node.js调研与服务性能测试
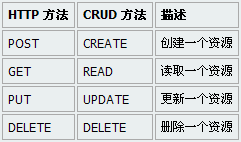
这篇讲的是作者对Node.js进行的初步调研与实践性能测试。他从Node.js的非阻塞I/O和事件循环机制入手,搭建了典型的Web服务模型进行压测。测试环境配置了不同的并发连接数,观察其CPU与内存的消耗曲线。 关键发现在于,面对I/O密集型任务,Node.js的吞吐量表现优异,资源占用相对平稳;但在计算密集型场景下,单线程模型会成为瓶颈,CPU使用率会迅速飙升。作者通过具体的压测数据(比如每秒请求数和响应延迟)展示了这一特点。 文章最后基于测试结论,归纳了Node.js更适合API网关、实时推送等场景,而对于需要大量CPU运算的服务,则需要谨慎评估或采用多进程架构。