用户成长体系漫谈
这篇讲的是如何为网站设计用户成长体系。作者从几个国内典型网站出发,拆解了它们各自的成长体系设计思路与背后的逻辑。 文章对比了微博、QQ、豆瓣、知乎等平台的做法。比如,微博的成长体系紧密围绕其媒体战略,通过粉丝量、V认证和勋章来塑造和展示“牛人”,核心是满足用户的自我营销需求。腾讯QQ则依靠在线时长累积成长值,并结合虚拟币(Q币)消费,驱动力更多源于用户在社交圈中的虚拟身份满足感。相比之下,豆瓣的成长体系最为“隐藏”,它通过“小豆”和内容推荐,让用户在兴趣参与中自然体现价值,而非刻意追求等级,这体现了其产品气质。 作者指出,没有普适的公式,成长体系必须服务于产品定位。淘宝的等级与积分直接绑定交易,是电商驱动交易的典型;而知乎通过邀请码的稀缺性和基于专业认可的“关注”,构建了高质量社区的门槛。这些案例共同揭示了一个核心:好的成长体系,是将平台的商业目标与用户的核心价值感巧妙融合,无论是社交荣耀、内容贡献还是实际利益。
PHP中return的用法
这篇讲的是PHP中`return`语句一个常被忽略的实用技巧。作者在研究Yii框架的配置文件时,注意到一个直接在脚本文件顶层返回数组的写法,这让他重新查阅了PHP官方文档。 原来,`return`不仅可以终止函数执行,当在全局作用域(即脚本文件的顶层)调用时,它能立即终止整个脚本文件的执行。更重要的是,如果该脚本是被`include`或`require`引入的,`return`后面的值会直接作为引入语句的返回值。 这个特性带来了一种更清晰、更直接的配置管理模式。对比传统的写法——在配置文件中定义一个全局数组变量,然后在其他地方通过`global`关键字去访问——新方式只需一行`$config = require('./config.php');`,就能直接获得配置数组。 这种做法避免了全局变量的污染,让数据的流向在引入那一刻就变得明确无误,代码也更为整洁。对于需要集中管理配置项的应用来说,这无疑是一个值得借鉴的实践。
两个精彩的比喻:吞吐量和延迟、信号量和互斥锁
这篇文章通过两个极其形象的比喻,澄清了计算机领域两对容易混淆的概念:吞吐量与延迟、信号量与互斥锁。 对于吞吐量和延迟,作者用ATM取钱打比方。一个人完成取款的时间是延迟,而整个银行每分钟能服务的人数是吞吐量。比喻生动地说明,增加ATM机数量(提高并行度)可以在延迟不变的情况下大幅提升吞吐量;而取钱后填写问卷(增加串行步骤)则会显著增加延迟,但吞吐量可能保持不变。这清晰地揭示了两者的核心区别:延迟衡量单个任务的体验,吞吐量衡量系统的整体产能。 关于信号量和互斥锁,作者改进了常见的“钥匙”比喻。互斥锁是独占的钥匙,拿到的人拥有唯一打开权。信号量则是一个大公共厕所门口的“可用/已满”指示牌,它代表的是可并发进入的资源数。文章特别指出了原比喻的不足,并用改进后的“牌子”比喻说清了关键差异:二元信号量的牌子(状态标志)可以被任何人翻动,而互斥锁的钥匙只能由拥有者打开。这个细微差别,正对应了状态协作与资源独占的不同使用场景。
PHP业务逻辑层和数据访问层设计
这篇讲的是PHP项目中如何合理设计业务逻辑层与数据访问层。作者从面向对象的基本原则出发,探讨了在MVC架构下,模型(Model)层究竟该承担什么职责。 文章指出,项目规模和复杂度决定了分层的必要性。对于业务简单、数据库固定的小项目,采用表模块或活动记录模式将业务逻辑与数据访问合并,反而更高效。但随着需求膨胀,就需要清晰划分:业务逻辑层应基于“领域模型”来实现,专注于对象属性与行为的描述;数据访问层则为业务层提供数据支持。 在数据访问层的具体模式选择上,作者对比了表数据入口、行数据入口、活动记录和数据映射器等经典方案。考虑到PHP语言特性(如灵活的数组操作、开发者对SQL的偏好)以及多数项目数据库变动少的现实,作者认为“表数据入口”模式是更务实的选择。最终结论是,理想的PHP应用架构是:用领域模型构建业务逻辑,通过表数据入口模式实现数据访问层,让开发能更专注于领域行为本身。
你必须了解的Session的本质
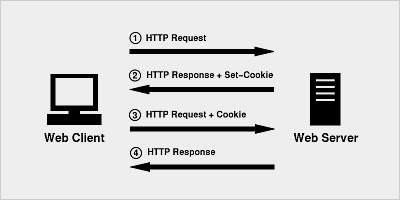
这篇讲的是PHP中Session的本质与安全陷阱。作者从HTTP协议无状态性这一底层特性切入,解释了为什么我们需要Session来维持应用状态。他详细拆解了Cookie作为HTTP扩展的工作原理,以及Session ID如何在客户端与服务器之间传递——无论是通过自动的Set-Cookie头,还是通过URL参数或POST数据。 文章特别强调,许多开发者误以为PHP内置的Session机制自动提供了安全性,但事实并非如此。作者通过一个具体的会话劫持攻击示例(攻击者窃取并重放PHPSESSID),清晰地展示了如果仅依赖默认机制,会话数据将面临风险。他指出,安全必须由开发者主动加固,而非框架自动保障。 整体上,这篇文章像一份面向PHP开发者的安全指南,从协议基础讲到实战风险,核心观点是:理解Session背后的网络交互细节,是构建安全会话管理的第一步。
域名相关的一些基本概念总结
这篇技术博客系统梳理了互联网基础设施中的核心概念——DNS及其相关配置。文章从DNS(域名系统)的底层作用讲起,解释了它如何将人类可读的域名翻译为机器所需的IP地址,并特别强调了DNS服务器数量(通常至少两个)对解析稳定性的意义。 内容重点对比了A记录、AAAA记录、CNAME记录、MX记录和TXT记录等关键DNS记录类型。例如,A记录直接将域名指向IPv4地址,而CNAME则为域名创建别名,便于管理;MX记录专用于指定邮件服务器,是搭建企业邮箱的关键;TXT记录则常用于SPF反垃圾邮件验证。文章还厘清了子域名、泛解析(覆盖所有未定义的子域名)与域名绑定(将域名关联到特定服务器空间)之间的区别与应用场景。 对于需要管理域名的开发者或运维人员而言,理解这些概念的差异和适用条件,能更精准地完成网站部署、邮件服务配置或流量调度,避免常见的配置疏漏。
accept_ra 的一个例子
这篇讲的是作者在配置Jumbo Frame时遇到的一个IPv6特有坑点。两台主机和交换机都已将MTU改为9000,但IPv6通信始终失败,不断收到“包太大”的ICMPv6报错。作者排查发现,IPv6路由器的RA包中会周期性广播一个MTU值(这里为1500),这个值会直接覆盖主机本地计算出的PMTU,导致大包无法发出。 问题的根源在于IPv6与IPv4的关键差异:IPv6路由器不分片,发送方主机必须基于整条路径的最小MTU(即PMTU)来调整包大小。而交换机虽然能转发巨帧,但其路由接口的MTU固定为1500,这个值通过RA被主机接收,不断重置了有效的PMTU。作者最终的解决方案是:在相关网络接口上禁用`accept_ra`选项,阻止主机接收和处理RA包中的MTU信息,转而通过DHCPv6来获取IP地址。这个案例清晰地展示了IPv6无状态地址自动配置机制与自定义网络配置之间可能出现的冲突。
TSQ 的原理
这篇技术文章深入剖析了Linux内核网络栈中一个精巧的机制:TCP Small Queue (TSQ)。作者从一个常见疑问出发——既然已经有了`tcp_wmem`限制TCP层队列,为何还需要TSQ?以此引出关键:数据包从TCP层到网卡要经过多个队列,TSQ旨在更全面地控制排队延迟。 文章的核心在于对两个内核函数的源码级解读。其一是`tcp_wfree`,作为网络套接字缓冲区的析构函数,它巧妙地在缓冲区即将被丢弃时“截胡”,检查特定标志位后将套接字重新加入TSQ队列调度。其二是`tcp_tasklet_func`,它处理队列中的套接字,并根据其是否被用户进程持有来决定立即发送或推迟至`release_sock()`。 TSQ的巧妙之处在于,它没有直接维护一个可计算长度的独立队列,而是“寄生”于内核网络路径的关键节点(如缓冲区释放和套接字关闭)来间接判断队列空间是否充裕,以此实现动态的发送限速。这种设计展现了对TCP内部运作机制的深刻洞察。
进程运行于不同的 CPU 核
这篇文章讲的是,如何在多核服务器上,让关键进程更高效地利用 CPU 资源。作者从用 Gearman 搭建 Map/Reduce 的实战场景出发,发现启动多个 daemon 进程后,需要确保它们能够分散运行在不同 CPU 核心上,以避免资源争抢、提升整体性能。 文章的核心方案是利用“CPU 亲和性”,将进程绑定到指定的 CPU 核心。作者不仅展示了如何使用 `taskset` 命令,将已运行的进程或通过脚本启动的进程分配到 CPU#0、#1、#2 上,还特别指出了 Nginx 的配置方式——它支持在 `nginx.conf` 中通过 `worker_cpu_affinity` 为每个工作进程精确绑定 CPU 核心,这是一种更优雅的管理方法。 从基本的 `taskset` 命令操作,到深入探讨 `sched_setaffinity` 系统调用和进程继承机制,文章给出了从“知道怎么做”到“理解为什么”的完整路径。对于追求高并发性能的后端开发者而言,这种对服务器硬件资源进行细粒度控制的能力,是优化服务稳定性和吞吐量的实用技巧。

Java正则引发的思考
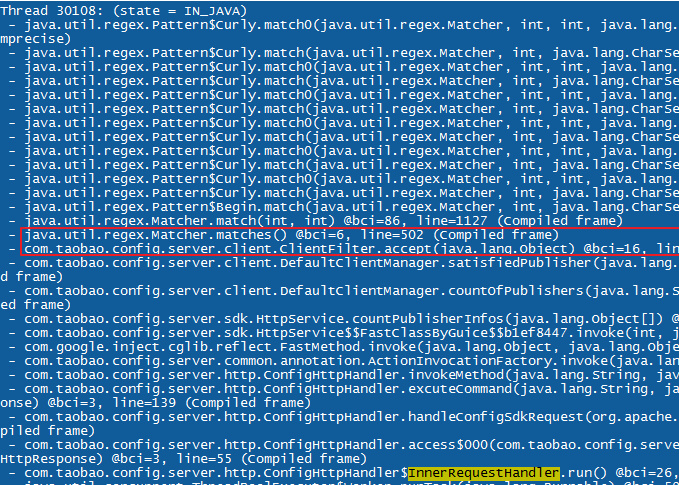
这篇讲的是一个由正则表达式引发的线上故障排查与深度分析。 作者从预发环境CPU不定时飙升至100%的问题出发,通过jstack分析,发现业务线程全部卡在正则匹配的代码上。排查发现,问题根源在于一段看似无害的用户输入,经过代码规范化后,形成类似“`.*.*.*.*.*.*.*Deliver`”的正则模式,与特定长字符串匹配时导致了“假死”。 文章深入剖析了Java正则引擎在“贪婪模式(greedy)”下的工作机制。作者用一个简化的正则“`.*.*.*.*D`”和36个字符的字符串为例,图解了引擎在遇到多个通配符“`.*`”时,会如何进行大量回溯尝试,最终指出其匹配步数会呈现指数级增长(公式为 `S(m, n) = n + Σ S(m-1, n-i)` for `i=1 to n-1`)。为了验证这一理论推导,作者还巧妙地运用ASM字节码注入技术,在JDK正则匹配的核心方法上埋点,实测了匹配步数,结果与理论计算完全吻合。 这篇文章的价值在于,它清晰地揭示了Java正则引擎在处理特定贪婪模式通配符时可能存在的性能陷阱。对于开发者而言,这是一个重要的警示:在处理外部输入构造正则时,必须避免此类多重通配符的模式,否则可能引发难以预料和排查的严重性能问题。
JsonCpp使用优化
这篇讲的是如何为高性能需求场景优化JsonCpp库。作者从项目实战中发现,尽管JsonCpp接口简洁,但在频繁操作JSON数据时性能不尽如人意。文章深入分析了其内部实现,指出operator[]函数开销较大以及std::map查找效率不如哈希表等瓶颈,并尝试修改源码未果。 因此,作者将重点放在了可观测的优化手段上。通过编写基准测试程序,他对比了三种不同使用方式的性能差异:默认的append、复用Value对象并用下标赋值、以及使用StaticString避免拷贝。测试表明,后两种方法能带来一倍以上的性能提升。 更进一步,作者调整了JsonCpp的编译选项,加入“O2”优化参数,使性能再次显著提高。他还尝试在源码中为Value类新增setValue函数,绕过标准接口的类型转换开销,最终让处理耗时从最初的约4900微秒降至约570微秒,配合静态链接还能略有增益。 文章通过具体代码和实测数据,展示了从编译器、使用模式到源码级的多层次优化路径,为需要压榨JsonCpp性能的开发者提供了清晰可复现的实践参考。
管理Gearman
这篇讲的是如何从零开始,上手管理和监控 Gearman 任务队列。作者没有停留在概念层面,而是直接从一个最简单的 PHP Worker 实例代码切入,带你运行起来,并解释了代码中看似“死循环”却不会耗尽资源的内在机制——Gearman 扩展内部已实现了智能等待。 文章的核心价值在于解决实际问题:启动多个 Worker 后,到底应该开多少个?作者给出了答案,即利用 Gearman 自带的状态查询命令 `(echo status; sleep 0.1) | nc 127.0.0.1 4730`。他详细解读了返回结果中“队列任务数”、“运行中任务数”和“可用 Worker 数”等关键指标的含义,并指出如何根据这些数据来动态调整 Worker 数量,实现资源的合理利用。 最后,文章还点出了生产环境中常见的进程管理难题,如代码更新后自动重启、Worker 意外退出等,并推荐了 Supervisor 和 GearmanManager 等工具作为进阶方案。整体上,这是一篇非常务实的入门到管理的实践指南。
稳定性思考-强弱依赖2
这篇文章从一个实际问题切入:在微服务架构中,如何为弱依赖(如Cache)设置合理的“并发请求数阈值”?作者的分析思路很清晰,核心目标是实现高QPS下的资源消耗最小化,即“高QPS,少线程”。 作者通过一个Cache访问案例,结合公式 QPS=1000/RT * threadNum,做了生动的故障推演。正常时1个线程就能支撑400QPS;一旦Cache故障、RT飙升至3000ms,理论上就需要1200个线程,这会导致调用方线程池耗尽、频繁FullGC,陷入恶性循环。 为此,文章提出的核心方案是:限制访问弱依赖的线程数。例如,将阈值设为10。这样在上述故障中,调用方只会阻塞10个线程,整体服务保持正常,实现优雅降级。结合超时设置,能形成更有效的流控策略。 那么阈值设多少?文章给出了计算方法:根据可接受的RT(如100ms)和目标QPS(400)反推,得到 threadNum = 400 * 100 / 1000 = 40。作者也分享了经验数据:平均50ms的APP,阈值一般不超过60。文章最后点明,响应时间变长往往源于排队,而系统的最高QPS由瓶颈资源决定,盲目增加线程未必有用。
稳定性思考-强弱依赖
这篇讲的是系统稳定性中一个核心却容易被忽视的点:如何正确处理系统间的依赖关系。作者从淘宝复杂的系统依赖场景出发,将依赖清晰地划分为“强依赖”与“弱依赖”,并剖析了二者对系统稳定性的迥异影响。 对于强依赖,文章指出其风险在于“一荣俱荣,一损俱损”。除了主张通过扩展通道来解耦,作者更通过一个生动的分流压测案例揭示了关键发现:一个单机容量为4的系统,在被过载压垮后,其容量会急剧下降至约2.5,且自身难以快速恢复。这源于资源耗尽导致的线程堆积与频繁Full GC,深刻说明了对下游依赖系统进行“流量保护”的必要性。 文章接着探讨了更优的“弱依赖”模式。它细分为两种场景:一是主流程无需等待结果的异步化调用;二是需要等待结果但通过设置超时与最大并发阀值来熔断保护。这两种方式都能在B系统故障时,确保核心链路A的稳定运行。 整体而言,作者用从理论到压测实证,再到具体技术方案的递进逻辑,为如何设计高可用系统提供了极具操作性的指导。
使用gdb调试运行时的程序小技巧
这篇讲的是开发者用GDB调试正在运行的程序时,那些常常让人头疼的场景和作者摸索出的实用解法。文章开门见山,直指三个高频痛点:如何在不中断服务的情况下探查程序状态、如何高效地批量查看变量和Core文件、以及如何“透视”链表或树这类复杂数据结构。 作者没有停留在理论,而是给出了一套完整的“武器库”。针对第一个场景,他分享了一个精巧的`runstack.sh`脚本,通过一行命令就能附加到目标进程,查看甚至修改全局变量的值,而无需重启服务。对于需要批量操作的场景,他展示了如何编写GDB脚本(.gdb文件)来一次性执行多个调试命令,以及如何改造脚本来快速分析多个Core文件的堆栈,快速归类问题。文章还附上了完整的测试代码和用例,从编译到执行,手把手演示效果。 这些技巧源于对Systemtap等工具复杂性的规避,和对生产环境调试需求的深刻理解。作者提供的不仅是几个命令,更是一套结合了Shell与GDB的轻量级工作流,能帮助开发者在复杂的线上环境中更安全、更高效地定位和解决问题。
三种代理服务器的区别
这篇讲的是三种代理服务器的区别:标准代理、透明代理与反向代理。 作者从它们的工作机制和应用场景出发,做了清晰的对比。标准代理需要用户主动配置浏览器,主要作用是缓存静态内容,为企业或局域网用户节省带宽。透明代理则对用户完全“透明”,无需配置,由网络设备(如路由器)在80端口直接截获HTTP流量进行缓存,这在ISP和简单局域网加速场景中很常见。 而反向代理的工作重点完全不同,它面向服务器端,被架设在Web服务器前端,主要目的是缓存服务器生成的动态或静态内容,直接响应大量请求,从而显著减轻后端服务器的负载压力,提升网站整体性能。 文章的亮点在于没有止步于理论对比。后半部分详细演示了如何使用Apache搭建一个反向代理服务器,以解决“如何用一台公网服务器(A)代理访问内网其他服务器(B、C)”的实际问题。内容涵盖了模块启用、VirtualHost配置等具体步骤,非常实用。 总的来说,这篇既讲清了三种代理的“是什么”和“为什么”,又通过实例说明了“怎么用”,对于理解网络架构和解决服务器部署问题都有参考价值。
TCP/IP 相关总结
这篇讲的是TCP/IP协议栈的经典模型对比。作者从TCP/IP四层模型出发,清晰地列出了每一层的代表性协议,比如应用层的HTTP和DNS,传输层的TCP和UDP。文章随后引入了OSI七层模型,并将两者进行并排比较,直观地揭示了关键差异:TCP/IP的应用层实际上整合了OSI应用层、表示层和会话层的功能,这是一个非常核心的简化与实用主义设计。 此外,文章开篇就扎实地回顾了TCP三次握手建立连接的完整过程,从SYN包发送到SYN+ACK回应,再到最后的ACK确认,讲得很清楚。虽然文章还提及了IP地址分类,但其核心价值在于对这两套网络分层模型的拆解与对照,帮助读者理解网络通信框架从理论模型(OSI)到实际协议栈(TCP/IP)的演变与取舍。搞明白这些区别,对于理解网络通信的本质很有帮助。
LVS hash size解决4096个并发的问题
这篇讲的是如何解决LVS在高并发场景下因默认哈希表过小而导致的性能瓶颈问题。 文章指出,LVS用于记录连接信息的connection hash table默认仅有4096条目(可通过`ipvsadm -ln`查看)。当并发连接数远大于此值时,会发生频繁的哈希冲突与置换,显著增加系统负载。作者在CentOS 5.4环境下,演示了通过重新编译内核来扩展此限制的具体方法。 核心操作是获取系统对应的内核源码包,在编译配置中将`CONFIG_IP_VS_TAB_BITS`参数从默认的12(对应2^12=4096)修改为20(对应2^20=1048576)。使用原有配置进行编译,能确保仅改变哈希表大小而不影响内核其他功能。编译安装新内核并重启后,哈希表大小成功扩展至超过百万级。 作者也分享了实用经验:为应对业务增长,他通常直接将该值设为最大的20。同时提醒,每个连接都会占用内存(约136字节),即使LVS理论性能可达百万级,也需确保服务器有足够的内存资源来支撑。
BufferedIO和DirectIO混用导致的脏页回写问题
这篇文章源于一次线上问题排查:曲山同学遇到系统性能抖动,最终发现罪魁祸首是 BufferedIO 与 DirectIO 的混用引发的脏页回写风暴。文章详细拆解了问题机制——当文件同时存在两种 I/O 访问路径时,操作系统对脏页的回写策略可能被扰乱,导致大量不必要的刷盘操作与延迟毛刺。作者不仅定位了内核页缓存与 IO 调度层的交互细节,还给出了具体的规避方案:比如统一 I/O 模型、调整文件系统挂载参数,或对关键路径做隔离。对于需要高性能存储或处理海量数据的应用开发者来说,这个案例清晰地展示了底层 IO 选择可能带来的隐性坑点,以及如何通过系统性的分析来规避类似风险。
qperf测量网络带宽和延迟
这篇文章聚焦于如何使用qperf工具准确测量网络性能参数。作者指出,虽然我们了解网络设备的理论规格,但在实际部署中,网卡驱动、交换机跳数、丢包率以及协议栈配置等因素都会显著影响实际的带宽和延迟表现,而这些参数直接关系到request-response类协议的最大QPS和系统承载能力。 文中详细介绍了qperf工具在实际场景中的应用价值——它能够穿透理论值的迷雾,帮助开发者或运维人员获取真实的网络基准数据。这种实测对于诊断性能瓶颈、优化服务器配置以及验证网络变更效果都至关重要。 通过将理论预期与实测结果进行对比,文章揭示了网络环境的复杂性,并强调了基于真实测量数据进行决策的重要性。对于需要精确掌控网络性能的技术团队来说,这提供了一种实用且直接的评估方法。