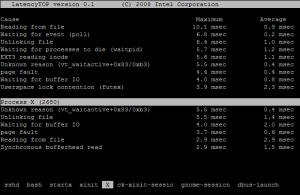
latencytop深度了解你的Linux系统的延迟
这篇讲的是如何精准定位Linux系统中那些“说不清道不明”的性能延迟。当多线程程序效率低下,常规监控工具(比如dstat)只能告诉你上下文切换频繁,却无法揭示背后真正的“元凶”时,文章引出了一个专门工具——latencytop。 作者从性能优化的常见困境出发:我们知道系统在忙,知道切换很多,但不知道是谁在切换、为了什么切换。dstat能统计切换次数,systemtap能采样频率,但它们都缺乏对延迟源头的直接洞察。文章的核心在于介绍latencytop如何破解这个困局——它能深入内核,捕获那些导致延迟的具体操作和系统调用栈,把延迟的来源和调用栈直接摆在你面前。 对于系统管理员和性能工程师来说,这意味着分析上下文切换问题时,不再需要凭经验猜测或进行繁琐的手动追踪。latencytop让排查过程变得更有针对性,能直接告诉你“哪个进程”、“在做什么操作”、“等待什么资源”,从而快速定位到锁竞争、I/O阻塞或调度器问题。这对于优化高并发应用的响应能力,有着非常直接的实战价值。
systemtap全局变量自动打印的原因和解决方法
这篇讲的是在使用SystemTap进行动态追踪时,一个让人困惑的现象:明明只定义了全局变量,却在终端被意外地打印出来。作者从实际排查过程出发,分析了根本原因——SystemTap的内置机制会在探测点结束时,自动打印所有全局变量的最终值,这本意是为了调试方便,却可能成为脚本输出的“噪音”。文章详细剖析了这一行为的具体机制,并给出了两种清晰的解决方法:一是利用局部变量来替代需要临时存储的全局变量;二是通过显式声明来禁止特定全局变量的自动打印。最终,通过调整变量作用域和使用`%`修饰符,能彻底掌控输出内容,让SystemTap脚本的输出更干净、更符合预期。
systemtap函数调用栈信息不齐的原因和解决方法
在内核调试中,当想追踪一个关键函数的调用路径时,systemtap 常常是我们手中的利器。不过,就像代码里有时会埋着意想不到的坑,这个工具输出的调用栈信息,有时也会“缺胳膊少腿”,只给你半截链路,让排查工作卡在半路。 这篇文章正是从一个具体的抓取示例出发,剖析了 systemtap 输出调用栈信息不全的常见原因。它深入解释了问题背后的根源,比如符号信息缺失、内核编译配置差异等,这些都可能导致栈帧在输出中“断裂”。更重要的是,文章提供了切实可行的解决方法,包括如何正确加载调试符号、设置哪些环境变量等,帮助你把这条断了的链条重新接上。对于需要使用 systemtap 进行内核调试的技术人员来说,这篇内容直接戳中了实践中的一个痛点。
systemtap观察page_cache的使用情况
在规划服务器内存时,准确预估pagecache的使用量是个常见痛点,因为预留过多会导致内存浪费,不足又可能拖累性能。这篇从实际运维需求切入,介绍了如何用systemtap工具动态观察内核中page_cache的行为。作者没有泛泛而谈,而是演示了编写systemtap探针脚本的具体步骤,例如跟踪页缓存分配、释放事件,以及监控缓存命中率的关键指标。这种方案的核心在于非侵入式采集数据,能在生产环境中安全运行,帮助开发者获得真实负载下的缓存使用模式。文章进一步结合了案例数据,说明通过分析监控结果,可以更精准地设定内存预留值,从而优化整体资源利用。这种基于实测的规划方法,为系统调优提供了扎实的数据支撑。
Linux下新系统调用sync_file_range
这篇讨论的是数据库或IO密集型程序中的一个经典矛盾:数据持久性的保证与写入性能之间的权衡。 作者从常见的数据库更新操作切入,指出频繁调用fsync/fdatasync虽然安全,但会带来显著的性能开销。文章的核心是引出并剖析了sync_file_range这一系统调用。它的关键优势在于灵活性和效率:允许程序只将文件特定范围的脏页刷入磁盘,无需像传统方式那样以固定块为单位全量同步,也规避了不必要的元数据更新。这正好契合了那些“只关心特定数据页持久化,不涉及元数据变更”的高频更新场景。 文章通过对比传统方法与sync_file_range的机制差异,清晰地阐述了后者为何能在保证必要持久性的同时,有效缓解频繁同步带来的IO压力。最后,文章探讨了在何种具体的开发模式下,这一新系统调用能带来最直接的性能收益。
ftrace和它的前端工具trace-cmd
作者在调查无锁环形缓冲区(lockless ring_buffer)的实现时,偶然发现了 Linux 内核中强大的追踪框架——ftrace。这篇文章正是基于这次实际探索,详细拆解了 ftrace 的工作原理及其核心组件。 文章重点分析了 ftrace 如何通过内核中的“tracefs”文件系统暴露接口,并巧妙地利用无锁环形缓冲区来高效收集内核函数调用、中断等事件,确保在高负载下性能影响最小化。同时,也介绍了其前端命令行工具 trace-cmd,它极大地简化了 ftrace 复杂的配置和输出解析过程,让开发者能更直观地记录、查看和分析追踪事件。 对于需要深入理解内核行为、定位性能瓶颈或死锁问题的开发者而言,这篇文章清晰地展示了 ftrace 这一内窥镜从原理到实践的全貌,是掌握底层系统调试方法的一次扎实导读。
itop更方便的了解Linux下中断情况
作者从网络程序开发中监控系统性能的实际需求出发,指出在优化程序时,开发者经常需要精确掌握中断和软中断的实时分布情况,例如每秒的中断次数以及它们具体发生在哪个CPU核心上。传统的查看方式可能较为繁琐或信息不够直观。 这篇介绍的核心工具是 `itop`。它相比直接查看 `/proc/interrupts` 等静态文件,提供了更动态、更友好的实时视图。文章通过具体场景说明,使用 `itop` 可以快速刷新并直观看到中断计数、CPU分布以及软中断的负载情况,这对于快速诊断中断不均衡或系统瓶颈问题尤为有效。 总的来说,这篇文章为需要实时监控Linux中断情况的网络开发者或系统运维人员,提供了一个轻量、高效的诊断工具选择,帮助他们从繁杂的数据中迅速聚焦关键指标。
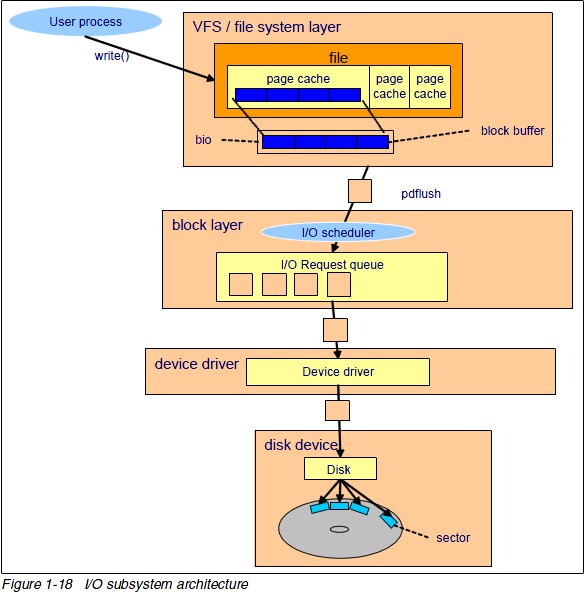
blktrace 深度了解linux系统的IO运作
这篇讲的是 blktrace 这个 Linux 下相对小众但极其强大的块层 IO 跟踪工具。作者没有停留在工具的基本用法上,而是深入讲解了如何利用它真正理解系统底层的 IO 流动。文章核心在于揭示 blktrace 与 iostat、perf 等更常见工具的区别:前者能让你像看地图一样,追踪一个 IO 请求从应用程序发起,经过文件系统、通用块层,最终到达具体设备的全过程,包括每个环节的耗时和队列状态。 作者详细展示了 blktrace 的输出格式和常用分析工具(如 blkparse、btt),并通过真实案例演示了如何从海量事件日志中,定位出“谁在何时对哪个设备发起了什么操作”、“IO 在哪个队列里排队过久”这类具体问题。这使得它在诊断复杂的 IO 性能瓶颈(如设备利用率高但响应慢)时,比仅能提供聚合统计信息的工具要精准得多。 文章最终将工具价值落到了实战层面:当你怀疑系统存在不规则的 IO 模式、需要优化特定应用的 IO 路径,或者想从根源上理解一次磁盘性能抖动的来龙去脉时,blktrace 提供的这种“逐帧回放”能力,能让排查过程事半功倍。
使用Aspersa洞悉Linux系统软硬件配置
这篇讲的是如何在接手陌生Linux服务器时,快速摸清系统底细。很多开发者都遇到过这种情况:老大扔给你一台机器就要上手开发,但软件往往依赖特定硬件特性,如果不了解CPU指令集、内存配置、磁盘IO模型这些底层信息,就难以进行针对性优化,甚至可能踩坑。 文章介绍的Aspersa就是为解决这个痛点而生。它其实是一组轻量脚本集合,能一键收集包括内核版本、CPU特性、内存布局、磁盘分区乃至RAID配置在内的关键软硬件信息。作者特别指出,比起手动敲一堆lscpu、lsblk命令,Aspersa的价值在于它能自动关联信息——比如它会告诉你哪些磁盘组成了RAID阵列,每个分区的挂载点和使用情况,这对于快速评估存储性能和规划部署路径非常实用。 对于需要快速适应新服务器环境的开发者或运维人员来说,这相当于拿到了一份系统的“体检报告”。无论是做性能调优前摸底,还是排查环境问题时确认基础配置,这个工具都能节省大量排查时间,让你把精力集中在真正的开发任务上。
例证NIF使用的误区
这篇文章深入剖析了 Erlang/OTP 中 NIF(原生函数接口)的典型使用误区。NIF 作为一种将 C 代码嵌入 Erlang 模块以提升性能或复用遗留代码的强力工具,其强大背后也隐藏着不少陷阱。 作者从“通常同学们会无视手册里的一句话”这个常见现象切入,指出许多开发者只关注 NIF 能“做什么”,却忽略了它“不该做什么”或“需要注意什么”的关键限制。文章没有停留在理论,而是通过具体的例证,揭示了在性能提升的诱惑下,开发者容易如何误用 NIF,比如可能破坏调度器的均衡性、引入难以调试的内存问题,或是陷入不必要的复杂性中。 其核心结论是,NIF 是一把锋利的“双刃剑”,仅在真正需要且理解其全部约束的场景下使用才是上策。对于那些只需简单扩展或性能要求并非极端的情况,Erlang 本身或其他更安全的机制或许是更好的选择。这篇文章的价值在于,它提醒技术决策者,在拥抱高性能工具前,必须全面权衡其带来的收益与潜在风险。
ioprofile调查应用IO情况的利器
这篇讲的是一个能直接回答“我的应用到底在怎么读写磁盘”这个问题的工具——ioprofile。 在对MySQL这类IO密集型应用做性能调优时,我们常常陷入一种困境:知道系统慢,却不清楚数据访问的真实模式。是顺序读多还是随机写多?大文件操作集中在哪个时段?缺乏这些基础数据,调优就像盲人摸象。这篇文章从实际的调优场景出发,介绍了ioprofile这个工具如何解决这个痛点。 它不同于简单的iostat观察,而是能挂载到目标进程上,精准地追踪每一次IO系统调用,并按照读/写、顺序/随机、文件大小等多个维度进行分类统计。通过ioprofile,开发者能清晰地看到工作负载(workload)的具体画像,从而为调整应用逻辑、优化数据库配置(如InnoDB的缓冲池和刷盘策略)提供无可辩驳的数据依据。 文章的核心价值在于,它把一个看似底层、专业的观测手段,变成了一个可以指导上层应用优化的实用方法论。
调查服务器响应时间的利器 tcprstat
在服务器性能优化中,准确测量请求响应时间是定位问题和提升效率的关键。作者从实际开发场景出发,指出了两种常见方法的局限性:传统代码日志计算时间忽略了数据在网卡与应用程序之间的传输耗时,导致结果不准确;而使用wireshark或tcpdump抓包虽能手动统计,但过程繁琐且难以持续,不适合频繁分析。 针对这些痛点,文章聚焦于介绍一款名为tcprstat的工具,它被设计为最小化操作成本的解决方案。tcprstat通过直接监控TCP层响应时间,能够覆盖从网络入口到应用处理的全链路,避免了时间漏测的问题。作者强调,该工具以轻量化的方式自动化数据采集,显著降低了人工干预的需求,从而让性能调查变得更高效。 通过对比传统手段,tcprstat在准确性和易用性上展现出明显优势,为开发者提供了一个实用利器。对于需要深入剖析服务器响应瓶颈的团队,这篇文章清晰地展示了如何利用这一工具简化工作流程,实现更可靠的时间测量。
Linux下pstack的实现
这篇讲的是Linux下排查进程状态时一个经典工具——pstack背后的实现原理。当我们发现程序行为异常时,最直接的方法就是看看它此刻正在执行哪些函数调用,pstack正是为此而生。
文章从pstack的基本使用场景切入,剖析了它是如何通过ptrace系统调用附着到目标进程,进而遍历其所有线程并获取每个线程的调用栈。核心实现巧妙利用了内核提供的/proc/
Tsung用于压测MySQL服务器的脚本
这篇文章来自一个实际的数据库性能优化场景。作者从一台MySQL服务器的压测需求出发,没有选择常见的benchmark工具,而是采用了更灵活的开源压测框架Tsung,并配合自己编写的Erlang脚本来模拟真实业务中的复杂SQL语句和连接模式。 文章的核心在于展示如何利用Tsung的可扩展性。作者详细说明了脚本的设计思路,包括如何从实际业务日志中提取高频SQL、如何通过Tsung的模块化结构来组织测试用例,以及如何动态调整并发数与压力梯度。通过这个方案,测试人员能够更精准地复现线上可能遇到的慢查询和连接池瓶颈。 最终,这套脚本帮助团队发现了几个特定的配置问题,比如连接超时设置不当导致的假性连接泄漏,并为后续的参数调优提供了可靠的数据支撑。对于需要进行定制化、场景化数据库压力测试的工程师来说,这个将Tsung与MySQL结合的实践路径提供了一个可参考的实现思路。