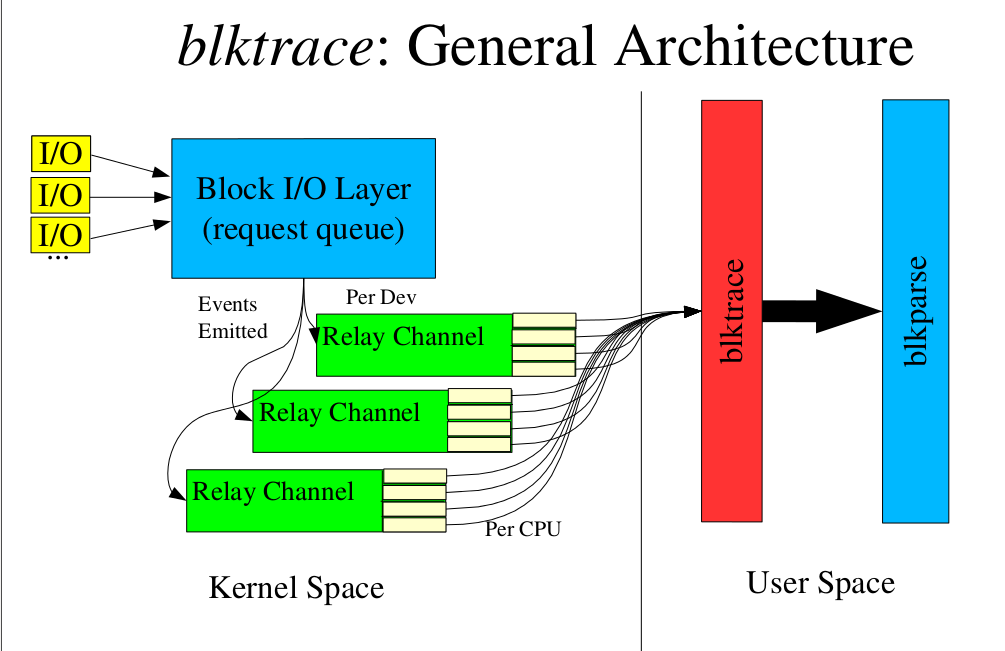
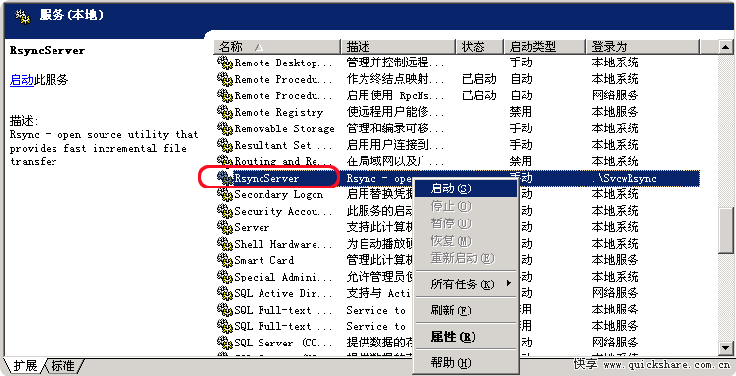
闲谈跨界
这篇文章里,作者从朋友的一句“跨界工作真是一件刺激好玩的事情”出发,分享了自己投身跨界项目后的真实体悟。对于许多习惯深耕单一技术领域的开发者而言,“跨界”往往意味着跳出舒适区,去接触陌生的业务逻辑、协作流程甚至思维模式。 文章并未停留在泛泛而谈的层面,而是深入描绘了跨界过程中的具体挑战与收获。比如,当一名工程师需要理解产品设计的用户体验视角,或是参与市场策略的讨论时,技术实现不再是唯一答案,如何用对方的语言沟通、如何在不同目标间找到平衡点,成了更关键的课题。作者结合亲身经历,剖析了跨界带来的思维碰撞如何拓宽了解决问题的维度——那些原本看似“非技术”的沟通与理解过程,最终竟反哺了技术方案的创新与落地。 对于读者而言,这篇文章的价值或许不在于提供即学即用的技巧,而在于一种视角的启发:在技术栈之外,那些跨领域的认知与协作能力,正逐渐成为复杂项目中不可或缺的软性基石。
本机暂存