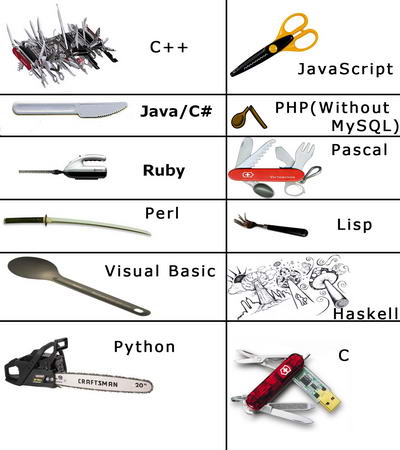
千万别惹程序员
这篇讲的是酷壳博客如何巧妙调节技术内容的严肃氛围。作者从博客近期缺乏娱乐性质文章、导致气氛偏于沉重的情况出发,指出程序员群体虽然常被认为严肃且较真,但同样需要轻松的内容来平衡。文章分享了两张在新浪微博上反响热烈的图,这些图以幽默视角捕捉了程序员的日常细节,比如编码时的专注瞬间或职场中的典型梗,让技术读者会心一笑的同时,也展现了程序员群体生动的一面。 事件背景是酷壳意识到长期更新硬核技术内容可能让社区氛围紧绷,因此主动寻求娱乐化调整。核心观点在于,这类轻松内容不仅能缓解严肃感,还能在社交平台引发共鸣——那两张图的互动数据便证明了娱乐性质技术内容的传播潜力。对读者的启发在于,技术交流不必局限于代码与架构,适当加入趣味元素可以拉近创作者与受众的距离,甚至增强社区的归属感。 通过具体案例,文章揭示了
本机暂存