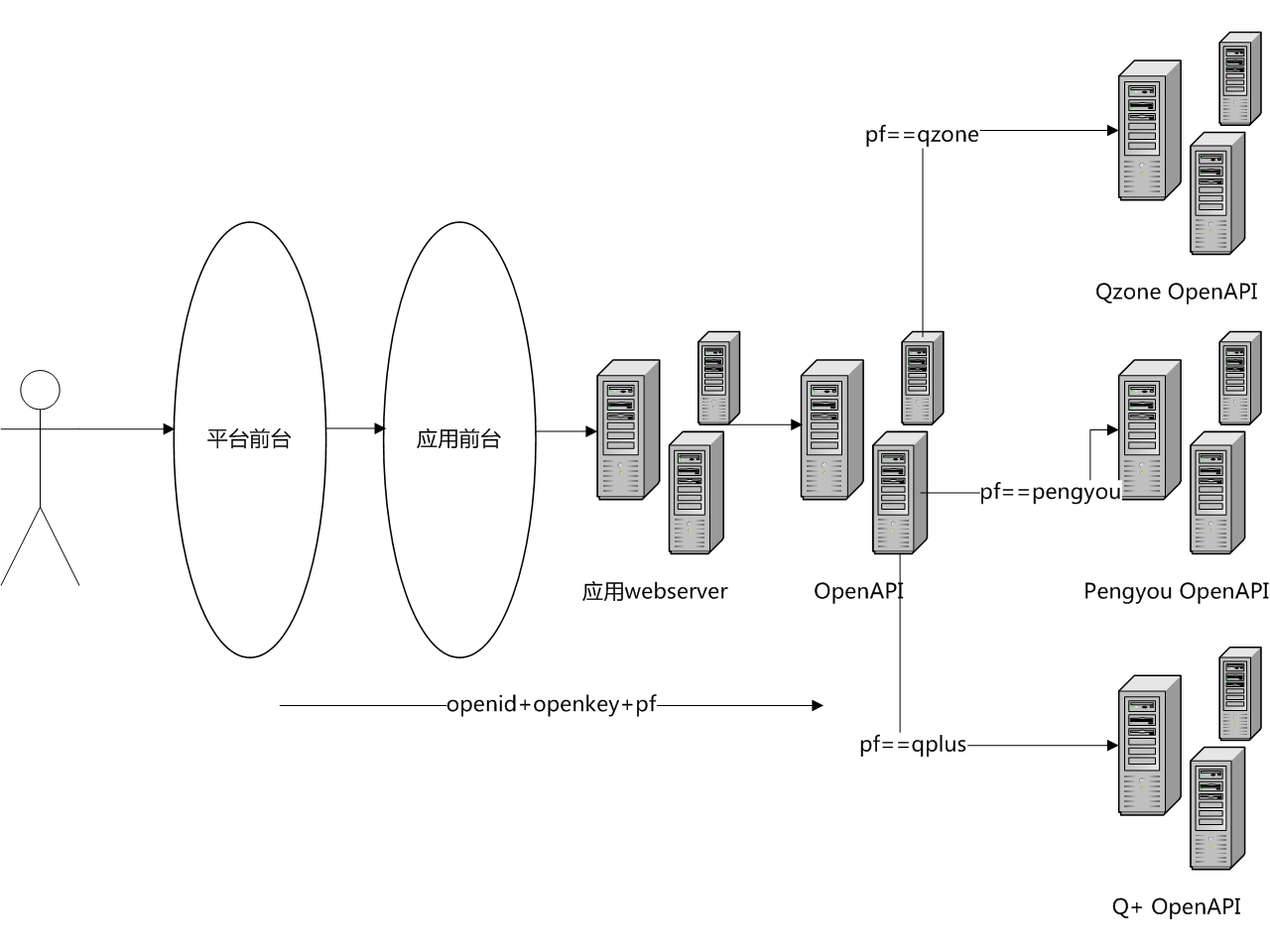
Web开发中需要了解的东西
作者从StackExchange上一个经典问答出发,翻译并整理了“每个程序员需要知道的Web开发知识”的高赞回答。这个问答由全球开发者共同参与维护,通过持续修订形成了系统性的Web开发指南,内容涵盖HTTP协议、API设计、前端框架选型、安全性等核心知识点,干货密集且不断演进。 文章不仅提炼了技术要点,还以StackExchange的协作为案例,展示了优质问答社区的运作模式:用户可以共同编辑和修订答案,让内容在碰撞中日趋完善。作者将这种机制与自己之前强调的“用户体验”观点相联结
本机暂存