一次某优化工具厂商的朋友,发来一个案例请求协助诊断,朋友的优化工具在客户的环境中执行某个SQL查询时,需要10分钟时间才能出结果,这是无法接受的,而同样的查询在其他环境上都可以快速的获得输出结果,数据库环境是9.2.0.8。
首先我获得了一个10046跟踪文件,通过tkprof格式化之后,这个SQL的输出结果展现出来。
首先该SQL代码如下:
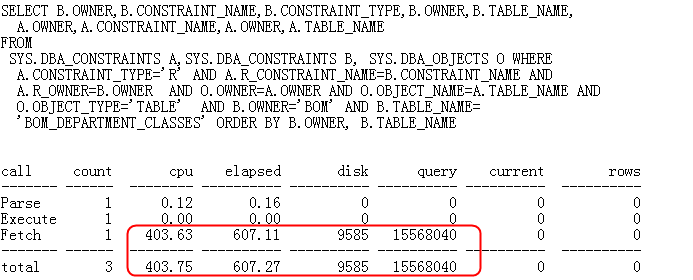
该段SQL的Elapsed时间超过了600秒,Query模式逻辑读也非常高,对于一个优化工具来说显然是不可接受的。
接下来的跟踪文件中显示了SQL的执行计划:
Rows Row Source Operation
------- ---------------------------------------------------
0 NESTED LOOPS OUTER
0 NESTED LOOPS OUTER
0 NESTED LOOPS OUTER
0 NESTED LOOPS OUTER
0 NESTED LOOPS OUTER
0 NESTED LOOPS
0 NESTED LOOPS OUTER
0 NESTED LOOPS
0 NESTED LOOPS OUTER
0 NESTED LOOPS OUTER
0 NESTED LOOPS
0 NESTED LOOPS
0 NESTED LOOPS
1935557 NESTED LOOPS
2863 NESTED LOOPS
2863 NESTED LOOPS
2863 NESTED LOOPS
1 NESTED LOOPS
1 TABLE ACCESS BY INDEX ROWID USER$
1 INDEX UNIQUE SCAN I_USER1 (object id 44)
1 TABLE ACCESS BY INDEX ROWID USER$
1 INDEX UNIQUE SCAN I_USER1 (object id 44)
2863 TABLE ACCESS FULL CDEF$
2863 TABLE ACCESS BY INDEX ROWID CON$
2863 INDEX UNIQUE SCAN I_CON2 (object id 49)
2863 TABLE ACCESS CLUSTER USER$
2863 INDEX UNIQUE SCAN I_USER# (object id 11)
1935557 VIEW
1935557 UNION-ALL PARTITION
1935557 FILTER
1935557 NESTED LOOPS
2863 TABLE ACCESS BY INDEX ROWID USER$
2863 INDEX UNIQUE SCAN I_USER1 (object id 44)
1935557 TABLE ACCESS FULL OBJ$
0 TABLE ACCESS BY INDEX ROWID IND$
0 INDEX UNIQUE SCAN I_IND1 (object id 39)
0 FILTER
0 NESTED LOOPS
0 TABLE ACCESS BY INDEX ROWID USER$
0 INDEX UNIQUE SCAN I_USER1 (object id 44)
0 INDEX RANGE SCAN I_LINK1 (object id 113)
0 TABLE ACCESS BY INDEX ROWID CON$
1935557 INDEX UNIQUE SCAN I_CON2 (object id 49)
0 TABLE ACCESS BY INDEX ROWID CON$
0 INDEX UNIQUE SCAN I_CON1 (object id 48)
0 TABLE ACCESS BY INDEX ROWID CDEF$
0 INDEX UNIQUE SCAN I_CDEF1 (object id 50)
0 TABLE ACCESS BY INDEX ROWID CON$
0 INDEX UNIQUE SCAN I_CON2 (object id 49)
0 TABLE ACCESS CLUSTER USER$
0 INDEX UNIQUE SCAN I_USER# (object id 11)
0 TABLE ACCESS BY INDEX ROWID OBJ$
0 INDEX UNIQUE SCAN I_OBJ1 (object id 36)
0 INDEX UNIQUE SCAN I_OBJ1 (object id 36)
0 TABLE ACCESS BY INDEX ROWID OBJ$
0 INDEX UNIQUE SCAN I_OBJ1 (object id 36)
0 TABLE ACCESS BY INDEX ROWID OBJ$
0 INDEX UNIQUE SCAN I_OBJ1 (object id 36)
0 TABLE ACCESS CLUSTER USER$
0 INDEX UNIQUE SCAN I_USER# (object id 11)
0 INDEX UNIQUE SCAN I_OBJ1 (object id 36)
0 TABLE ACCESS BY INDEX ROWID OBJ$
0 INDEX UNIQUE SCAN I_OBJ1 (object id 36)
0 TABLE ACCESS CLUSTER USER$
0 INDEX UNIQUE SCAN I_USER# (object id 11)
以上执行计划中,最可疑的部分是对于OBJ$的全表扫描,这个环节的行数返回有1,935,557行,这个量级一直向上传递,所以我们首先怀疑这里的执行计划选择错误,如果选择索引,执行性能肯定会有极大的不同。
可是10046的跟踪事件显示的信息比较有限不能够准确定位错误的原因,我请朋友通过10053事件来生成一个执行计划的跟踪,10053使用极为简便,通过如下方式就可以捕获SQL的解析过程:
alter session set events \'10053 trace name context forever,level 1\';
explain plan for you_select_query;
例如:
SQL> alter session set events \'10053 trace name context forever,level 1\';
Session altered.
SQL> explain plan for select count(*) from obj$;
Explained.
然后在udump目录下就可以找到10053生成的跟踪文件,在该文件中,找到了查询相关表的统计信息,其中OBJ$的信息如下所示,其中CDN?arDiNality)指表中包含的记录数量,此处显示OBJ$表中有24万左右的记录,使用了2941个数据块:
***********************
Table stats Table: OBJ$ Alias: SYS_ALIAS_1
TOTAL :: CDN: 245313 NBLKS: 2941 AVG_ROW_LEN: 79
Column: OWNER# Col#: 3 Table: OBJ$ Alias: SYS_ALIAS_1
NDV: 221 NULLS: 0 DENS: 4.5249e-03 LO: 0 HI: 259
NO HISTOGRAM: #BKT: 1 #VAL: 2
-- Index stats
INDEX NAME: I_OBJ1 COL#: 1
TOTAL :: LVLS: 1 #LB: 632 #DK: 245313 LB/K: 1 DB/K: 1 CLUF: 4184
INDEX NAME: I_OBJ2 COL#: 3 4 5 12 13 6
TOTAL :: LVLS: 2 #LB: 1904 #DK: 245313 LB/K: 1 DB/K: 1 CLUF: 180286
INDEX NAME: I_OBJ3 COL#: 15
TOTAL :: LVLS: 1 #LB: 19 #DK: 2007 LB/K: 1 DB/K: 1 CLUF: 340
_OPTIMIZER_PERCENT_PARALLEL = 0
***************************************
而在前面的10046跟踪信息中,显示OBJ$包含大约200万条记录,这是非常巨大的不同,对于USER$表,显示具有2863条记录,而统计信息中显示仅有253条记录:
***********************
Table stats Table: USER$ Alias: U
TOTAL :: CDN: 253 NBLKS: 16 AVG_ROW_LEN: 82
Column: USER# Col#: 1 Table: USER$ Alias: U
NDV: 253 NULLS: 0 DENS: 3.9526e-03 LO: 0 HI: 261
NO HISTOGRAM: #BKT: 1 #VAL: 2
-- Index stats
INDEX NAME: I_USER# COL#: 1
TOTAL :: LVLS: 0 #LB: 1 #DK: 258 LB/K: 1 DB/K: 1 CLUF: 13
INDEX NAME: I_USER1 COL#: 2
TOTAL :: LVLS: 0 #LB: 1 #DK: 253 LB/K: 1 DB/K: 1 CLUF: 87
***********************
这说明数据字典中记录的统计信息与真实情况不符合,导致了SQL选择了错误的执行计划,在使用CBO的Oracle9i数据库中,这种情况极为普遍,通过删除表的统计信息,或者重新收集正确的统计信息,可以使SQL执行恢复到正常合理的范畴内。在Oracle10g开始的自动统计信息收集,就是为了防止出现统计信息陈旧的现象。
以下是通过dbms_stats包清除和重新收集表的统计信息的简单参考:
SQL> exec dbms_stats.delete_table_stats(user,\'OBJ$\');
PL/SQL procedure successfully completed.
SQL> exec dbms_stats.gather_table_stats(user,\'OBJ$\');
PL/SQL procedure successfully completed.
基于这样的判断我们建议客户做出修正,最后的客户反馈结果是:按照你的建议,在更新OBJ$的统计信息后,该语句的执行时间由10分钟减少到了2分钟。接下来,按照类似的思路,又更新了USER$,CON$,CDEF$表的统计信息,这时,语句的执行时间减少到了零点几秒。至此,问题解决。