭它才是更优的选择。 作者最终引导读者跳出教条,结合自身服务的实际访问模式(如连接复用率、并发需求等)来重新评估这个配置项,而非盲目地沿用“最佳实践”。
什么是NAT
这篇讲的是NAT——网络地址转换,一个为解决IPv4地址不够用而生的核心网络技术。作者从一个“理想很丰满,现实很骨感”的个人学习故事切入,用了一个“小马哥管公司”的生动类比,把地址稀缺和分级管理的逻辑讲得挺明白。 文章直接点出了NAT要解决的关键矛盾:公网地址有限,但内网设备(比如家里、公司里的电脑)需要上网通信。解决方案是划出几个特定的私有IP地址段(如192.168.x.x),允许内网重复使用,然后由NAT设备(通常集成在路由器里)来“翻译”地址。当内网设备要访问公网时,路由器会把它数据包的源地址,悄悄换成自己拥有的那个唯一的公网IP地址。 更深入一层,文章还解释了NAT如何利用TCP/UDP的端口号,来区分同一内网下不同设备发出的数据流。它通过维护一张“内网IP+端口”到“公网IP+虚拟端口”的映射表,确保返回的数据能准确送回原来的那台设备。这种对协议现有字段的巧妙复用,让NAT在不改变底层IP协议的情况下,打通了内外网的通信桥梁。 总的来说,作者用接地气的语言和比喻,把NAT这个略显枯燥的概念拆解清楚了,核心就是它如何通过地址和端口的转换,在地址不足的现实下,让海量内网设备得以顺利接入互联网。
get_adjacent_post函数PHP源码阅读笔记
这篇文章解读了WordPress中`get_adjacent_post`函数的实现。虽然函数有效代码仅70行左右,但作为获取相邻文章的核心逻辑,它包含了数据库查询构建、参数处理和缓存优化等典型Web后端设计思路。 作者从函数签名切入,清晰拆解了三个参数的作用:是否限定相同分类、排除特定分类、以及指定获取前一篇还是后一篇。函数的三种返回状态也被明确点出,这直接反映了代码的健壮性设计。 核心实现部分展示了如何动态构建SQL查询。特别值得注意的是两点:其一,代码利用`$wpdb`全局变量进行数据库操作,这是WordPress封装的标准方式;其二,通过`apply_filters`为查询的JOIN、WHERE和ORDER BY部分留出了扩展点,允许主题或插件自定义查询逻辑,这是WordPress强大灵活性的体现。 最后,函数引入了对象缓存机制,通过`wp_cache_get`和`wp_cache_set`避免重复查询数据库,在频繁调用时能显著提升性能。这些细节让一个看似简单的函数变得值得细读。
Java Crypto在Linux下性能低下问题的解决方案
这篇讲的是Java Crypto在Linux下性能低下问题的解决方案。作者从实际踩坑经验出发,发现使用java.security包中的方法(比如SecureKeyFactory.generateSecret())时,执行异常缓慢,有时甚至陷入半僵死状态。问题的根源在于Linux系统默认的securerandom.source配置(指向/dev/urandom),其随机数生成效率较差,拖累了整个加密操作流程。 为了解决这个棘手问题,文章提供了两种经过验证的实用方法。第一种是直接编辑JRE目录下的java.security文件,将securerandom.source的值改为file:/dev/./urandom——这个微妙的路径调整能绕过性能瓶颈。第二种则更彻底:通过yum安装rng-tools工具包,并配置rngd服务来增强系统随机数源。具体包括设置EXTRAOPTIONS参数、启用开机自启和重启服务,以提升/dev/random设备的可用性。 这些针对性调整虽然简单,却能显著优化Java加密操作的响应速度。如果你在Linux服务器上运行Java应用时遇到类似卡顿,不妨从配置层面入手,往往能收到立竿见影的效果。
dropwatch 网络协议栈丢包检查利器
这篇讲的是,当Linux服务器出现网络超时,用tcpdump或wireshark抓包能看到丢包,但往往很难定位到内核协议栈深处的具体丢包位置。作者介绍了一个专门解决此痛点的利器:dropwatch。 dropwatch的核心能力是精准定位数据包在Linux网络协议栈中“被丢弃”的内核函数位置。文章演示了在RHEL系系统上,通过简单的yum安装后,以交互模式启动`dropwatch -l kas`,就能实时看到诸如`netlink_unicast`、`unix_stream_recvmsg`等函数的丢包计数,并直接对应到内核源码,大大缩小了排查范围。 它的原理巧妙地利用了内核的kprobe机制。工具会监控内核中关键的`kfree_skb`函数调用(该函数在协议栈多个层次被用于释放数据包)。当监控到此函数被调用时,即视为一次丢包,dropwatch会记录并通知用户空间显示发生丢包的内核函数符号信息。文章还指出,要让dropwatch工作,内核需要打特定的补丁以区分“正常释放”和“丢包释放”,并通过Netlink将信息传递给用户空间。对于运维和网络开发人员来说,这是一个深入内核腹地、直击丢包根源的高效诊断工具。