在我的插件Super Static Cache的使用过程中,经常会有人问我这样的问题,怎么样让Super Static Cache插件支持我的HTML压缩插件,本文这里不谈技术实现问题,着重来分析一下现在的网站有没有必要再进行HTML代码压缩。
代码压缩压缩的是什么?
HTML的全称是超文本标记语言,HTML网页本身是一种文本文件,通过在文件中添加标记符,可以告诉浏览器如何显示其中的内容,包括文字大小,颜色,图片显示等等。这就意味着在文本文件中的一些特定意义的字符可以在浏览器显示的时候就不一样了,HTML代码压缩就是压缩这些在文本文件中有意义,但是在HTML中不显示的字符,包括空格,制表符,换行符等,还有一些其他意义的字符,如HTML注释也可以被压缩。
有了这个基础,我们挑选网络上的100张未经过HTML压缩的页面进行统计。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import urllib2,re
import matplotlib.pyplot as plt
htmlsp = re.compile(r"[\r\n\t]")
def htmlcompress(html):
html = htmlsp.sub("",html)
return html.replace(" ","")
urls = open("urls.txt","rb")
comdation = list()
while True:
url = urls.readline()
if not url:
break
if not len(url):
continue
try:
content = urllib2.urlopen(url).read()
except:
continue
unlen = len(content)
comlen = len(htmlcompress(content))
comra = 100.0*(unlen*1.0-comlen*1.0)/unlen
obj = "uncompress:%d bit, compress:%d bit, compressdatio: %f%%"%(unlen,comlen,comra)
print obj
comdation.append(comra)
plt.ylabel("compressdatio")
plt.plot(comdation)
plt.show()
其压缩率分布图如下: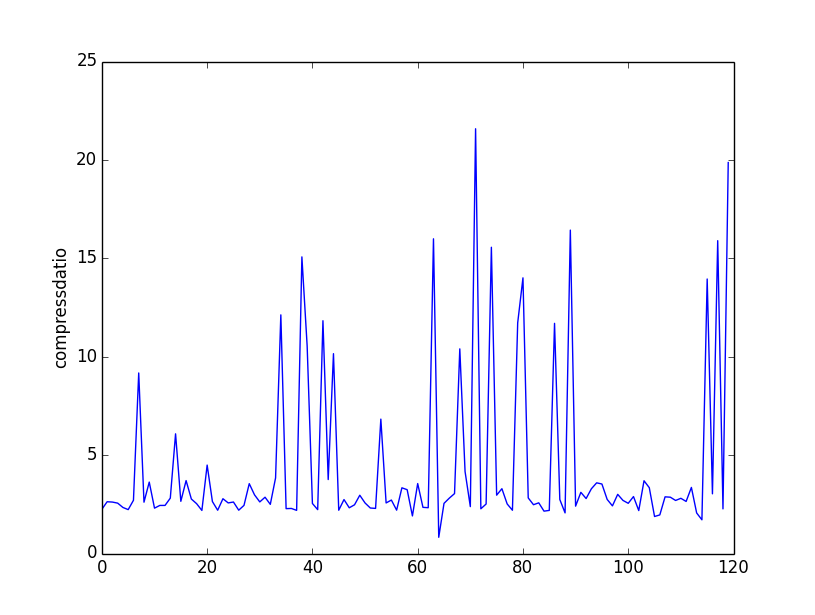
从图中可以看到,压缩率最高的可以达到20%还多, 那是不是就意味着HTML有必要呢?实际上我们忘了,HTML属于文本数据,如果服务器上采用好的压缩算法,它的压缩律是非常高的,现在世界上有接近70%的服务器采用Gzip压缩算法1,如果我本身的HTML传送采用Gzip压缩,和HTML压缩有什么联系呢,来看一下下面的程序分析:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import urllib2,re
import matplotlib.pyplot as plt
import gzip,StringIO
htmlsp = re.compile(r"[\r\n\t]")
def htmlcompress(html):
html = htmlsp.sub("",html)
return html.replace(" ","")
def gzipcompress(html):
buf = StringIO.StringIO()
f = gzip.GzipFile(mode="wb",fileobj = buf)
f.write(html)
f.close()
return buf.getvalue()
urls = open("urls.txt","rb")
unlenlist = list()
comlenlist = list()
gzipcomlenlist = list()
gzipcomhtmllenlist = list()
while True:
url = urls.readline()
if not url:
break
if not len(url):
continue
try:
content = urllib2.urlopen(url).read()
except:
continue
unlen = len(content)
comlen = len(htmlcompress(content))
gzipcomlen = len(gzipcompress(content))
gzipcomhtmllen = len(gzipcompress(htmlcompress(content)))
unlenlist.append(unlen)
comlenlist.append(comlen)
gzipcomlenlist.append(gzipcomlen)
gzipcomhtmllenlist.append(gzipcomhtmllen)
plt.ylabel("HTML Length(bit)")
plt.xlabel("WebSite")
plt.plot(unlenlist,"b")
plt.plot(comlenlist,"r")
plt.plot(gzipcomlenlist,"y")
plt.plot(gzipcomhtmllenlist,"k")
plt.show() 分布图如下:
图中蓝线表示原始的网页大小,红线表示HTML压缩的大小,黄线表示Gzip压缩原始文件的大小,黑线表示Gzip压缩HTML压缩文件的大小,可以得出两个结论:
1, 只有在原始网页文件比较大时候,HTML压缩才会节省一些空间
2, 只要服务器开启Gzip压缩,网页HTML是否压缩对整个网页传送体积影响不大
所以我们可以得出结论,HTML压缩本身对网站性能提升意义并不大,最多只能混淆一下让其他人难以查看,但是越来越多的前端工具已经让这种做法变得越来越没有意义,反而影响自己的开发,所以,放弃HTML压缩吧。
当然,这个结论也不是在所有情况下都成立,当你的访客足够多的时候,节省一个字节的大小可能都会导致大量的成本节省,以google为例,他的互联网占到整个互联网流量的40%2,而思科预计2016年全球网络流量将会达到1.3ZB(1ZB = 10^9TB)3,如果Google给每1MB的请求减少1字节,则每年可以节省流量近500TB。