mysql innodb 文件相关的三个重要结构体
这篇讲的是 MySQL InnoDB 引擎里三个关键的物理结构体——数据页、undo日志页和插入缓冲页。它们虽然都以 16KB 的统一页面格式存储在磁盘文件中,但头部的二进制结构和核心职责却大不相同。 作者从 InnoDB 最小的磁盘 I/O 单位“页”出发,拆解了它们的设计。数据页是存储行数据的“仓库货架”,页头详细记录了校验和、记录数、空闲指针等元信息。undo日志页则像“事务的草稿纸”,专门存放数据被修改前的版本,为回滚和 MVCC 服务。而插入缓冲页是一个临时“集结点”,负责批量合并多个非唯一二级索引的插入操作,以减少随机 I/O。 这三个结构体的区分设计很巧妙:它们共享了通用的页面框架(如校验和、页类型标识),但在头部结构和数据区布局上各司其职。理解这种“同形不同职”的差异,能让我们更清晰地看到 InnoDB 如何在统一的文件架构下,高效地兼顾了数据存储、事务一致性和索引写入性能。这为深入理解数据库底层如何运作提供了很好的视角。
redis在大数据量下的压测表现
这篇讲的是作者对Redis在海量数据场景下的一次深度性能摸底。测试并非停留在简单的小数据验证,而是直面数十亿甚至上百亿键值对的大数据量现实,关注其在内存、延迟和吞吐等核心指标上的实际表现。 作者详细设置了不同数据规模的测试环境,模拟了读写混合的复杂负载。报告给出了具体的压测数据,比如在数据量从十亿级增长到百亿级时,Redis的响应延迟变化曲线,以及内存占用率的真实增长情况。测试发现,在数据量逼近物理内存极限时,性能拐点具体出现在哪里,系统抖动的主要原因是什么。 文章的核心价值在于,它用实测数据验证了许多人对Redis“单线程”和“内存数据库”在大数据量下可能面临挑战的猜测,也给出了在极端情况下保障服务稳定性的优化方向。对于需要规划Redis集群容量、预估线上性能的工程师来说,这篇测试报告提供的量化结论很有参考意义。
社区与电子商务
这篇探讨的是社区与电子商务如何深度融合的议题。作者没有停留在简单的功能叠加层面,而是深入剖析了两者结合的内在逻辑。 核心观点认为,成功的社区电商并非简单地在社区里开个店铺,而是要让社区关系成为交易的催化剂和放大器。文章以几个具体案例为支撑,比如基于兴趣圈子的团购、邻里间的技能与服务交换平台等,展示了信任关系如何显著降低了交易成本,提升了转化率和复购率。 更关键的是,文章分析了这种模式的双向价值:电商为社区提供了持续互动的理由和物质基础,而社区则为电商提供了宝贵的、低成本的信任背书和精准的用户反馈渠道。作者也指出了其中的挑战,比如如何平衡社区氛围与商业运营,以及对运营者提出了更高的综合能力要求。对于思考私域流量、新零售或产品增长的朋友来说,这篇文章提供了一个将“关系”价值量化落地的具体视角。
MySQL服务器raid卡充放电导致的问题
这篇讲的是一个线上环境踩过的经典坑:MySQL服务器因为RAID卡充放电,导致数据库响应变慢甚至不可用。文章从监控报警发现磁盘I/O异常和数据库慢查询激增开始,详细描述了排查过程。作者通过对比正常时段和异常时段的性能监控图,并借助磁盘性能测试工具,最终定位到“罪魁祸首”是RAID卡的缓存策略。 问题的核心在于,当RAID卡电池掉电或处于放电学习周期时,为了数据安全,控制器会自动关闭写缓存。这使得原本通过缓存批量写入磁盘的操作,变成了需要直接面对物理磁盘的同步写入,写入延迟因此飙升。MySQL的事务提交、日志刷新等关键操作严重受此影响。 文章不仅分析了现象和根因,也给出了切实可行的解决思路,比如配置RAID卡的缓存策略,或者在业务低峰期手动控制充放电周期。对于运维和DBA来说,这是一个提醒:必须关注存储子系统的底层健康状态,它往往是数据库性能链条中最隐蔽也最致命的一环。

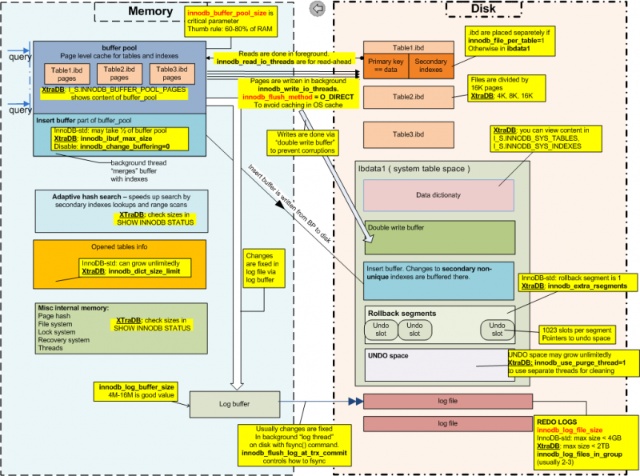
XtraDB/Innodb内部结构示意图
这篇讲的是InnoDB存储引擎内部结构的直观指南。作者从源码出发,梳理了InnoDB各核心组件间的复杂关系与协作流程,画出了一张清晰的层次示意图。 图中从上到下涵盖了客户端连接、SQL解析优化、缓冲池管理、事务与锁、到最底层的表空间与数据文件的完整链路。特别点出了Buffer Pool、Change Buffer、Log Buffer等关键内存结构,以及它们与磁盘文件的交互。对于理解一次写操作如何经过多层模块最终持久化非常直观。 这张图并非空泛的框架示意,而是基于真实代码逻辑绘制,细节到位。作者甚至提到,这张图“可以打印出来贴在座位旁边”,其作为日常开发与故障排查参考的实用性可见一斑。对于想深入理解MySQL/InnoDB工作原理的开发者来说,这是一份能帮你在脑中建立清晰心智模型的宝贵资料。
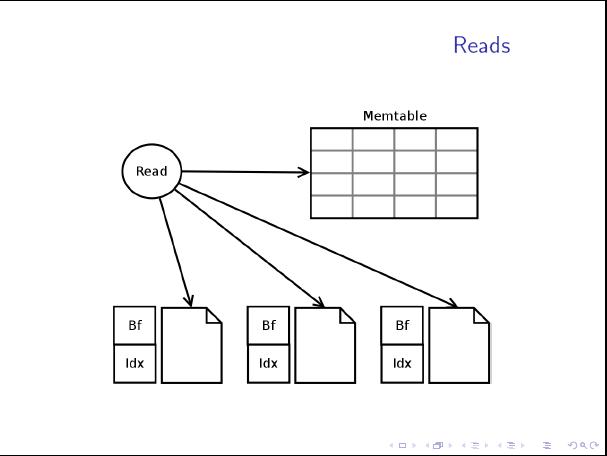
转载:cassandra读写性能原理分析
这篇讲的是Cassandra数据库在高并发读写场景下,其性能表现背后的底层原理。作者从数据在内存与磁盘间的流动路径出发,深入剖析了Cassandra如何利用LSM-Tree结构来极致化写入吞吐量。 核心思路在于将随机写转化为顺序写:数据先写入内存中的MemTable,满了之后再顺序刷入磁盘,生成不可变的SSTable文件。这带来了极高的写入速度,但也为读取带来了挑战,因为数据可能分散在多个文件中。 文章的亮点在于详细拆解了Cassandra为优化读性能所做的“权衡”与“设计”。例如,它如何通过布隆过滤器快速排除不存在的SSTable,减少不必要的磁盘IO;如何定期执行压缩(Compaction)操作来合并SSTable,既减少文件数量,又清理过期数据。文中对不同压缩策略(如Size-Tiered和Leveled)的适用场景也做了对比,帮助读者理解如何在写放大与读放大之间做出选择。 总的来说,这不仅仅是对配置参数的说明,而是带领读者理解Cassandra在“快速写入”与“高效查询”这两个看似矛盾的目标之间,是如何通过精巧的存储架构设计达成平衡的。