2011互联网技术发展浅析
这篇发布于2011年初、现经整理重温的文章,将目光投向了互联网技术史上一个承前启后的关键节点。作者从当时快速演进的技术生态出发,对Web开发框架、云计算基础架构、大规模数据处理等领域的动态进行了系统性的梳理与剖析。 文章的核心并非罗列事件,而是试图捕捉技术演进背后的趋势与脉络。它记录了在那个移动互联网刚起步的年代,业界如何应对流量增长、系统复杂化带来的挑战,并做出了哪些重要的技术选型与架构决策。例如,文中对NoSQL数据库的兴起、前后端分离的萌芽等趋势的观察,在今天看来依然具有预见性。 时隔多年再看这篇文章,其价值已超越了具体的技术细节。它像一份详尽的“技术考古”报告,为我们保存了那个充满探索与变革时期的真实切片。通过回顾这些十年多前的分析,读者不仅能理解当下诸多主流技术的源头与必然性,更能从中领悟技术发展的周期性规律,为当下及未来的架构思考提供珍贵的历史参照。
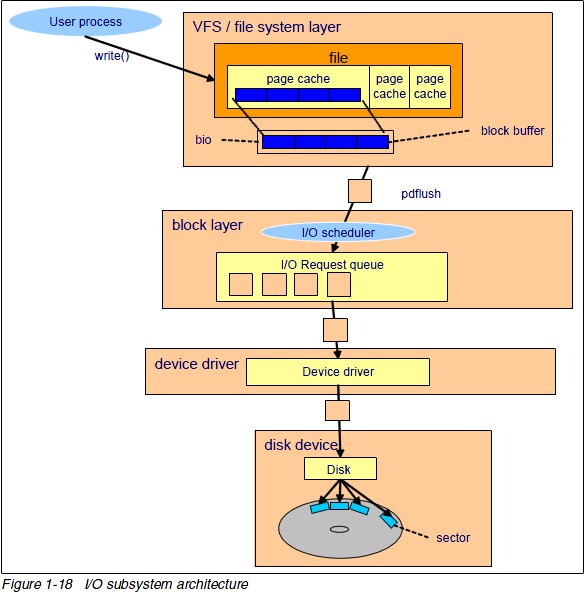
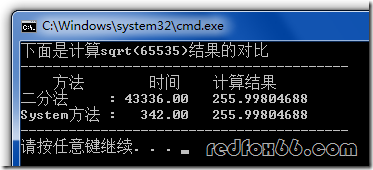
本机暂存