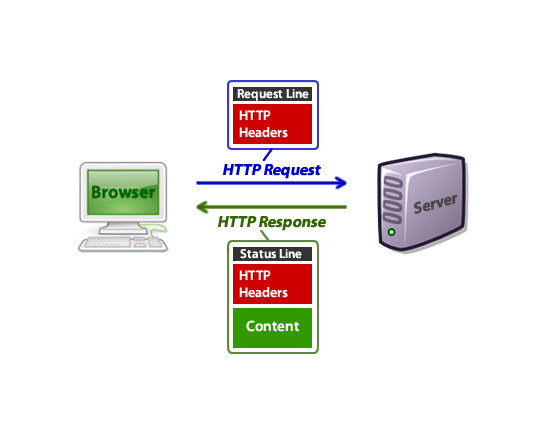
互联网是什么
这篇讲的是作者对“互联网究竟是什么”这个看似简单的问题,给出了一个极其凝练的个人定义。作者没有从常见的TCP/IP协议或服务器架构出发,而是从日常经验中提炼出一个核心事实,试图用最简洁的语言,揭示互联网作为全球信息网络最底层的本质特征。 文章的特别之处在于它的“简炼”——作者跳过了技术术语的堆砌,直指互联网作为连接载体与信息通道的核心功能。这种高度概括的视角,能让不同技术背景的读者快速抓住要领,无论你是刚开始学习网络知识的新手,还是需要向非技术人员解释概念的老兵,都能从中获得一个清晰、不冗余的切入点,重新思考这个我们每天依赖却未必深究的基础设施。