最近哈希表碰撞攻击(Hashtable collisions as DOS attack)的话题不断被提起,各种语言纷纷中招。本文结合PHP内核源码,聊一聊这种攻击的原理及实现。
哈希表碰撞攻击的基本原理
哈希表是一种查找效率极高的数据结构,很多语言都在内部实现了哈希表。PHP中的哈希表是一种极为重要的数据结构,不但用于表示Array数据类型,还在Zend虚拟机内部用于存储上下文环境信息(执行上下文的变量及函数均使用哈希表结构存储)。
理想情况下哈希表插入和查找操作的时间复杂度均为O(1),任何一个数据项可以在一个与哈希表长度无关的时间内计算出一个哈希值(key),然后在常量时间内定位到一个桶(术语bucket,表示哈希表中的一个位置)。当然这是理想情况下,因为任何哈希表的长度都是有限的,所以一定存在不同的数据项具有相同哈希值的情况,此时不同数据项被定为到同一个桶,称为碰撞(collision)。哈希表的实现需要解决碰撞问题,碰撞解决大体有两种思路,第一种是根据某种原则将被碰撞数据定为到其它桶,例如线性探测——如果数据在插入时发生了碰撞,则顺序查找这个桶后面的桶,将其放入第一个没有被使用的桶;第二种策略是每个桶不是一个只能容纳单个数据项的位置,而是一个可容纳多个数据的数据结构(例如链表或红黑树),所有碰撞的数据以某种数据结构的形式组织起来。
不论使用了哪种碰撞解决策略,都导致插入和查找操作的时间复杂度不再是O(1)。以查找为例,不能通过key定位到桶就结束,必须还要比较原始key(即未做哈希之前的key)是否相等,如果不相等,则要使用与插入相同的算法继续查找,直到找到匹配的值或确认数据不在哈希表中。
PHP是使用单链表存储碰撞的数据,因此实际上PHP哈希表的平均查找复杂度为O(L),其中L为桶链表的平均长度;而最坏复杂度为O(N),此时所有数据全部碰撞,哈希表退化成单链表。下图PHP中正常哈希表和退化哈希表的示意图。
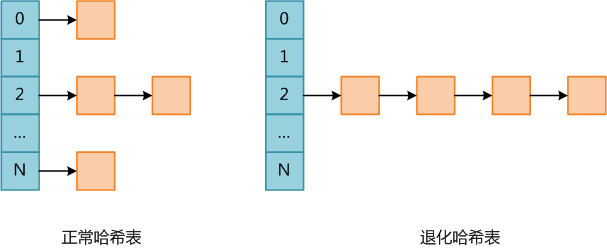
哈希表碰撞攻击就是通过精心构造数据,使得所有数据全部碰撞,人为将哈希表变成一个退化的单链表,此时哈希表各种操作的时间均提升了一个数量级,因此会消耗大量CPU资源,导致系统无法快速响应请求,从而达到拒绝服务攻击(DoS)的目的。
可以看到,进行哈希碰撞攻击的前提是哈希算法特别容易找出碰撞,如果是MD5或者SHA1那基本就没戏了,幸运的是(也可以说不幸的是)大多数编程语言使用的哈希算法都十分简单(这是为了效率考虑),因此可以不费吹灰之力之力构造出攻击数据。下一节将通过分析Zend相关内核代码,找出攻击哈希表碰撞攻击PHP的方法。
Zend哈希表的内部实现
数据结构
PHP中使用一个叫Backet的结构体表示桶,同一哈希值的所有桶被组织为一个单链表。哈希表使用HashTable结构体表示。相关源码在zend/Zend_hash.h下:
typedef struct bucket {
ulong h; /* Used for numeric indexing */
uint nKeyLength;
void *pData;
void *pDataPtr;
struct bucket *pListNext;
struct bucket *pListLast;
struct bucket *pNext;
struct bucket *pLast;
char arKey[1]; /* Must be last element */
} Bucket;
typedef struct _hashtable {
uint nTableSize;
uint nTableMask;
uint nNumOfElements;
ulong nNextFreeElement;
Bucket *pInternalPointer; /* Used for element traversal */
Bucket *pListHead;
Bucket *pListTail;
Bucket **arBuckets;
dtor_func_t pDestructor;
zend_bool persistent;
unsigned char nApplyCount;
zend_bool bApplyProtection;
#ifZEND_DEBUG
int inconsistent;
#endif
} HashTable;字段名很清楚的表明其用途,因此不做过多解释。重点明确下面几个字段:Bucket中的“h”用于存储原始key;HashTable中的nTableMask是一个掩码,一般被设为nTableSize - 1,与哈希算法有密切关系,后面讨论哈希算法时会详述;arBuckets指向一个指针数组,其中每个元素是一个指向Bucket链表的头指针。
哈希算法
PHP哈希表最小容量是8(2^3),最大容量是0×80000000(2^31),并向2的整数次幂圆整(即长度会自动扩展为2的整数次幂,如13个元素的哈希表长度为16;100个元素的哈希表长度为128)。nTableMask被初始化为哈希表长度(圆整后)减1。具体代码在zend/Zend_hash.c的_zend_hash_init函数中,这里截取与本文相关的部分并加上少量注释。
ZEND_API int_zend_hash_init(HashTable *ht, uintnSize, hash_func_t pHashFunction, dtor_func_t pDestructor, zend_bool persistent ZEND_FILE_LINE_DC)
{
uinti = 3;
Bucket **tmp;
SET_INCONSISTENT(HT_OK);
//长度向2的整数次幂圆整
if(nSize >= 0x80000000) {
/* prevent overflow */
ht->nTableSize = 0x80000000;
} else{
while((1U << i) < nSize) {
i++;
}
ht->nTableSize = 1<< i;
}
ht->nTableMask = ht->nTableSize - 1;
/*此处省略若干代码…*/
returnSUCCESS;
}值得一提的是PHP向2的整数次幂取圆整方法非常巧妙,可以背下来在需要的时候使用。
Zend HashTable的哈希算法异常简单:
=key&nTableMask")
即简单将数据的原始key与HashTable的nTableMask进行按位与即可。
如果原始key为字符串,则首先使用Times33算法将字符串转为整形再与nTableMask按位与。
下面是Zend源码中查找哈希表的代码:
ZEND_API int zend_hash_index_find(constHashTable *ht, ulong h, void **pData)
{
uint nIndex;
Bucket *p;
IS_CONSISTENT(ht);
nIndex = h & ht->nTableMask;
p = ht->arBuckets[nIndex];
while(p != NULL) {
if((p->h == h) && (p->nKeyLength == 0)) {
*pData = p->pData;
returnSUCCESS;
}
p = p->pNext;
}
returnFAILURE;
}
ZEND_API int zend_hash_find(constHashTable *ht, constchar *arKey, uint nKeyLength, void **pData)
{
ulong h;
uint nIndex;
Bucket *p;
IS_CONSISTENT(ht);
h = zend_inline_hash_func(arKey, nKeyLength);
nIndex = h & ht->nTableMask;
p = ht->arBuckets[nIndex];
while(p != NULL) {
if((p->h == h) && (p->nKeyLength == nKeyLength)) {
if(!memcmp(p->arKey, arKey, nKeyLength)) {
*pData = p->pData;
returnSUCCESS;
}
}
p = p->pNext;
}
returnFAILURE;
}其中zend_hash_index_find用于查找整数key的情况,zend_hash_find用于查找字符串key。逻辑基本一致,只是字符串key会通过zend_inline_hash_func转为整数key,zend_inline_hash_func封装了times33算法,具体代码就不贴出了。
攻击
基本攻击
知道了PHP内部哈希表的算法,就可以利用其原理构造用于攻击的数据。一种最简单的方法是利用掩码规律制造碰撞。上文提到Zend HashTable的长度nTableSize会被圆整为2的整数次幂,假设我们构造一个2^16的哈希表,则nTableSize的二进制表示为:1 0000 0000 0000 0000,而nTableMask = nTableSize - 1为:0 1111 1111 1111 1111。接下来,可以以0为初始值,以2^16为步长,制造足够多的数据,可以得到如下推测:
0000 0000 0000 0000 0000 & 0 1111 1111 1111 1111 = 0
0001 0000 0000 0000 0000 & 0 1111 1111 1111 1111 = 0
0010 0000 0000 0000 0000 & 0 1111 1111 1111 1111 = 0
0011 0000 0000 0000 0000 & 0 1111 1111 1111 1111 = 0
0100 0000 0000 0000 0000 & 0 1111 1111 1111 1111 = 0
……
概况来说只要保证后16位均为0,则与掩码位于后得到的哈希值全部碰撞在位置0。
下面是利用这个原理写的一段攻击代码:
<?php
$size= pow(2, 16);
$startTime= microtime(true);
$array= array();
for($key= 0, $maxKey= ($size- 1) * $size; $key<= $maxKey; $key+= $size) {
$array[$key] = 0;
}
$endTime= microtime(true);
echo $endTime- $startTime, " seconds";这段代码在我的VPS上(单CPU,512M内存)上用了近88秒才完成,并且在此期间CPU资源几乎被用尽:
![]()
![]()
而普通的同样大小的哈希表插入仅用时0.036秒:
<?php
$size= pow(2, 16);
$startTime= microtime(true);
$array= array();
for($key= 0, $maxKey= ($size- 1) * $size; $key<= $size; $key+= 1) {
$array[$key] = 0;
}
$endTime= microtime(true);
echo $endTime- $startTime, " seconds";![]()
可以证明第二段代码插入N个元素的时间在O(N)水平,而第一段攻击代码则需O(N^2)的时间去插入N个元素。
POST攻击
当然,一般情况下很难遇到攻击者可以直接修改PHP代码的情况,但是攻击者仍可以通过一些方法间接构造哈希表来进行攻击。例如PHP会将接收到的HTTP POST请求中的数据构造为$_POST,而这是一个Array,内部就是通过Zend HashTable表示,因此攻击者只要构造一个含有大量碰撞key的post请求,就可以达到攻击的目的。具体做法不再演示。
防护
POST攻击的防护
针对POST方式的哈希碰撞攻击,目前PHP的防护措施是控制POST数据的数量。在>=PHP5.3.9的版本中增加了一个配置项max_input_vars,用于标识一次http请求最大接收的参数个数,默认为1000。因此PHP5.3.x的用户可以通过升级至5.3.9来避免哈希碰撞攻击。5.2.x的用户可以使用这个patch:http://www.laruence.com/2011/12/30/2440.html。
另外的防护方法是在Web服务器层面进行处理,例如限制http请求body的大小和参数的数量等,这个是现在用的最多的临时处理方案。具体做法与不同Web服务器相关,不再详述。
其它防护
上面的防护方法只是限制POST数据的数量,而不能彻底解决这个问题。例如,如果某个POST字段是一个json数据类型,会被PHPjson_decode,那么只要构造一个超大的json攻击数据照样可以达到攻击目的。理论上,只要PHP代码中某处构造Array的数据依赖于外部输入,则都可能造成这个问题,因此彻底的解决方案要从Zend底层HashTable的实现动手。一般来说有两种方式,一是限制每个桶链表的最长长度;二是使用其它数据结构如红黑树取代链表组织碰撞哈希(并不解决哈希碰撞,只是减轻攻击影响,将N个数据的操作时间从O(N^2)降至O(NlogN),代价是普通情况下接近O(1)的操作均变为O(logN))。
目前使用最多的仍然是POST数据攻击,因此建议生产环境的PHP均进行升级或打补丁。至于从数据结构层面修复这个问题,目前还没有任何方面的消息。
参考
[1] Supercolliding a PHP array
[2] PHP5.2.*防止Hash冲突拒绝服务攻击的Patch
[4] PHP数组的Hash冲突实例