Kindle 电子书生成工具
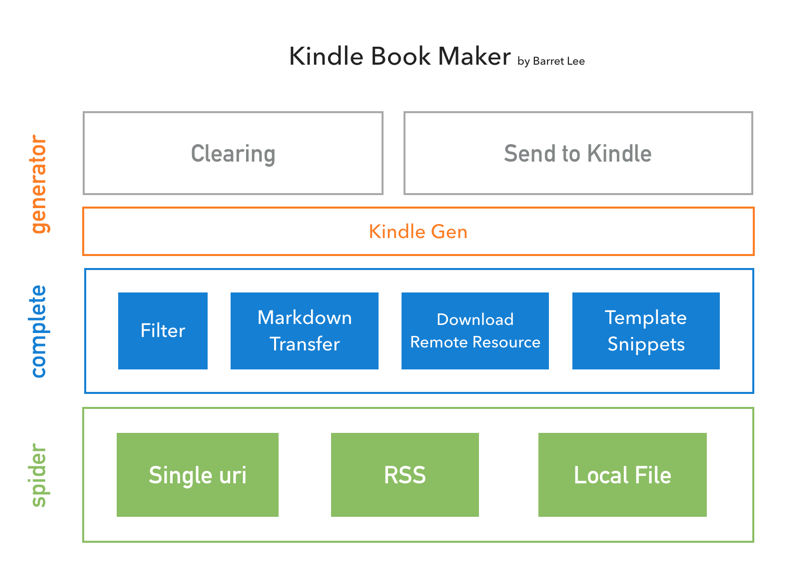
这篇讲的是开发者如何为纯粹阅读打造一款 Kindle 电子书生成工具。作者从自身需求出发,为了解决手机阅读干扰多、伤眼的问题,花了两个晚上钻研 OPF 和 EPUB 格式,最终构建了一个能将网络内容一键转换为 Kindle 电子书的命令行工具。 该工具的核心原理是依据 OPF 规范生成 KF8 格式的 .mobi 文件。它的数据来源相当灵活:既可以通过指定 URL 和 DOM 选择器抓取单篇文章,也能直接订阅 RSS 源获取更新,甚至能处理本地 Hexo 博客生成的 HTML 文件。程序会智能分析和过滤数据,对 Hexo 文件做了特殊适配,并且能自动下载页面中的远程图片和 CSS 样式,确保电子书内容完整。 项目已将 Amazon 官方的 kindlegen 工具内置,目前默认支持 Mac 系统,但通过社区贡献也提供了 Windows 平台的支持方案。整个流程被简化为编辑配置文件或运行命令行,目标是让技术爱好者和内容创作者都能轻松地把零散的网页文章“打包”成一本本精致的电子书。