您现在的位置:首页 --> 查看专题: 哈希

在记录的关键字与记录的存储地址之间建立的一种对应关系叫哈希函数。
哈希函数就是一种映射,是从关键字到存储地址的映射。
通常,包含哈希函数的算法的算法复杂度都假设为O(1),这就是为什么在哈希表中搜索数据的时间复杂度会被认为是”平均为O(1)的复杂度”.
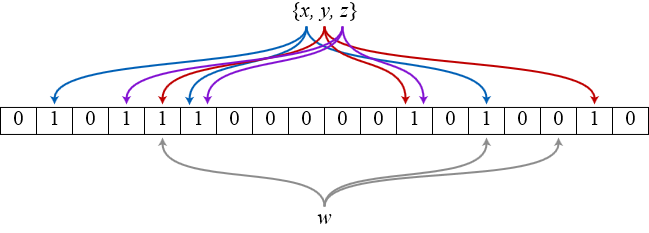
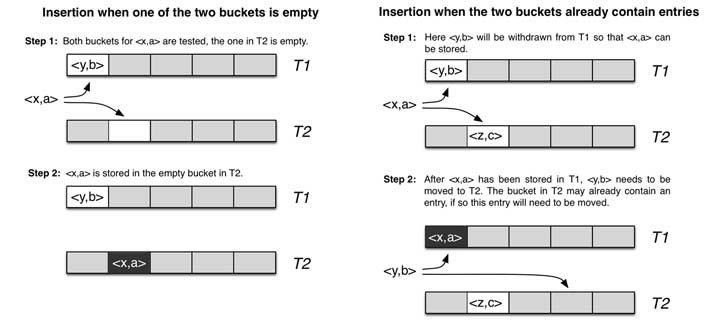
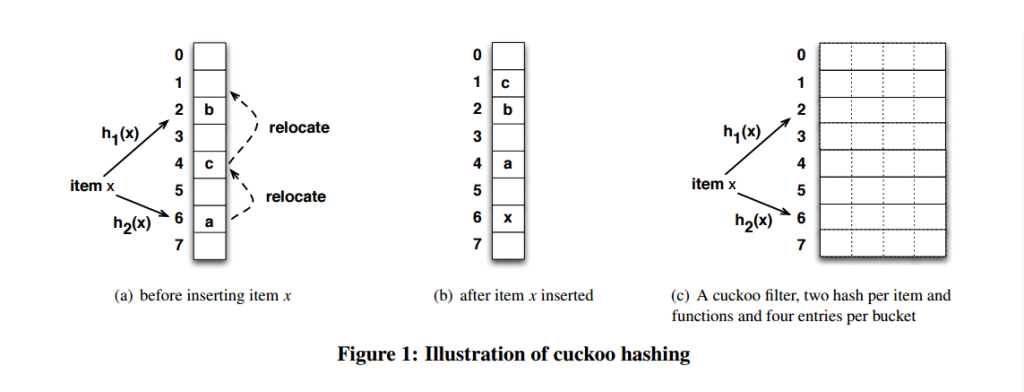
对于海量数据处理业务,我们通常需要一个索引数据结构,用来帮助查询,快速判断数据记录是否存在,这种数据结构通常又叫过滤器(filter)。考虑这样一个场景,上网的时候需要在浏览器上输入URL,这时浏览器需要去判断这是否一个恶意的网站,它将对本地缓存的成千上万的URL索引进行过滤,如果不存在,就放行,如果(可能)存在,则向远程服务端发起验证请求,并回馈客户端给出警告。
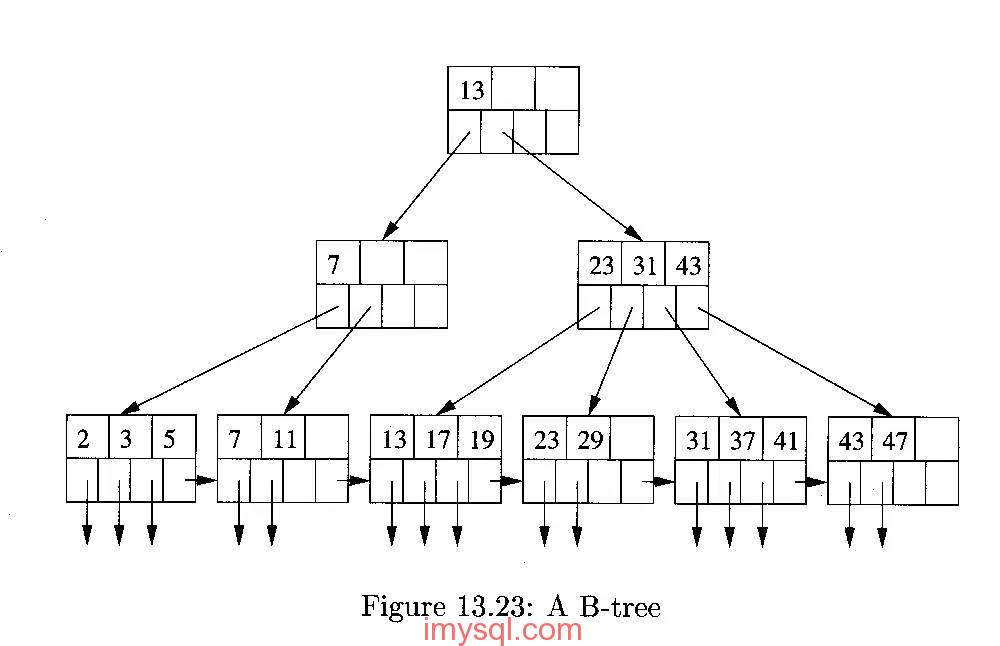
索引的存储又分为有序和无序,前者使用关联式容器,比如B树,后者使用哈希算法。这两类算法各有优劣:比如,关联式容器时间复杂度稳定O(logN),且支持范围查询;又比如哈希算法的查询、增删都比较快O(1),但这是在理想状态下的情形,遇到碰撞严重的情况,哈希算法的时间复杂度会退化到O(n)。因此,选择一个好的哈希算法是很重要的。

一致性hash算法提出了在动态变化的Cache环境中,判定哈希算法好坏的四个定义:
1、平衡性(Balance);
2、单调性(Monotonicity);
3、分散性(Spread);
4、负载(Load);
本文大致介绍了哈希的几种用途,有可能是大家熟知的用途,也有可能是巧用,总之就是说了为什么我要用哈希。
在编程中,无论是实际用途还是自己玩玩的题目,多动动脑子就会出来一些“奇技淫巧”。哈希也好,别的东西也罢,反正都是为了解决问题的——千万别因为实际开发中通常性的“并没有什么卵用”而去忽视它们,虽然哈希已经是够常用的了。
在JavaScript中存储键值对的一个简单常见的方法是使用对象字面量。然而,对象字面量不是真正意义上的哈希映射,如果使用不当可能会构成潜在的隐患。虽然目前JavaScript可能没有提供原生的hashmap(至少不能跨浏览器),对象字面量如果没有隐患就能达到所需的功能也许是一个更好的选择。




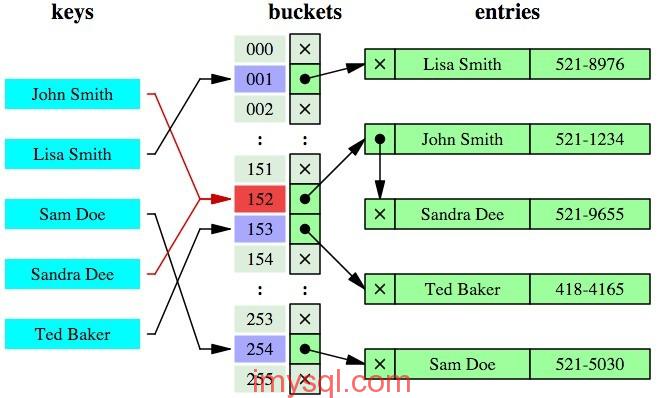
最近哈希表碰撞攻击(Hashtable collisions as DOS attack)的话题不断被提起,各种语言纷纷中招。本文结合PHP内核源码,聊一聊这种攻击的原理及实现。 哈希表碰撞攻击的基本原理 哈希表是一种查找效率极高的数据结构,很多语言都在内部实现了哈希表。PHP中的哈希表是一种极为重要的数据结构,不但用于表示Array数据类型,还在Zend虚拟机内部用于存储上下文环境信息(执行上下文的变量及函数均使用哈希表结构存储)。 理想情况下哈希表插入和查找操作的时间复杂度均为O(1),任何一个数据项可以在一个与哈希表长度无关的时间内计算出一个哈希值(key),然后在常量时间内定位到一个桶(术语bucket,表示哈希表中的一个位置)。
在向外发送数据包的时候,首先需要查询路由表来确定路由包的路由,主要由ip_route_output_key()函数来完成,该函数又调用了ip_route_output_flow(),而这个函数最终又调用了__ip_route_output_key()这个函数来进行路由的查询,下面主要来看一下这个函数。
1. 路由表 目前Linux内核中支持两种路由表,一种是Hash路由表,另一种是Trie路由表,Trie算法查找效率很高,但它也因极其消毫内存资源而闻名,因此一般用在大型机上,否则在路由项过多时很可能造成内存的耗尽。在一般的机器上最好还是使用Hash路由表,之前有争论说Linux使用Hash路由表相比于二叉树效率太低,不适合商用,其实只要设计良好的哈希算法,尽量减少哈希碰撞,Hash路由表的查找效率也是很高的,在最好的情况下算法复杂算可以达到O(1),当然,最差也不过是O(n),我们有理由相信Linux中存在各种优秀的哈希算法,这些都是值得我们学习的。
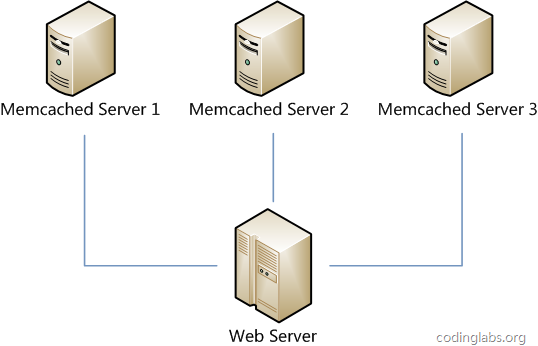
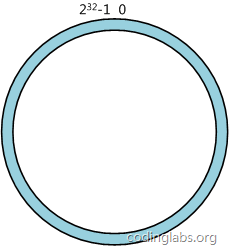
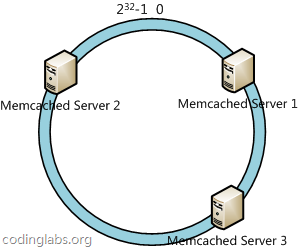
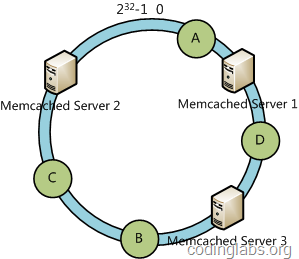
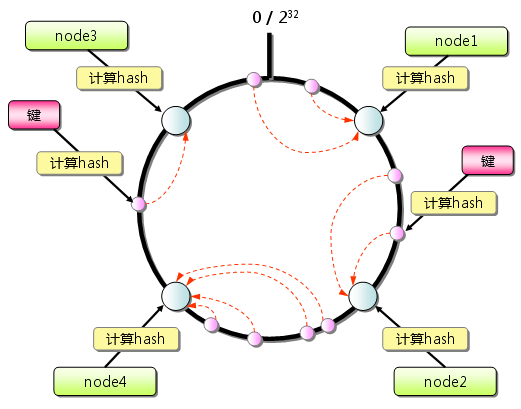
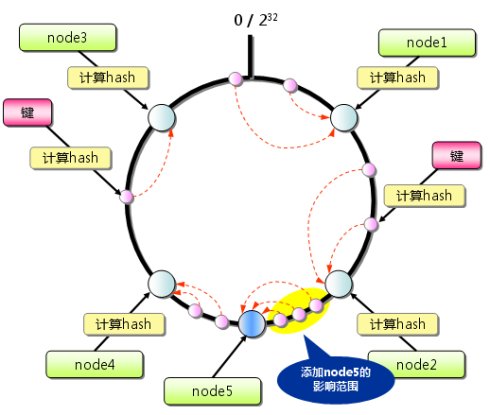
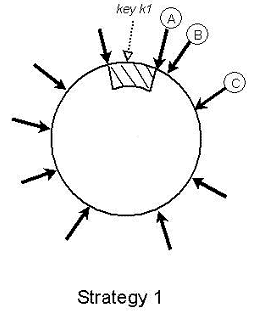
本文将会从实际应用场景出发,介绍一致性哈希算法(Consistent Hashing)及其在分布式系统中的应用。首先本文会描述一个在日常开发中经常会遇到的问题场景,借此介绍一致性哈希算法以及这个算法如何解决此问题;接下来会对这个算法进行相对详细的描述,并讨论一些如虚拟节点等与此算法应用相关的话题。
分布式哈希和一致性哈希是分布式存储和p2p网络中说的比较多的两个概念了。介绍的论文很多,这里做一个入门性质的介绍。
最近有一个server在重启的时候总要花费5分钟左右来加载配置文件,导致外网服务不可用,今天和几个同事一起研究了一下,总算找到了问题所在.
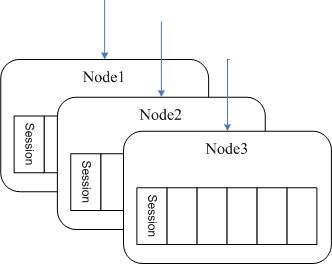
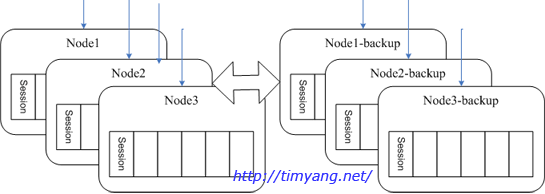
最近项目中一个分布式应用碰到一些设计问题,听过上次技术沙龙key value store漫谈的同学可能会比较容易理解以下说明。场景假定一个有状态的服务,可以理解成web或者socket服务器,每个用户在这个服务上登录后是有状态的,我们把它的状态连同其他加载到内存的用户数据统称用户session。由于session数据实时会变化,加上程序访问session频率大,几乎所有的操作都跟session数据相关,因此不适合放在远程memcached中第一阶段考虑...
[ 共14篇文章 ][ 第1页/共1页 ][ 1 ]
近3天十大热文
-
 [18] [译]Google Chrome中的高性能网
[18] [译]Google Chrome中的高性能网 -
[17] Go Reflect 性能
-
[16] Linux常用系统信息查看命令
-
[16] 关于Linux的文件系统cache
-
[16] 在FreeNAS/BSD搭建基于Nginx+
-
[15] 最近总结的一些技巧(vim,python,s
-
[11] PHP加速器 eaccelerator 缓存
-
[9] base64_encode 和 urlenc
-
[9] Linux(Ubuntu 10.04)上安装
-
[9] 精于图片处理的10款jQuery插件
赞助商广告
