关于绘制统计曲线算法的一些思考
这篇讲的是 fuload 项目压力测试结果可视化过程中,对绘制调用时间统计曲线算法的具体思考。作者从实际的数据上报场景切入,指出核心问题在于如何处理海量且时间分布不均的原始数据,并将其转化为有意义的曲线。 分析采用自顶向下的框架,将问题清晰地拆解为数据输入与图形输出两部分。在输入侧,作者探讨了上报的时间粒度与数据格式;而在输出侧,则聚焦于如何设计绘制算法。摘要中可以点明,这不仅是简单连线,而是涉及如何选取统计区间、如何聚合与采样数据,从而在图表中既准确反映整体趋势,又不丢失关键波动细节的权衡过程。文章通过具体的项目实践,将抽象的算法选择与实际工程约束结合起来进行了剖析。
python与c-跨语言级别的进程间通信
这篇文章从一个实际项目——用Python做胶水语言的压力测试框架fuload的开发需求切入,探讨了Python与C进程间通信的经典问题。 作者首先分析了这类场景的典型架构:一个主进程负责管理,多个处理进程负责具体工作,两者需要解耦。在传统的C实现中,通常通过fork加上execv来创建并管理子进程。然而,对于Python而言,存在更现代、更简洁的解决方案。 文章的核心是介绍Python 2.4引入的subprocess模块。作者指出,通过这个模块的Popen类,可以免去繁琐的系统调用,用一行代码就能启动并管理C编写的处理进程。不仅如此,它还提供了清晰的方式(如stdin/stdout管道)来让Python主进程与这些C子进程进行数据交换和控制,完美实现了“用Python做主进程启动、控制多个C处理进程”的设计目标。 对于需要在Python项目中整合其他语言编写的高性能处理模块的开发者来说,这篇分享提供了直接且实用的实现思路。
抽离CodeIgniter的数据库访问类!
这篇技术文章聚焦于在CodeIgniter框架中重构数据库访问层,以应对一个实际架构挑战。作者从自身项目需求出发,提到业务逻辑相对顺畅,但管理层要求为数据访问层添加登录态验证,目的是实现“上层保护下层,但下层不完全信任上层”的安全设计原则。这一背景引出了如何在现有PHP代码中优雅地实现这一隔离的问题。 文章核心探讨了两种可行的方案来抽离数据库访问类。方案一可能涉及在模型层或控制器中直接注入验证逻辑,但会带来代码耦合度高的风险;方案二则倾向于通过设计模式(如装饰器或中间件)将登录态检查独立为组件,从而保持数据库访问类的纯净性和可复用性。作者通过对比两种方式的实现复杂度、性能影响和维护成本,突出了在大型项目中选择模块化架构的优势。 最终,文章得出结论:通过抽离并封装登录态验证逻辑到独立类中,不仅提升了代码的可测试性和安全性,还为后续扩展其他横切关注点(如日志或缓存)提供了灵活基础。作者分享了这一重构过程中的实践经验,为面临类似架构决策的开发者提供了具体思路。
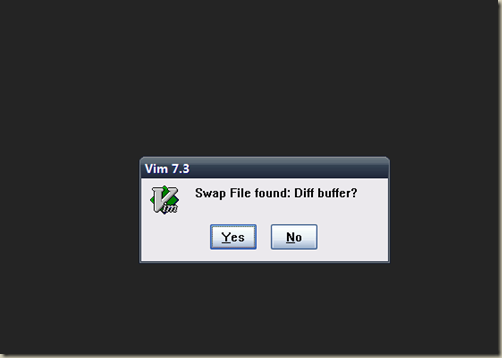
Vim(gvim)在recover时支持diff
Vim的自动保存功能(.swp文件)本意是在异常退出时挽救未保存的工作,但再次打开文件时,用户只能面对一个“是否恢复”的简单提示,根本无从知晓恢复后的版本与原本丢失的内容到底有何差别。 这篇介绍的 recover.vim 插件,正是为了填补这个信息差。它的核心思路是在恢复文件时,自动将恢复出的内容与磁盘上可能存在的旧版本(或空文件)进行 diff 对比,让用户能直观地看到每一处被找回的修改。 文章以 Windows 下的 gvim 7.3 为例进行演示:新建一个 C++ 文件并写入内容但不保存,模拟异常情况后,展示 recover.vim 如何激活差异对比界面。这样一来,用户就能在真正合并恢复内容前,清晰判断哪些改动是值得保留的,避免了盲目恢复带来的混乱。对于长期使用 Vim 的开发者而言,这个插件让原本“开盲盒”式的恢复过程变得可控和透明。
关于负载均衡和过载保护的一些想法和实现
这篇讲的是作者为线上服务器增加过载保护功能时,对负载均衡机制进行的实践思考。作者认为负载均衡的核心是根据目标服务器的参数——如失败率、响应时间或请求量——进行合理分配。 文章从最简单的轮询式算法切入,结合代码讲解了其直接逻辑,并以此为基础逐步探讨了更复杂的实现方案。作者没有停留在理论对比,而是紧扣“增加过载保护”这个具体需求,分享了在实际系统中如何考虑和选择不同负载均衡策略的思路。这种从一个实际功能点出发,延伸对经典机制再思考和实现的过程,对正在设计类似系统的工程师来说,提供了一个清晰且可参考的视角。
python中对时间处理的几个函数
这篇文章聚焦于一个非常实际的编程议题:在Python中如何优雅地处理时间。作者从C/C++开发者熟悉的unix时间戳出发,自然过渡到Python生态下的时间处理哲学。文章核心对比了两种主流思路:一是Python标准库中datetime模块提供的结构化时间操作,它读写友好、可读性强;二是利用第三方库如Arrow或Pendulum,它们以更人性化、链式调用的API极大简化了时间的计算、格式化与时区转换。 文章并未停留在API罗列,而是深入讲解了关键差异点。例如,datetime对象与时间戳的互转逻辑、字符串格式化指令(strftime/strptime)的常见陷阱,以及处理时区这个老大难问题时,datetime模块的局限性与第三方库的便捷性对比。通过具体代码场景,作者展示了如何避免手动计算时差带来的错误,以及如何根据项目需求(是需要轻量级方案还是全面功能)做出合适选择。 对于需要在日常开发中频繁与时间打交道、尤其是处理跨时区业务的Python开发者而言,这篇文章提供了清晰的选择路径和实战参考,能帮助读者从“能用”迈向“好用”。
在C++中实现foreach循环,比for_each更简洁!
这篇讲的是作者如何为C++实现一个更顺手的foreach循环。作者的出发点很直接:Python、C#、Java都有的简洁循环语法,C++虽然有STL的`std::for_each`,但用起来总觉得不够直观,于是动手自己写了一个。 文章首先回顾了`std::for_each`这个“前辈”,它面向算法,是函数式的写法。而作者自己实现的目标,是追求像其他语言那样直接用`for(auto x : container)`一样的简洁感,让代码在遍历时一目了然。为了实现这一点,作者利用了C++的模板和自动类型推导(auto)特性,核心思路是让自定义的结构能够接收一个范围(比如容器),并正确地将元素类型传递给循环体。 实现过程中的一个巧妙点在于对迭代器的抽象和封装,作者让这个自定义结构既支持数组,也支持各类STL容器,达到了通用的效果。最终得到的语法,确实比嵌套使用算法和lambda要清爽很多,更符合现代C++追求的清晰表达意图的风格。
一个简单的stl中string的split函数
当Python开发者转向C++时,常常会怀念`split`这样的便捷函数——虽然STL功能强大,但并未直接提供这种常用的字符串分割操作。这篇文章正是从这个常见的“缺口”出发,展示了一个轻量级、实用的`split`函数实现。 作者的思路很直接:利用`std::string`的`find`方法配合迭代器,高效地遍历字符串并定位分隔符。核心巧妙之处在于对边界情况的处理,比如连续分隔符和字符串首尾的分隔符,确保分割结果的准确性。实现代码短小精悍,没有复杂的模板元编程,却覆盖了大多数实际应用场景。 这个方案避免了引入大型第三方库(如Boost),仅依赖STL标准组件,非常适合嵌入现有项目或用于教学示例。对于需要在C++中处理配置读取、日志解析或文本处理的开发者,这提供了一个即拿即用的参考实现。
关于mysql_free_result和mysql_close的解惑
这篇讲的是 PHP 中两个容易混淆的 MySQL 函数——`mysql_free_result` 和 `mysql_close` 的正确使用场景。 作者从自己过去的一个编程习惯出发:在使用短链接时,每次调用 `mysql_store_result` 获取查询结果后,都会直接进行释放操作。这引发了后续的疑问:这两个函数到底是不是一回事?是不是每次操作都需要调用它们?文章的核心就在于厘清这两者的本质区别。`mysql_free_result` 的职责非常单一,它只负责释放由 `mysql_store_result` 生成的结果集所占用的内存。而 `mysql_close` 则是关闭与 MySQL 服务器的连接,终结整个会话。文章澄清了一个常见的误区:如果使用的是长链接并希望复用连接,那么只释放结果集(`mysql_free_result`)是正确的做法;而如果确实是短链接,或者在脚本执行完毕前确认不再使用该连接,则应当调用 `mysql_close` 来正确关闭它,释放服务器端资源。 读完这篇,能清晰地意识到:根据链接的复用策略来决定资源释放的粒度,是编写健壮、高效数据库交互代码的一个重要细节。
关于类成员函数指针的正确写法
这篇讲的是类成员函数指针这个看似简单、实则容易踩坑的C++知识点。作者从日常编程中“函数指针用法简单”这一普遍印象切入,随即指出类成员函数指针的特殊性——它不能简单套用普通函数指针的写法,因为背后隐藏着对象实例的调用约定问题。 文章核心对比了普通函数指针与成员函数指针在声明、赋值和调用上的关键差异。作者详细拆解了正确的声明语法,解释了为何需要`&ClassName::Function`这样明确指定类域,并剖析了通过对象或对象指针调用成员函数指针时,编译器在底层是如何传递`this`指针的。这些细节恰恰是很多初学者混淆和出错的地方。 通过具体的代码示例,文章清晰地展示了错误写法导致的编译失败或未定义行为,并给出了安全、可靠的正确模式。最后总结出要点:掌握成员函数指针的关键在于理解其与类实例绑定的本质,这不仅是为了语法正确,更是为了写出健壮、可维护的代码。
一道不错的算法题-判断链表是否有环
这篇讲的是作者从朋友的一道面试题说起,介绍了链表成环检测的经典解法。文章没有直接抛出答案,而是先引导思考——如何判断一个链表是否成环? 作者对比了两种主流思路。一种是使用哈希表记录遍历过的节点,虽然直观但空间复杂度为 O(n)。更巧妙的是快慢指针法:让快指针每次走两步、慢指针每次走一步,如果存在环,它们终会相遇。这个方法只用常数空间,背后的数学原理也值得细品。 文章把一个经典问题讲得清晰透彻,既点出了不同解法的权衡,也让人体会到算法设计中“空间换时间”之外的另一条优雅路径。这种问题在面试和实际开发中都很常见,值得花时间理解透彻。
c、cpp中使用匿名结构体、类定义数组
作者在阅读《Unix网络编程》时发现了一个有趣的C/C++用法:直接用匿名结构体定义变量,而无需提前声明一个命名类型。 通常我们习惯先定义`struct MyData { ... }`,再用`MyData array[10]`。但书中有一处代码直接使用了`struct { int id; char name[20]; } array[5];`这种形式。这种写法在定义一次性使用的、作为函数局部变量的数据结构时,显得尤为简洁利落。 匿名结构体避免了在命名空间中创建一个可能用不到的类型名,让代码意图更聚焦于“定义一个特定格式的数组”这件事本身。值得注意的是,这种语法在C和C++11及之后的标准中均受支持。如果这个结构体只在某一个函数内部使用,且逻辑上不与其他地方共享,采用匿名结构体来定义数组是一个既能保持类型清晰,又足够精简的选择。
关于python和C++中子类继承父类数据的问题
这篇讲的是作者在测试Python和C++类继承时遇到的一个“诡异”现象。他原本想验证子类如何从父类继承数据,并特意编写了两种类继承的代码进行对比测试。然而,代码运行的结果却与直觉相悖,暴露出两种语言在继承实现上的根本差异。 问题的根源在于Python和C++处理对象内存布局和属性访问的机制截然不同。Python作为动态语言,对象的属性可以在运行时灵活绑定与修改;而C++作为静态语言,对象的结构(包括其成员变量)在编译时就已确定。这种底层差异,导致在某些特定的继承写法下,子类对父类“数据”的操作和访问会呈现出完全不同的行为,这正是作者测试中遇到的核心“坑点”。 作者通过具体的代码实例,清晰展示了问题是如何产生的,并剖析了背后的语言机制。这对于需要同时处理这两种语言,或对语言底层实现感兴趣的开发者来说,是一次很好的警示:切勿想当然地认为继承行为跨语言一致,理解其背后的内存与类型模型至关重要。
【总结】美化bash,python的soap client,python获取系统编码函数
这篇讲的是三个能提升日常开发效率的实用技巧。作者从最具体的痛点出发:面对超长的终端路径时,那挤到屏幕右边、难以看清的光标确实让人头疼。文章分享了一个用PROMPT_COMMAND来美化和简化bash提示符的方案,让路径显示更紧凑清晰。 接着,作者转向Python生态,介绍了如何使用现代库zeep来构建SOAP客户端,并对比了传统lxml方案,指出了zeep在代码简洁性和自动处理WSDL方面的优势。最后,关于“Python获取系统编码”这个经典坑,文章点明了直接调用sys.getdefaultencoding()可能拿不到进程实际编码的问题,并给出了结合locale环境变量的更可靠获取方式。 虽然都是些“小”技巧,但文章把每个点的背景、核心做法和关键细节都讲得很实在,对经常和终端、老旧接口或编码问题打交道的开发者来说,这些经验能直接用在刀刃上。

python三元运算符的正确方法
这篇讲的是作者在重新学习PHP语法时,联想到Python中并没有等同的三元运算符(?:),于是深入探究了Python的替代实现方式。 文章指出,虽然Python的官方语法不支持传统三元运算符,但可以通过 `value_if_true if condition else value_if_false` 这种条件表达式来实现相同功能。作者特别澄清了一个常见的误解:`and` 与 `or` 组合的短路写法(如 `a and b or c`)虽然有时能模拟,但当 `b` 的布尔值为 `False` 时会导致逻辑错误,并非安全通用的方案。 因此,作者强调使用if-else表达式才是Python中“正确”且清晰的方法。这篇短文适合对Python基础语法有疑问的初学者,它直接点明了一个易混淆的语法细节,并给出了可靠的实践建议。
关于一个gzip压缩问题的定位解决
这篇讲的是一个在CGI外网部署中遇到的典型“坑”:应用一切正常,但部署后特定浏览器访问前端页面时,部分功能莫名失效,控制台却毫无报错。 作者从排查请求入手,发现核心问题在于HTTP响应中的gzip压缩头与浏览器实际解压能力不匹配。经过逐步验证,最终定位到根因是服务器(Apache httpd)对JavaScript文件进行了gzip压缩,而目标浏览器恰好不支持对JS文件的解压,导致资源加载失败。解决方案直接明了:通过修改服务器配置,针对该类文件禁用gzip压缩。 这个案例提醒我们,在涉及Web性能优化(如gzip)时,除了考虑压缩率,还需要关注客户端的兼容性,尤其在混合环境或多浏览器场景下。一个看似简单的配置开关,可能会成为线上问题的隐形推手,细致的抓包与分析依然是定位这类问题的有效手段。
apache+mod_wsgi+django在windows下的部署
这篇讲的是作者在本地Windows环境遇到的一个实际问题:Python从旧版升级到2.7后,依赖的mod_python模块失效,导致Apache服务无法启动。 经过排查,作者发现mod_python已停止维护,而社区推荐的替代方案是mod_wsgi。文章详细记录了解决过程:根据Python 2.7版本下载对应的mod_wsgi文件,将其重命名并放入Apache的modules目录,然后在配置文件中进行相关设置。整个操作步骤清晰,为遇到同样依赖升级问题的开发者提供了一条明确的路径。最后,作者在自己的环境中完成了迁移,成功解决了Apache的启动故障。
用python编写Linux守护进程
作者从刚入职的一次踩坑经历聊起:当时他被要求运行一个迁移程序,还没等跑完就关了终端,结果程序直接中断。最初用nohup参数解决了问题,但强迫别人每次启动都加nohup毕竟不是长久之计,于是他决定自己动手实现守护进程。这篇文章正是他分享如何用Python编写Linux守护进程的实战指南。 文章首先点明背景:许多后台服务需要持续运行,不受用户登录或终端关闭影响,而守护进程就是解决这一问题的关键。作者核心介绍了Python中的实现思路,从经典的Unix方法入手,比如使用os.fork创建子进程、调用setsid脱离原会话、重定向标准输入输出到/dev/null,确保进程完全独立。他还提到了处理文件描述符和信号等细节,让代码更健壮。 通过这个具体例子,读者能直观理解守护进程的运作机制,以及如何避免依赖nohup等外部工具的局限性。整个过程从问题出发,到代码实现,展示了将一个普通程序转化为可靠服务的完整路径。
关于使用STL的红黑树map还是hashmap的问题
这篇讲的是作者在优化代理服务器URL重写功能时,面对的一个典型技术选型问题:在需要极高查询性能(约2万次/秒)的场景下,应该使用C++ STL的基于红黑树的map,还是hashmap。文章没有泛泛而谈理论,而是紧扣高并发下的实际性能需求展开。 作者的核心关切点在于数据结构的性能表现。红黑树map能保证稳定的O(log n)查找,而hashmap在理想情况下能达到O(1),但存在冲突风险和扩容时的性能波动。在URL映射这种对延迟极其敏感的场景中,两者各有需要权衡的微妙之处。 文章的价值在于,它并非简单地给出“哪个更快”的结论,而是从实际的工程压力(单机高QPS)出发,引导读者思考如何结合具体场景(如URL分布特征、内存开销、查找稳定性要求)来做出最合适的选择。这种基于实战背景的对比分析,为面临类似数据结构决策的开发者提供了切实的参考。
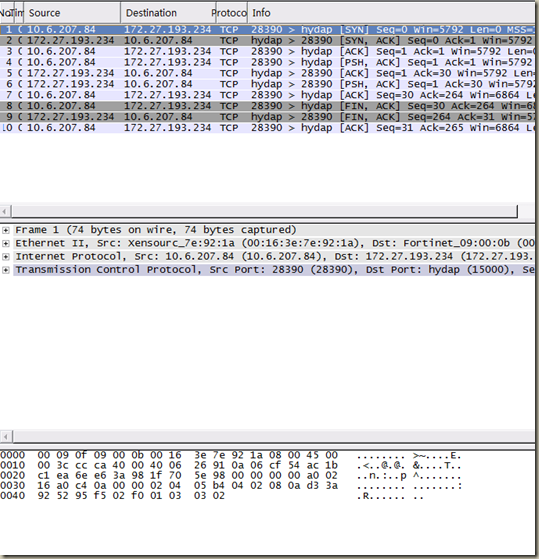
使用wireshark分析网络报文
这篇讲的是在Linux环境下如何更高效地分析网络报文。作者从日常使用tcpdump抓包但分析效率不高的痛点出发,引出了Wireshark这个图形化工具。 与tcpdump这类命令行工具相比,Wireshark最大的优势在于提供了直观的报文解析和可视化界面。它能够自动识别数百种协议,将原始数据包解码成清晰的结构,包括各层头部和载荷内容,极大地减轻了肉眼阅读的负担。文章特别指出了这对于深入理解网络交互过程的便利性。 因此,两者形成了很好的互补:tcpdump适合在终端中快速、轻量地抓取数据包;而当需要对报文内容进行精细分析、排查复杂问题或进行学习研究时,Wireshark的图形化分析能力就显现出不可替代的价值。作者还贴心地附上了官方下载地址,方便读者直接上手体验。