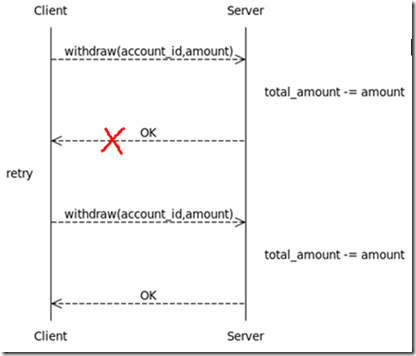
浏览器多tab打开同一URL串行化的问题
这篇讲的是浏览器在处理同一URL多个标签页打开时可能出现的串行化现象。作者从一次线上项目实战出发,发现浏览器对同一URL的多个标签页请求竟然变成了串行处理,严重影响了用户体验和页面加载速度。 通过DevTools抓包和日志分析,最终定位到这是浏览器为了优化性能而默认启用的“连接复用”机制在特定场景下的副作用。文章不仅剖析了浏览器(特别是基于Chromium内核的)如何管理连接池和调度请求的底层逻辑,还深入讲解了HTTP/2与HTTP/1.1在这一问题上的不同表现。 文章详细介绍了通过调整服务端响应头、修改前端请求策略,甚至使用Service Worker等不同层面的解决方案,并对比了各自的优劣和适用场景。对于需要处理高频同源请求的前端开发者或运维人员,这篇文章提供了一份从现象复盘到根因剖析,再到多维度解决的完整实战指南。