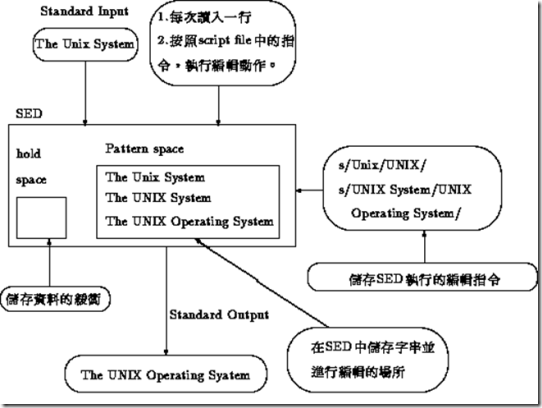
系统工程师的自我修养- sed篇
这篇文章系统地梳理了传统UNIX环境下的sed工具,从底层原理讲起,特别强调了其基于pattern space逐行处理的核心机制,与GNU版本做了区分。作者清晰地界定了sed与awk的适用场景:sed长于行内的强大替换与编辑,适合做“文本编辑器”;而awk更擅长列的提取与格式化,是“信息处理器”。 文章没有堆砌所有命令,而是直接从实战出发。在讲解了如何用SELECTION(行号、正则)精确选取目标文本后,通过一系列电话簿、路径、配置文件的示例,演示了打印(-p)、插入(i)、追加(a)和替换(c)这些最常用的操作。作者的讲解紧密结合了sed“读取-处理-输出”的工作流程,比如在解释`-n`选项时,就回溯到默认输出pattern space的原理,让读者知其然更知其所以然。 整体来看,这是一篇不求大而全,但求小而精的实践指南。它把sed的核心骨架和最实用的“几把刷子”清晰地呈现出来,非常适合想要快速掌握sed行处理精髓的系统工程师作为入门和速查参考。
Mac下处理PC以^M结尾的文本
这篇文章解决的是在 Mac 系统下处理来自 Windows 的文本文件时,行尾出现多余 `^M` 字符(回车符)的常见问题。作者首先清晰地对比了不同系统的行末符差异:Unix/Linux 使用换行符 `\n`,老版本 Mac OS 使用回车符 `\r`,而 Windows 则使用回车换行组合符 `\r\n`。这种不匹配正是导致文本在 Mac 终端或编辑器中显示异常的根源。 文章接着提供了非常直接且实用的解决方案。作者引用 Stack Overflow 上的讨论,指出使用 `awk` 命令并指定记录分隔符 `RS` 为 `\r\n`,就能正确解析并处理这类文件,例如 `awk -v RS='\\r\\n' foo.log`。这个方法比手动替换字符更高效,也更精准。 对于开发者而言,理解这些底层差异并在处理跨平台数据时选择合适的工具,是提升效率、避免“踩坑”的关键。本文从现象到原理再到具体命令,提供了一次简明而完整的技术点拨。
Linux 运维:系统服务管理
这篇讲的是Linux服务器运维中那些令人头疼的“重复学习”时刻——系统服务管理的方式总是随着技术演进而变迁。作者从自己给老款MacBook Pro安装Ubuntu 19.04桌面版出发,先吐槽了新版apt命令依然不够顺手,并演示了如何用aptitude替换掉默认的vim-tiny、补装net-tools这些桌面版缺失的基础工具。 文章的重点其实落在CentOS的服务管理上。作者并排展示了两种新老方式的实操命令:一边是逐渐被淘汰的SysV风格,用`chkconfig`查看、关闭或删除服务;另一边是主流的systemd,通过`systemctl`来列出、禁用服务状态。他甚至演示了如何暴力删除阿里云相关服务的残留文件,再用`reset-failed`清理干净——这恰恰是运维中常遇到的“清理战场”场景。 如果你正被服务器上那些幽灵般的服务困扰,或者面对不同发行版时对管理命令感到混乱,这篇文章给出的对比和具体步骤,就像一份可以直接“照着做”的速查手册。它不空谈理论,而是把折腾的过程和关键命令直接摊开,对实际排障很有参考价值。
如何在 Linux 上复制文件/文件夹到远程系统?
这篇讲的是 Linux 用户日常一定会遇到的场景:怎么把本地的文件或文件夹高效地复制到远程服务器上。作者没有停留在只讲最常用的 `scp`,而是系统梳理了四种主流方案——`scp`、`rsync`、`pscp` 和 `prsync`,并详细解释了它们各自的设计思路和适用情况。 比如,`scp` 作为原生命令,安全可靠,适合快速单次传输;`rsync` 则胜在支持增量同步与断点续传,尤其适合大文件或经常变动的目录。而 `pscp` 和 `prsync` 是进阶工具,专门解决“同时把文件推送到多台服务器”的批量运维需求,提供了超时控制等实用特性。文章不仅列出了这些差异,还给出了可直接复制的命令行示例,从基础用法到多文件、多目录的复制场景都有覆盖。 作者强调这些方法都经过了实际环境的测试,确保读者拿来就能用。对于需要在不同生产环境中选择合适传输工具的开发者或运维人员来说,这份整理提供了一个清晰的决策参考。
系统管理员的 7 个 CI/CD 工具
这篇讲的是,当运维团队需要像开发一样熟练运用 CI/CD 时,该如何选择趁手的工具。作者从运维的视角出发,对比了七款主流工具的设计哲学与适用场景。 文章并没有停留在泛泛而谈,而是深入到具体工具的细节。例如,它指出 GitLab CI 凭借 YAML 声明式管道和 Auto DevOps 功能,在 Forrester 评估中名列前茅;GoCD 的杀手锏是“价值流视图”,适合需要串联多团队流水线的复杂组织;而像 Travis CI 这样的 SaaS 服务,则为开源项目提供了几乎零成本的起点。对于 Jenkins 这样的“元老”,文章既承认了其配置复杂的历史包袱,也点出了 Jenkins X 等项目向云原生转型的新方向。 作者的核心观点是,这些工具模型各异,但目标一致:通过自动化节省时间、提升可靠性。文章没有给出唯一答案,而是提供了一份详尽的“选型地图”。它帮助系统管理员理解,选择工具不仅要看功能列表,更要匹配团队的成熟度、协作流程以及对“基础设施即代码”的接纳程度。读完后,你可以根据自身团队的现状,找到那个能最快帮你“搭建起脚手架”的起点。
Bash 中的 & 符号和文件描述符
这篇讲的是 Bash 中 `&` 符号和文件描述符的深入应用,远不止于用 `&` 把进程丢到后台那么简单。作者从大家熟悉的 `>` 重定向出发,点明了其背后的实质——文件描述符 `1`(标准输出)。接着,文章系统地梳理了 `0`(标准输入)、`1`(标准输出)和 `2`(标准错误)这三个标准文件描述符,并展示了如何用它们精准控制命令的输出流向。 文章的核心亮点在于剖析了文件描述符操作的“顺序陷阱”。例如,`find ... 1>services.txt 2>&1` 能成功将所有结果(包括错误)写入文件,但仅仅调换顺序变成 `2>&1 1>services.txt`,错误信息就会直接打印到终端。作者通过 Bash 从左到右的处理逻辑解释了其中的原因:文件描述符是“通道”,在打开 `1` 指向文件之后,再将 `2` 导向 `1`,错误才会正确流入文件。 最后,文章回归到 `&` 的另一个关键角色,介绍了 `&>` 这个简洁的语法糖,它等价于 `2>&1`,能一步到位地合并标准输出和标准错误。掌握文件描述符的工作原理,是写出健壮、可控的 Bash 脚本的重要一步。
一文入门 Makefile
这篇讲的是如何用一份清晰的指南,帮助开发者快速掌握 Makefile 这一经典工程工具。作者从企业项目多源文件编译的混乱场景切入,点明了 Makefile 作为“编译规则定义者”的核心角色——它决定了文件编译的先后顺序与触发条件,一个 `make` 命令就能管理整个构建流程。 文章没有堆砌所有特性,而是紧扣实用性,剖析了 Makefile 的三个核心优势:智能管理编译依赖、通过增量更新节省时间、以及编写一次长期有效的便利性。它详细拆解了“目标: 依赖 -> 规则”这一基本语法格式,并借助图解阐明了 Makefile “向下查找依赖、向上执行生成”的工作原理。 更进一步,文章介绍了提升编写效率的关键技巧,包括使用 `$@`、`$^` 等自动变量,以及利用 `wildcard` 和 `patsubst` 函数来批量处理文件。这些内容覆盖了从入门到进行常规项目配置所需的实用知识,对于理解 Linux 环境下的自动化构建思想很有帮助。
在 Linux 中运行特定命令而无需 sudo 密码
这篇讲的是如何在自动化运维场景中,为特定Linux用户开放免密执行sudo命令的权限。作者从一个实际问题出发:在AWS的Ubuntu服务器上,需要一个每分钟运行的脚本来检查并自动重启某个服务,但执行启动命令必须使用sudo权限,而交互式输入密码与自动化目标冲突。 文章的核心方案是通过编辑`/etc/sudoers`文件,使用`visudo`工具安全地为指定用户(如`sk`)添加一条规则,例如`sk ALL=NOPASSWD:/bin/mkdir`。这样,该用户执行这条特定命令时便无需输入密码。作者详细演示了如何为命令添加多个以逗号分隔的权限项(如同时为`mkdir`、`chmod`和`apt`命令授权),并特别强调了必须使用命令的绝对路径(可通过`whereis`命令查找)。 此外,文章还介绍了如何混合配置免密和需密命令(如在配置行中加入`PASSWD:`前缀来指定需要密码的命令),以及如何撤销这些权限。最后,作者给出了重要的安全警告:免密码执行sudo命令是一把双刃剑,配置不当(例如为`rm`命令开放权限)可能导致数据误删等严重后果,使用时务必谨慎。整篇文章提供了一个清晰、可操作的自动化运维技巧,同时也强调了安全边界。
如何在 Linux 上安装设备驱动程序
这篇讲的是,那些从 Windows 或 macOS 切换到 Linux 的朋友,面对设备驱动安装时可能会懵——因为 Linux 上这事儿确实更复杂。作者从三种根本原因出发:Linux 发行版种类繁多、大多数开源驱动已内置、以及不同发行版对闭源驱动的许可策略不同,清晰地解释了为什么一个通用的安装指南很难实现。 文章没有停留在抱怨上,而是给出了两种切实可行的解决方案:一种是通过 Ubuntu 的“附加驱动”等图形化向导进行傻瓜式安装;另一种是针对进阶用户的命令行途径,包括添加软件仓库、更新源并安装,甚至涉及手动下载源码编译。作者还贴心地列举了 `lspci`、`dmesg` 和 `lsmod` 等关键命令,教你在动手前如何高效地检查系统是否已存在或加载了目标驱动,避免重复劳动。 整篇文章像一份务实的路线图,它先帮你理解问题的来龙去脉,再提供从简到难的工具选择,最后附上了必不可少的诊断步骤。对于想踏足 Linux 但又怕被驱动问题劝退的新手来说,这是一份很清晰的入门指引。
Python检查和同步本地时间北京时间
这篇讲的是如何用Python快速检查与同步本地服务器时间到北京时间。作者从一个实际运维痛点出发:当本地时间与标准时间偏差较大时,传统的NTP时间同步过程会非常缓慢,影响服务。 为了解决这个问题,文章提出了一种轻巧的替代方案:利用大型网站(如百度、淘宝)响应的HTTP头中包含的Date时间戳。因为这些网站的时间通常非常准确,我们可以将它们作为一个可靠的时间源。核心思路就是通过代码获取这个GMT时间戳,将其解析并转换为北京时间,然后直接设置系统时钟。 具体实现上,代码使用了Python标准库urllib2以确保兼容性,而没有依赖需要额外安装的requests库。它封装了两个主要功能:检查本地时间与互联网时间的偏差,以及直接校准本地时间(包括将系统时间同步到硬件时钟)。作者提供了完整的脚本,并在CentOS 7.4的Python 2.7环境下验证通过。 这个方案虽然简单,但对于网络受限或对NTP同步速度有要求的场景,提供了一种快速、有效的应急选择。
Scrot:让你在命令行中进行截屏更加简单
很多人的习惯是使用图形界面工具来截屏,比如 Shutter 或系统自带的功能。但如果你在一台没有桌面环境的服务器上,或者在一台配置较低、不值得安装重型工具的老机器上,想快速抓一张图该怎么办?这篇讲的是一个久经考验的解决方案——命令行工具 Scrot。 文章开篇点明了 Scrot 的适用场景:当你需要轻量、快速的截屏,或者系统缺乏图形化工具时,它便能派上用场。接着,作者没有停留在“它能做什么”,而是深入演示了具体用法:从基础的全屏截图 `scrot [文件名]`,到使用 `-u` 参数截取当前窗口,再到用 `-s` 参数交互式地框选屏幕特定区域。为了让操作更实用,文章还详细解释了如何通过 `-d` 参数设置延迟截图,以便有足够时间切换到目标窗口。 除了核心功能,文中还补充了一些提升效率的实用选项,例如用 `-t` 生成方便分享的缩略图,以及用 `-c` 在延迟时显示倒计时。文章最后回归简单,指出 Scrot 虽然功能基础,但在其设计的初衷上做得非常可靠,尤其适合服务器运维或老设备等特定场景。
初学者指南:在 Ubuntu Linux 上安装和使用 Git 和 GitHub
对于刚开始接触 Linux 和版本控制的开发者来说,如何将本地代码可靠地同步到云端协作平台,往往是迈向开源世界的第一道坎。这篇文章就为 Ubuntu 用户提供了一份清晰、可操作的入门路线图。 它没有停留在抽象概念,而是直接从终端命令开始,手把手演示了在 Ubuntu 系统上完成 Git 安装、GitHub 账户配置、创建本地仓库、添加文件、提交更改,直至最终将整个项目推送到 GitHub 远程仓库的全过程。文章特别强调了几个关键步骤的实际操作:例如使用 `sudo apt-get install git` 进行安装,通过 `git config` 命令绑定你的用户名与邮箱,以及用 `git add` 和 `git commit` 来管理文件变更。这些步骤都配有具体的命令示例和效果截图,让读者能逐一对照执行。 整篇指南面向已注册 GitHub 账号、但对 Git 工作流尚不熟悉的 Linux 初学者。它省略了复杂的理论铺陈,聚焦于“如何让它跑起来”,非常适合想要立刻动手实践、将自己的第一个小项目托管到 GitHub 上的新手开发者。
如何从 Linux 命令行安装软件
这篇讲的是,即使在图形界面盛行的今天,许多资深Linux用户依然偏爱用命令行安装软件——因为它更快、更直接。文章从25年Linux用户的经验出发,介绍了包管理器的核心概念:它如何像一个智能助手,自动处理应用的安装、更新与依赖关系。 作者重点对比了两大主流系统:Debian、Ubuntu等基于`.deb`的发行版,常用`apt`或`dpkg`命令;而Red Hat、CentOS等基于`.rpm`的系统,则主要使用`yum`、`dnf`或`rpm`命令。文中清晰列出了从安装、卸载到升级的具体命令示例,比如`sudo apt install`与`sudo dnf install`,让读者能直观看到操作差异。 无论你使用哪种发行版,掌握对应的包管理命令行工具,都能让软件管理变得更高效。文章最后也提醒,一旦习惯了这种方式,你会发现它比图形界面工具还要快。
修改Linux交换空间的使用率
这篇讲的是如何调整 Linux 系统对交换空间(swap)的使用倾向,核心是控制一个名为 `vm.swappiness` 的内核参数。 文章解释说,这个参数的默认值是 60,数值越大,系统就越倾向于将内存中的数据交换到 swap 分区。作者指出,将其设为 0 并不会完全禁用 swap,只是最大限度地避免使用它。通过 `sysctl -q vm.swappiness` 命令可以查看当前设置。 修改参数需要编辑 `/etc/sysctl.conf` 文件,添加一行 `vm.swappiness=10`,然后重启系统生效。如果不想重启,也可以用 `sysctl -p` 动态加载,但建议操作前先清空 swap。文章给出了清空 swap 的具体命令:`swapoff -a && swapon -a`。 文章最后还补充了 Linux 内存分配的一个关键机制:系统会优先使用物理内存,即使程序关闭,其占用的内存也可能被用作缓存,以加快后续访问。调整 swappiness 参数的目的,就是尽量利用物理内存,减少因使用 swap 而带来的性能开销。
如何在 Linux 中使用 find
这篇讲的是如何真正发挥 Linux 中 `find` 命令的威力。作者从最简单的 `find /` 命令会输出海量无用信息这一常见困境出发,手把手地演示了如何通过组合使用各种参数,让这个工具变得精准而高效。 文章从查找指定名称(`-name`)和大小写不敏感(`-iname`)的基础开始,迅速引入了使用 `-o` 进行逻辑或组合,以及用 `-type` 区分文件与目录。这些是让搜索结果从“杂乱”变得“可用”的关键一步。接着,文章展示了更高级的过滤条件:如何通过 `-mtime` 按修改时间(如过去一周)筛选,通过 `-size` 找出占用大量空间的大文件,通过 `-owner` 定位特定用户拥有的文件,甚至通过 `-perm` 查找权限可能设置不当的文件。 作者并没有停留在列举参数上,而是强调 `find` 的真正潜力在于将这些测试条件与布尔逻辑结合,并最终可以通过 `-exec` 或 `-delete` 对找到的文件直接执行操作。整篇文章从一个朴素的需求切入,层层递进地给出了解决方案,完整展现了如何将一个基础命令用成系统管理的利器。
使用 syslog-ng 可靠地记录物联网事件
面对日益增多的物联网设备,可靠地记录和监控其运行事件,是排查问题与保障安全的基础。这篇文章以开源日志守护程序 syslog-ng 为例,详解了如何构建一个高效、可移植的集中式日志方案。 作者从日志的基础概念讲起,重点剖析了 syslog-ng 的四大核心能力:从多样来源(如系统日志、文件、管道)收集信息;通过解析器、重写等功能处理日志;基于内容进行智能过滤与路由;最终将日志保存至文件或 Elasticsearch、Kafka 等大数据平台。文章特别强调了将非结构化日志转换为键值对格式的价值,这能极大提升后续分析的效率。 更值得关注的是 syslog-ng 在真实物联网场景中的广泛应用。文中提到,其最流行的版本(1.6)竟运行在超过 1 亿台亚马逊 Kindle 设备上,同时也被用于宝马电动汽车、开源路由器和工业测量设备中。对于资源受限或异构的嵌入式环境,syslog-ng 的高性能与多架构支持显得尤为实用。 总结来看,syslog-ng 通过其灵活的架构,将系统日志、应用数据乃至测量信息统一收集和处理,为物联网设备提供了从边缘到中心的可靠日志管道,有效支撑了监控、安全与数据分析的需求。
假装很忙的三个命令行工具
这篇文章从一个有趣的观察切入:电影里那些酷炫的黑客屏幕,在现实中往往只是“假装很忙”的道具。作者调侃地介绍了三个开源命令行工具,来满足这种独特的“表演需求”。 第一个是 Genact,它能模拟内核编译、数字货币挖矿或文件下载等场景,让你的终端看起来一直在“努力工作”,甚至还能显示类似《模拟城市》的加载进度条。第二个是 Hollywood,它更简单粗暴,直接在终端里随机分屏,并快速切换显示 htop、目录树等看起来很忙碌的内容。第三个是作者最常用的 Blessed-contrib,它本质是个构建终端仪表盘的 Node.js 库,能轻松生成带图表和地图的数据可视化界面,填充上虚拟数据,科幻感直接拉满。 文章最后也提醒,这类工具更像是极客的玩笑,如果公司文化真的以“忙碌程度”评判员工,那本身就是一个亟待解决的问题。作者还提到了著名网络扫描工具 Nmap 因频繁出现在好莱坞电影中,甚至专门建了个页面来展示这些“出镜”记录。
每个 Linux 新手都应该知道的 10 个命令
这篇讲的是,看似熟悉的互联网其实运行在 Linux 之上——从 Android 手机到超级计算机,90% 的网络服务器都依赖它。文章从这个事实出发,为那些想从桌面环境踏入命令行世界的用户,梳理了必须掌握的10个基础命令。 作者没有停留在概念层面,而是具体展示了每个命令的用途和细节。例如,`ls` 用来查看文件目录,`cd` 用于目录跳转(并解释了目录名含空格时需用反斜杠),`mv` 负责移动文件。文章还特别整理了一组能大幅提升效率的终端快捷键,比如用 `CTRL+K` 剪切、`ALT+B` 按词回退,并举例说明如何快速修正命令行中的拼写错误。 这些命令构成了与 Linux 系统交互的基础语法。掌握它们,你就能创建 (`mkdir`, `touch`)、查找 (`locate`)、移动 (`mv`) 乃至删除 (`rm`, `rmdir`) 文件与目录,并设置定时任务 (`at`)。作者将它们称为“简单却有用”,正是因为它们是理解更复杂系统操作的第一步。
10 条加速 Ubuntu Linux 的杀手级技巧
这篇讲的是如何让变慢的Ubuntu系统重新快起来。文章没有空谈理论,而是直接给出了10个实操性强的“杀手级技巧”,针对的是Ubuntu用久了难免出现的卡顿问题。 作者从系统变慢的常见原因切入,然后逐一拆解解决方案。这些技巧覆盖了从开机启动(缩短Grub等待、管理自启动应用)、软件安装(用preload预加载、用apt-fast加速下载),到运行时优化(控制过热、调整LibreOffice内存)等多个层面。比如,通过一个简单的`sleep`命令就能延迟非必需程序的启动,或者通过调整软件源来加速更新,这些都是立竿见影的小改动。 文章特别贴心地指出,这些方法不仅适用于Ubuntu,也适用于Linux Mint等基于Ubuntu的发行版。对于老旧硬件或追求流畅体验的用户,其中关于切换到Xfce或LXDE等轻量级桌面环境的建议,提供了进一步的优化思路。整篇文章就像一份针对系统“新陈代谢”的调理方案,通过一点一滴的设置累积,最终能换回一个更迅捷的工作环境。
如何在 Linux 中的特定时间运行命令
这篇讲的是,在Linux系统里如何为一条命令设定执行时限,时间一到就自动让它“收工”。文章的出发点很实际:作者用 `rsync` 传输大文件时,既不想干等20分钟,又不想手动中断进程。他发现系统里其实有现成的工具能轻松实现“定时关闭”。 文章核心介绍了两种解决方案。最常用的是 `timeout` 命令,它属于GNU coreutils包,几乎开箱即用。用法很简单,例如 `timeout 10s tail -f /var/log/pacman.log` 就能让 `tail` 命令只运行10秒。它还支持分钟(m)、小时(h)、天(d)等单位,并且可以通过 `-k` 参数设定一个超时的“宽限期”。 另一种是 `timelimit` 程序,功能比 `timeout` 更丰富,可以分别设置警告信号、终止信号及其时间点,为进程提供更优雅的退出过程。它需要在Debian或Arch等发行版中额外安装。 这两个工具对于那些可能长时间运行、甚至可能冻结系统的命令来说非常实用,能有效防止资源被无限占用。文章通过一个日常运维场景,清晰地展示了两种工具的用法和差异。