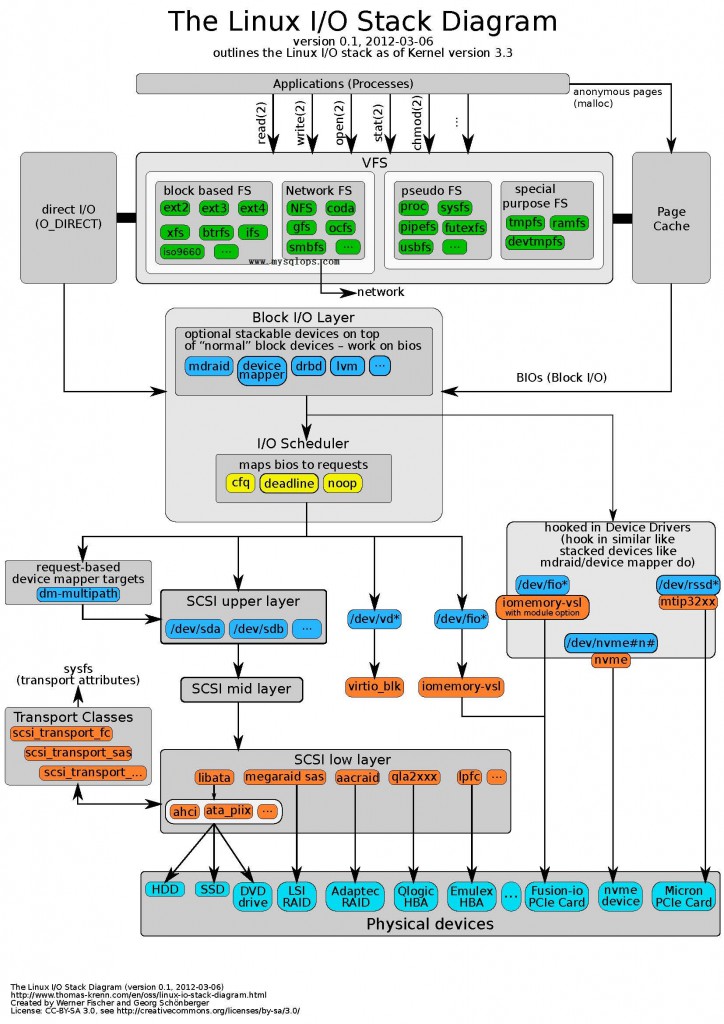
Linux操作系统内核3.3版本I/O Stack的流图
这张流程图拆解了Linux 3.3内核的I/O栈结构,由thomas-krenn.com在2012年公开。它从应用层的O_Direct调用开始,清晰地展现了数据路径的完整旅程。 整个流程被分解为几个核心模块:首先涉及直接I/O或经过页缓存的路径,随后进入虚拟文件系统(VFS)层进行文件系统与网络通信的抽象。数据随后到达块I/O层,经过特定的I/O调度算法处理,再由SCSI子系统适配,最终抵达磁盘硬件。 这份资料最大的价值在于其系统性和直观性。它将原本隐含在内核代码中的复杂数据流向,转化为一张可触摸的全局地图。对于需要理解系统底层性能瓶颈、存储调优或文件系统实现的工程师而言,这相当于一份清晰的导航图,帮助准确定位数据在软件与硬件边界之间的每一跳。
本机暂存