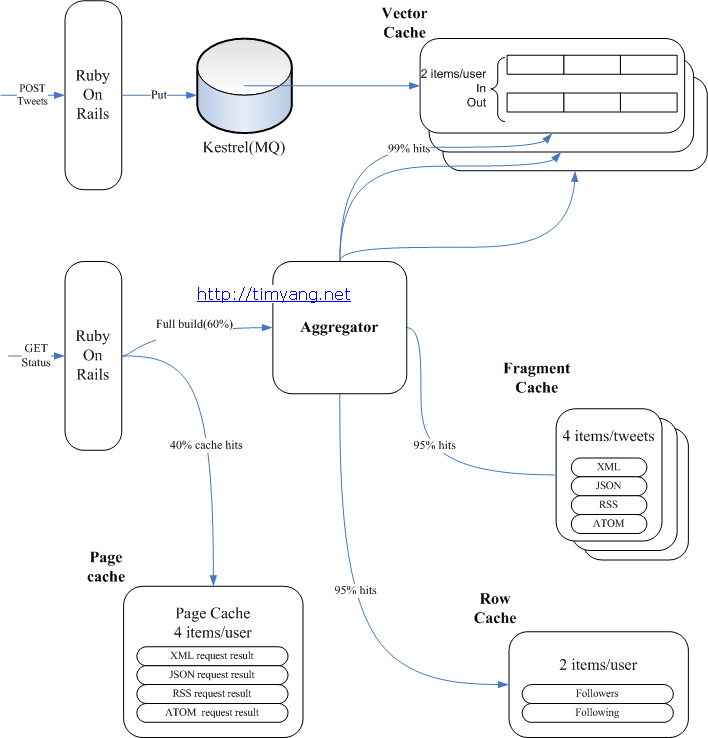
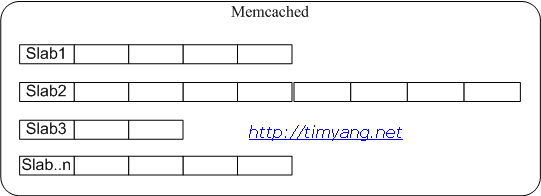
Memcache源代码分析之网络处理
这篇讲的是 Memcache 网络层的实现剖析。作者从连接建立讲起,深入其核心——基于 libevent 库的事件驱动模型。文章细致地拆解了 Memcache 如何通过事件监听、I/O 复用(如 epoll)来处理高并发客户端连接,详细说明了从 accept 新连接、读写数据到处理请求的整个流程控制。 关键点在于,它展示了如何将一个看似简单的“收发数据”过程,通过 libevent 的回调机制组织成高效、非阻塞的事件循环。这对于理解高性能网络服务的设计思路非常有益。文末对事件处理逻辑的梳理,让读者能清晰看到 Memcache 网络处理部分简洁而高效的骨架。