您现在的位置:首页
--> 系统运维
随着系统的升级,无用内核也慢慢累积得越来越多,所以要定时清理,下面是清理的过程。




sendmail是一个漏洞奇多、配置超级麻烦的东西,所以很多系统管理员都把它禁用了。但是如此一来,如果crontab脚本执行出错,就只有天知地知了。 sendmail有很多轻量级的替代,我之前一直在用ssmtp,但是这东西已经停止维护了,我在google 搜它的源代码都搜不到。于是我就只好找其它的替代,于是就找到了msmtp。
前几天微博上有同学问我磁盘util达到了100%时程序性能下降的问题,由于信息实在有限,我也没有办法帮太大的忙,这篇blog只是想给他列一下在磁盘util很高的时候如何通过blktrace+debugfs找到发生IO的文件,然后再结合自己的应用程序,分析出这些IO到底是谁产生的,最终目的当然是尽量减少不必要的IO干扰,提高程序的性能。 blktrace是Jens Axobe写的一个跟踪IO请求的工具,Linux系统发起的IO请求都可以通过blktrace捕获并分析。
一般我们可以通过工具vmstat, dstat, pidstat来观察CS的切换情况。vmstat, dstat只能观察整个系统的切换情况,而pidstat可以更精确地观察某个进程的上下文切换情况。这里我用了chaos库中task_service的一个测试用例来说明情况(chaos库是我写得一个高性能并发网络库,而task_service是一个提供了多线程通信的异步消息队列)。

对于做运维的同学来说,给两台UNIX/Linux机器建立ssh信任关系是再经常不过的事情了。 不知道大家之前建立信任关系是采用什么方法,反正我是纯手工创建。 如果需要“machineA机器的nameA账号”建立到“machineB机器的nameB账号”的ssh信任关系,达到无需输密码即可登陆的目的。

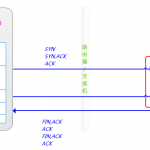
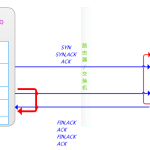
前几天看到一篇博客,提到php所在服务器在大并发情况下,频繁创建TCP短连接,而其所在服务器的2MSL时间过长,导致没有端口可用,系统无法创建TCP socket,而大量报错。博主在后面给的解决方案是减少2MSL的时间,尽快清除TIME_WAIT状态的TCP连接,回收端口。同时,文章结尾写了不用长连接的理由,但这真的是最好的解决办法吗?有其他办法可以更好的做法吗?
1,以官方文档为准,一切跟着官方文档来,不轻易采信网络上网友提供的编译参数,包括这边博文。不论对方是老手、大牛,还是其他什么什么有威望的人。他们提供的方法或许跟你当前的环境不一致,时间也相差很大,或许相隔好几年了;2,确认得到的结果是准确的,怎么说呢,文中的例子中php-i的路径不是我们新编译的,而是之前编译,或者yum安装的,一定要到自己编译的程序目录下,用自己新编译的脚本去执行测试,获得测试结果,下结论,不为了偷懒,不敲路径,直接写程序名进行测试;
本篇博文只会讲解gitolite的基础内容,主要包括了gitolite的安装方法、权限设置方法和基本的使用方法。 如果你希望学习到完整的教程,可以移步这里。 先说说我们大概会讲到哪些内容,以及讲解顺序: 01 - 安装和设置 02 - 增加用户和代码仓库 03 - 为你的用户提供支持 04 - 配置文件基本语法 05 - 访问规则 06 - 组概念 07 - 命令介绍 08 - rc文件介绍 09 - GIT-CONFIG 10 - GIT-DAEMON 11 - GITWEB
数据无价,及时备份刚才有个玩家在站上玩游戏,提醒了我要及时备份数据啊,万一哪天服务器挂了把他们的数据丢了,我可就是罪人了!一直打算放个自动备份的shell,都没有放。正好现在不忙,随手加了进去。
昨天我们发现每日构建的服务器突然在一个晚上内存暴增了 8 G ,显然是发生了内存泄露。之前,我们在 skynet 里留下了许多调试协议,使我们很快的确定了发生泄露的服务:在一张地图的 lua State 中。可以确定是地图的 lua 实现中,有些 lua 对象在不断的生成。生成速度不快,但确实没有人解开引用,导致内存持续增长。
• 关于两种限流模式
流量预警和限流方案中,比较常用的有两种。第一种滑窗模式,通过统计多个单元时间的访问次数来进行控制,当单位时间的访问次数达到的某个峰值时进行限流。第二种为响应模式,通过控制当前活跃请求数,来进行流量控制。下面来简单分析下两种的优缺点。
网站核心页面前后端代码平滑发布的问题是日常开发中的常见问题,本文结合阿里巴巴中文站的实践,给出了一套自动化的解决方案,希望能给大家提供思路上的借鉴,同时欢迎探讨。
监控文件系统的变化,不是一个常见的需求,但是随着对PHP使用的深入,不可避免的会碰到这类问题。我所在的公司,在服务器端,使用PHP进程常驻内存,来完成一些任务,甚至伺服服务。我们知道,PHP作为服务器动态语言,是不需要编译的,但是代码的生命周期是仅限于一次请求的,一次请求结束,下次请求,就会重新加载代码,除非安装了Opcode Cache,但是如果PHP常驻进程,这种自动加载更新代码的能力就失去了。这时候,我们有一种弥补方案,就是使用inotify。
在上家公司曾写过这样一个服务,用户通过我的应用(以下简称fri_svr)索取自己的好友信息,而fri_svr需要向第三方平台(如:人人,Facebook)通过http协议批量请求用户数据,由于用户数据可能很大(几k几十k的级别),所以整个req/rep的过程通常会很慢,平均大概会在 1s - 10s 之间,这样当瞬时请求量到一定级别后,就会造成fri_svr的内存暴涨且响应不了前端的请求,原因在于fri_svr会对前端的每个请求hash到(根据user_id)专门用于http请求的线程队列中(也即是one thread per queue模型),当前端向fri_svr的请求速率大于平台响应fri_svr的,那么就会造成fri_svr中队列的积攒,内存的暴涨,且无法在超时时间内响应前端请求。
制程这玩意有一个物理天花板,提升越来越难,有报道指出,现阶段普遍应用的硅晶体管在尺寸上有一个10nm的物理极限。为了提升性能cpu走上了多核的道路,即在一个封装(socket或者processor)里放多个core。这还不够,又发明了超线程技术Hyper-threading
pig是个啥东东?简单的说,就是支持并行的gzip。pig默认用当前逻辑cpu个数来并发压缩,无法检测个数的话,则并发8个线程。
背景: 我现在在一个网站工作,每天都有很多网络爬虫和恶意攻击。我想根据http访问日志统计一下每个IP每天的访问次数,然后大于1万的都认为是机器人。现在寻求一个高效且实时的算法解决这个问题。 最简单的做法,就是用一个map来记录所有IP的访问次数。那么这可能会需要几百兆的内存。有一个更好的办法,可以在O(1)的空间复杂度中解决这个问题。

近3天十大热文
-
 [16] 浏览器的工作原理:新式网络浏览器幕后揭秘
[16] 浏览器的工作原理:新式网络浏览器幕后揭秘 -
[15] Go Reflect 性能
-
[13] iOS可视化编程 Tips 之“无需代码设置
-
[13] 界面设计速成
-
[13] iOS下自己动手造无限循环图片轮播
-
[13] Spark性能优化——和shuffle搏斗
-
[12] iTerm2 (Mac Terminal)
-
[12] 最萌域名.cat背后的故事:加泰与西班牙政府
-
[12] iOS并发编程(Concurrency Pr
-
[11] Android设计中的.9.png
赞助商广告
