1. 关于cassandra的读性能分析的一篇文章:
Mike Perham continues his series now explaining: “reads and […] why they are slow”.
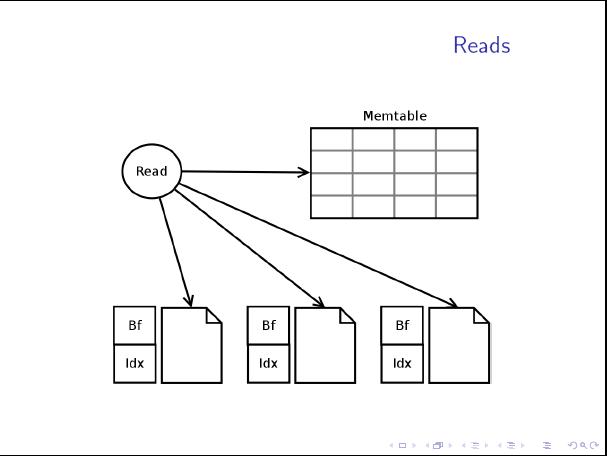
So what happens with a Cassandra read?
- a client makes a read request to a random node
- the node acts as a proxy determining the nodes having copies of data
- the node request the corresponding data from each node
- the client can select the strength of the read consistency:
- single read => the request returns once it gets the first response, but data can be stale
- quorum read => the request returns only after the majority responded with the same value
Mark mentions a couple of corner cases related to this behavior that is more complicated.
- the node also performs read repair of any inconsistent response
- each node reading data uses either Memtable (in-memory) or SSTables (disk)
Mike and Jonathan provide a very detailed explanation of the read performance:
Mike: To scan the SSTable, Cassandra uses a row-level column index and bloom filter to find the necessary blocks on disk, deserializes them and determines the actual data to return. There’s a lot of disk IO here which ultimately makes the read latency higher than a similar DBMS.
Jonathan: The reason uncached reads are slower in Cassandra is not because the SSTable is inherently io-intensive (it’s actually better than b-tree based storage on a 1:1 basis) but because in the average case you’ll have to merge row fragments from 2-4 SSTables to complete the request, since SSTables are not update-in-place.
It is also important to note that Cassandra employs row caching that addresses reads latency.
2. 关于cassandra的写性能分析的一篇文章:
An interesting explanation of how Cassandra write ops are happening:

- client submits its write request to a single, random Cassandra node
- the node behavior is similar to a proxy writing data to the cluster
- writes are replicated to N nodes according to the replication placement strategy (the details of RackAwareStrategy are quite interesting)
- each of the N nodes performs 2 actions when receiving a write (in the form of RowMutation):
- append the mutation to the commit log for transactional purposes
- update an in-memory Memtable structure with the change
There are also a couple of asynchronous operations:
- Memtable is written to disk in a structure called SSTable
- SSTables corresponding to a column family are merged into a raw ColumnFamily datafile.
参考文档:
http://nosql.mypopescu.com/post/474623402/cassandra-reads-performance-explained
http://nosql.mypopescu.com/post/454521259/cassandra-write-operation-performance-explained