设置 linux 命令缓冲模式
这篇文章讲的是Linux系统中一个容易被忽略但很实用的细节:命令行工具在管道或重定向时的缓冲模式问题。作者从实际场景出发,点明了在使用管道处理实时数据时,命令默认的全缓冲行为会导致输出延迟,影响即时分析。 文章的核心方案是利用`stdbuf`命令来灵活控制标准输入输出的缓冲策略。作者不仅解释了`-oL`(行缓冲)、`-iL`、`-e0`(无缓冲)等参数的具体含义,还通过`stdbuf -oL tcpdump | grep`这个实例,展示了如何为本身不提供缓冲设置的命令“强行”加上行缓冲,从而实现实时输出。 这个工具的价值在于其通用性,无论目标命令是否支持缓冲参数,都能通过它来调整,解决了数据处理流水线中的阻塞等待问题,让调试和监控更即时高效。
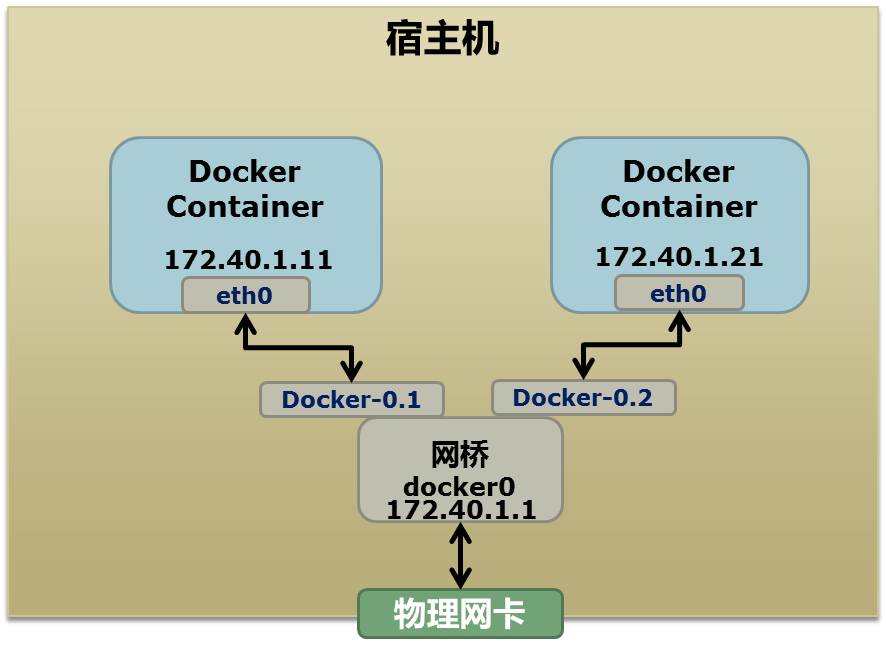
Docker在Mac下挂在/Users之外的目录
这篇讲的是在 Mac 上使用 Docker 时遇到的一个常见坑:明明想把项目代码目录挂载进容器,Kitematic 却提示“Invalid directory. Volume directories must be under your Users directory”,死活不让选 `/Users` 之外的路径。 问题的根源在于,早期 Docker for Mac 的底层是通过 VirtualBox 虚拟机来运行的。出于安全考虑,虚拟机默认只和宿主机共享 `/Users` 这一个目录,所以所有挂载操作都被限制在了这个范围内。 文章作者分享了突破这个限制的完整解决方案。核心思路是手动给 Docker 虚拟机“开通权限”:首先在 VirtualBox 的设置里,添加一个新的共享文件夹,指向你想要挂载的宿主机目录。然后,通过 SSH 进入虚拟机,修改启动脚本 `bootlocal.sh`,让这个新目录在每次虚拟机启动时都能自动挂载成功。需要注意的是,Kitematic 本身还是禁止添加这些目录的,所以必须使用 `docker run` 命令行来创建容器才能顺利挂载。 文章提供了从修改设置到执行命令的每一步操作,并附上了具体的命令示例和 StackOverflow 上的参考链接,对于需要在 Mac 上管理非默认目录下 Docker 数据的开发者来说,这是一份直接可用的踩坑指南。
shell实现ssh自动登录
作者因为在Mac下没找到顺手的SSH客户端,干脆自己用expect写了一套自动登录方案。这篇分享的核心是一个名为`ssh_auto_login`的expect脚本,它能自动处理SSH连接中的密码验证,甚至支持通过通道机(跳板机)进行动态密码认证和内网服务器跳转,省去了手动输入的繁琐。 配合一个更上层的shell启动器脚本,作者实现了通过简单命令(如`./launcher 49`)快速连接不同服务器(如联通、电信线路或特定IP)的功能。整个方案无需复杂配置,特别适合需要频繁通过跳板机访问内网服务器的运维或开发场景。虽然脚本中的服务器IP和通道机逻辑是为特定环境编写的,但其处理SSH交互、动态密码匹配的核心思路清晰,稍作修改就能适配其他服务器。作者用这个实用小工具,演示了Shell脚本在自动化运维中解决具体痛点的灵活价值。
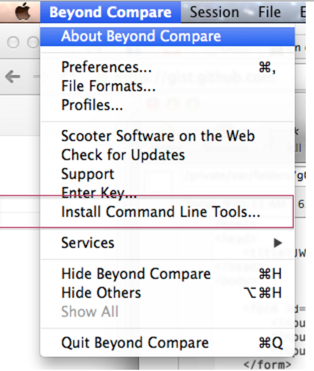
git diff(merge) with beyond compare
这篇讲的是如何在Mac上将Beyond Compare配置为git的差异对比和合并工具。作者从实际需求出发,指出了一个常见问题:macOS版本的Beyond Compare默认并未安装命令行工具,这使得它无法直接被git调用。文章详细说明了通过特定方式安装命令行的过程,并解释了生成的 `bcomp`(等待操作完成)和 `bcompare`(立即返回)两个命令的区别。 核心内容聚焦于git difftool的配置。作者梳理了git支持的各类图形化diff工具列表,并分析了其中 `bc`(即Beyond Compare)与 `bc3` 的关系,指出git虽内置这些工具的配置,但需在图形环境下才能正常工作。文章通过实例,如 `git difftool -t vimdiff` 的指定方式,以及使用 `-x` 选项自定义命令的技巧,展示了配置的灵活性。最终,读者可以借助这些步骤,将强大的Beyond Compare无缝集成到自己的git工作流中。
Docker基础技术:Linux CGroup
这篇讲的是Docker背后的核心资源隔离技术——Linux CGroup。作者从Namespace只解决“环境隔离”但无法限制“资源使用”这一痛点切入,引出了CGroup的必要性。 CGroup(控制组)是Linux内核的功能,最初由Google工程师在2006年发起,旨在为进程组分配和隔离CPU、内存、磁盘I/O等计算资源。文章清晰地归纳了它的四大核心能力:资源限制、优先级控制、审计统计以及进程挂起/恢复。这些能力让系统管理员能像为虚拟机分配资源一样,精细地管控容器或一组进程。 文中通过一个生动的实例展示了CGroup的威力:一个耗尽CPU的“死循环”程序,在被加入一个CPU份额设为20%的CGroup后,其CPU占用立刻降至约20%。这种通过操作 `/sys/fs/cgroup` 下的文件(如 `cpu.cfs_quota_us` 和 `tasks`)来即时调控资源的方式,直观地体现了CGroup作为一种基于文件系统的接口的设计思路。对于想理解Docker如何实现资源限制的读者,这篇文章提供了扎实的原理和可动手实践的细节。
Docker基础技术:Linux Namespace(下)
这篇讲的是Docker底层Linux Namespace的后半部分,作者从上一篇的铺垫出发,聚焦在User Namespace和Network Namespace这两个关键能力上。对于User Namespace,文章不仅解释了容器内用户身份被重映射(默认为65534)的原理,还深入到了`/proc/
Docker基础技术:Linux Namespace(上)
这篇讲的是Docker“新瓶装旧酒”背后的关键内核技术——Linux Namespace。作者从Docker并非全新技术切入,指出其核心是巧妙运用了已有的Linux内核能力,旨在带读者“山寨”一个简易Docker。 文章重点解析了Namespace提供的六种隔离机制,包括UTS(主机名)、IPC(进程间通信)、PID(进程ID)等。作者并未停留在概念罗列,而是通过一组清晰的C语言代码示例,一步步演示了如何使用`clone()`系统调用配合不同的`CLONE_NEW*`参数,来实现具体的隔离效果。例如,子进程在独立的UTS命名空间中修改hostname,不会影响宿主机;在独立的PID空间里,其初始进程会成为PID 1。 这种“上代码、看结果”的讲解方式,将抽象的“环境隔离”概念变得直观可感。对于想理解容器技术(不仅仅是Docker)底层原理的开发者而言,文章提供了从理论到动手验证的完整路径,是理解Linux容器化技术基石的实用入门。
Linux文件系统基础之inode和dentry
这篇讲的是Linux文件系统中两个最核心的元数据结构——inode和dentry,以及它们如何协同工作来构建我们熟悉的文件目录。 作者从虚拟文件系统VFS的抽象层入手,解释了为什么需要这些结构来统一管理底层不同的实体文件系统(如ext4)。文章指出,inode是内核中文件对象的唯一标识,它存储了权限、属组、数据块位置等所有静态元数据,但刻意不包含文件名。而文件名与inode的映射关系,则由目录项dentry在内存中动态建立和维护。 通过阅读文件路径时内核的解析过程,文章清晰地展示了dentry如何通过内存中的树状结构,高效地缓存和还原出文件系统的目录层次。这种设计将稳定的磁盘结构与灵活的内存缓存分离,是Linux文件系统高性能的关键。 理解了inode和dentry,文章最后点明,文件链接的奥秘也迎刃而解:软链接拥有独立的inode和内容,而硬链接仅仅是为同一个inode在目录项中新增了一条名字映射,并通过引用计数管理生命周期。整篇文章从底层原理出发,把看似复杂的文件系统机制拆解得条理分明。
securecrt linux与windows 互传文件
这篇讲的是如何用SecureCRT自带的sz/rz命令,来替代传统FTP/SFTP工具进行Windows与Linux间的文件互传。作者开篇就点出了常见方案的痛点:FTP/SFTP工具操作繁琐,尤其在目录层级较深时体验不佳。 文章的核心是介绍sz(下载)和rz(上传)这对命令。通过具体配置和代码示例,它展示了如何先在SecureCRT中设置默认的传输目录,然后直接使用`sz 文件名`将Linux文件下载到指定本地路径,或使用`rz`弹出窗口选择本地文件上传到Linux当前目录。整个过程不需要启动额外客户端,直接在终端里就能完成。 不过,文章也坦诚地指出了局限:sz/rz对于小文件传输非常便捷,但传输大文件时速度会比较慢。因此,这个方案特别适合那些需要频繁、快速交换中小型文件的运维或开发场景,能显著提升工作效率。
建立私有的 yum 源站
在企业内部运维中,管理统一的软件包源是个常见需求。这篇讲的是如何从零搭建一个私有 yum 源站,非常适合需要集中管控软件分发的团队。作者从最基础的三要素讲起:准备好要发布的 rpm 包、使用 `createrepo` 工具建立索引,最后通过 webserver(或本地/FTP)提供服务。 文章直接给出了可操作的步骤。从安装 `createrepo` 工具开始,到创建分层目录、复制 rpm 包,再到执行 `createrepo` 命令生成索引,每一步都有明确的命令示例。特别提醒了关键细节:每次新增 rpm 包后,都需要重新执行索引生成命令,否则客户端可能无法感知更新。 整个过程聚焦于 yum 源的核心构建逻辑,将 webserver 的具体配置留给读者自行扩展。对于想要快速搭建内部源、减少对外部网络依赖的运维人员,这套方法提供了一个轻量且清晰的起点。
多 SSH Key 管理技巧与 Git 多账户登录问题
这篇技术文章从开发者日常需要频繁登录多台远程服务器的场景出发,介绍了一种高效的管理方式。作者指出,虽然直接使用 `ssh` 命令配合端口号、别名等方式能工作,但当服务器数量增多时,命令会变得冗长且难以维护。 文章的核心解决方案是熟练运用 `~/.ssh/config` 配置文件。通过为不同主机(如工作服务器、个人代理、学校数据库)设置简洁的 `Host` 别名,并预先配置好对应的 `HostName`、`User`、`Port` 甚至 `IdentityFile`(指定不同的SSH密钥)和 `LocalForward`(端口转发)规则,可以将复杂的登录逻辑固化下来。此后,只需输入一个简单的别名即可建立连接。 作者通过多个配置实例,清晰地展示了如何将一条可能包含多重参数的复杂命令,转化为结构清晰、易于管理的配置项。这种方式不仅极大提升了日常登录的效率,也使得对不同环境、不同密钥的切换与管理变得一目了然。对于需要同时处理多个项目和远程环境的开发者而言,掌握这项技巧能有效减少心智负担。
初入运维的小伙伴,别再问需不需要学Python了
这篇讲的是运维人员该不该学Python的老话题。作者从百度知道上一个常见的提问切入,观点很明确:掌握一门开发语言,尤其是Python,已经是高级运维工程师的必备技能。 文章认为,不会开发,就难以深入理解业务流程、优化性能,也无法在复杂场景(如数千台服务器)中实现真正的自动化运维,只能依赖通用工具或拼凑开源软件。而Python恰好能胜任,它既是强大的脚本语言,满足绝大部分自动化需求,又能用于开发后端的C/S架构和Web界面,让运维人员有能力构建自己的运维平台,从而体现核心价值。 作者也对比了其他语言。比如,PHP更专注于Web;Java显得臃肿;C++在运维场景中多数时候“是为了来装B的”;而Go语言虽新,但预计不会成为运维开发的主流。同时,针对“Python效率低”的说法,作者指出程序效率更取决于开发者本身,并以Tornado框架在Python下实现高并发作为例证,强调语言本身的影响只占一部分。 文章的核心结论是:别再纠结“需不需要学”,Python因其简洁、全面和生态优势,就是运维转向开发、提升竞争力的首选工具。
如何通过 Yum 安装 Pure-ftpd
这篇教程从配置Yum源讲起,演示了在CentOS系统上快速部署Pure-ftpd FTP服务器的完整流程。核心方案是通过阿里云的EPEL源来获取软件包,从而解决官方源可能缺失的问题。 教程的关键操作包括修改pure-ftpd.conf配置文件,例如启用日志、设置虚拟用户数据库路径、关闭匿名登录,以及配置被动模式下的端口范围(48000-50000)。作者还详细说明了如何创建系统用户与虚拟用户,并设置相应的目录权限。 为了确保服务可被外部访问,文中补充了防火墙规则的配置,放行了控制端口21和被动模式端口。最后,通过chkconfig和init.d脚本实现服务的持久化与启动。整套流程完整且实用,适合需要快速搭建FTP服务的运维人员直接参照。
如何设计软件模块的自动化测试?
这篇指南聚焦于如何为软件模块设计自动化测试,作者从模块的交互模式出发,将测试对象清晰地划分为两大类:消息触发型和主动扫描型。 对于“守株待兔”的消息触发型模块,核心在于开发一个能模拟外部消息的测试程序,让它发送请求并等待响应,从而验证模块处理逻辑的正确性。而对于“主动出击”的主动扫描型模块,测试思路则是通过测试程序向其数据源(如数据库)注入测试数据,然后监听并验证它后续发出的消息或动作。 文章不仅给出了对应的自动化测试框架图和详细的消息流程,还分享了宝贵的实战经验。比如,务必首先确保测试程序的消息接口协议和链路配置无误;测试初期宜用少量数据跑通流程,再逐步放量;为耗时较长的测试用例设置超时机制,避免无限等待;以及规范测试报告的存储与格式,方便结果集成与展示。 自动化测试的终极目标是让机器承担重复的验证工作,在版本迭代中快速捕获回归缺陷。这篇内容为开发者设计针对不同交互模式模块的测试方案,提供了非常具体和可落地的参考框架。
腾讯资深运维专家周小军:QQ与微信架构的惊天秘密
这篇来自腾讯资深运维专家周小军的深度访谈,从一位“运维老兵”的视角,揭开了支撑QQ与微信海量社交数据背后那套复杂而精巧的存储与运维体系。 访谈的核心亮点在于对微信与QQ核心存储架构差异的剖析。周小军详解了二者背后的NoSQL系统:微信消息业务依赖强调强一致性的Quorum_KV,它面向写多读少场景,通过Quorum协议保证数据可靠;而QQ的Grocery则采用最终一致性模型,优化读写均衡性能。这种“量体裁衣”的设计思想,正是应对不同社交产品数据特性的关键。此外,文章还清晰梳理了腾讯如何通过“全网调度”、SET标准化单元部署、以及华南/华中/华北三地同步等机制,构建起应对单机房故障的高可用容灾体系。 除了硬核架构,周小军也毫无保留地分享了个人从天涯到腾讯的十余年运维心路,强调了运维的终极目标是提供“超出预期的服务能力”,并坚持通过“一万小时定律”与持续突破舒适区来锻造专业度。
使用whiptail在shell脚本中创建交互式对话框?
这篇文章介绍了一个让Shell脚本“活”起来的实用工具——whiptail。它能帮助你在纯终端环境下,快速创建出直观的用户交互界面,就像许多Linux软件安装过程中弹出的对话框一样。 作者详细演示了whiptail的多种对话框类型,包括最基础的消息确认框(msgbox)、提供是/否选项的决策框(yesno),以及能接收用户文本输入的表单框(inputbox)。对于需要处理敏感信息的场景,还专门讲解了密码输入框的实现方法。 更进一步,文章展示了如何用whiptail构建复杂的选择逻辑:创建单选菜单(menu)、单选列表(radiolist)供用户选择一项,以及多选清单(checklist)让用户勾选多个偏好。最后,它甚至支持在脚本中显示一个实时进度条(gauge),让长时间的任务反馈更友好。 whiptail是一个预先安装在大多数Linux发行版中的工具,这意味着你可以直接在脚本中调用它,无需额外安装。掌握它,就能轻松将你的脚本从简单的命令行工具,升级为具备良好用户体验的交互式程序。
IaaS、PaaS、SaaS 之间的区别
这篇讲的是云计算里三个最核心的层级模型:IaaS、PaaS和SaaS到底有什么不同。作者从“云”这个概念入手,先说明云计算本质上是分层的:最底层的IaaS(基础设施即服务)直接提供了虚拟化的服务器、存储和网络硬件,企业可以像租水电一样租用这些资源,省去了自建机房的麻烦,适合需要灵活控制底层环境的技术团队。 往上一层是PaaS(平台即服务),它提供了完整的开发和部署环境。开发者不用再操心操作系统、数据库这些基础软件的安装维护,可以专注于应用本身的编写与协作,像Heroku、Google App Engine都是这类服务的代表。 而最上层的SaaS(软件即服务)则与我们日常使用最贴近,所有功能都通过浏览器交付,比如我们常用的Google Docs、Dropbox或是Salesforce的CRM系统,用户开箱即用,无需关心底层任何技术细节。 文章最后也指出,随着技术演进,像容器技术催生的CaaS等新模式不断出现,这些名词的界限其实在商业化的概念普及中变得模糊了。真正的理解,还是在于它们各自解决了用户哪一层的问题。
nc 传送文件
这篇讲的是如何用nc(netcat)这个网络工具直接传输文件,省去了传统方法中压缩、解压或配置权限的麻烦。作者从一个非常实用的角度切入,直接给出了传送整个文件夹和单个文件的具体命令行操作。 文章核心在于展示nc配合管道和tar命令的简洁性。传送文件夹时,发送端通过tar打包压缩后管道给nc,接收端则监听端口并用tar解压还原,整个过程一步到位。对于单个文件,方法更为直接,用cat或重定向即可完成内容流式传输。这种用法尤其适合内网环境下快速交换配置文件或日志。 作者没有展开复杂原理,而是聚焦于命令的实际写法和效果。通过这两组清晰的命令示例,读者能立刻上手操作,体会到这种轻量级方案在运维和开发场景中的便利性。
2015年版阿里云ECS服务器使用总结(与aws比较)
这篇讲的是国内云服务商阿里云和亚马逊AWS在服务器产品上的直接较量。作者从价格、稳定性、速度等多个维度进行了详细对比。 价格上,阿里云包月实例比AWS同配置便宜约40%,但AWS的预留实例方案可将价格拉平。稳定性方面,AWS整体表现更可靠,而阿里云则以超快的工单响应和给力的客服支持取胜。 速度测试是文章的重点。通过实测发现,阿里云1Mbps带宽下载速度约42-60KBs,但属于共享带宽,并发能力弱;AWS带宽上限更高,下载速度可达900KBs且不受影响。连接时间上,阿里云杭州节点(约280ms)明显优于北京节点(约2000ms),甚至快于AWS东京节点(约140ms)。 在服务与备案等本土化体验上,阿里云具有明显优势。文章最后给出了务实的选择建议:对于需要全栈云服务的国内创业团队,阿里云已能满足基本需求;而追求更成熟技术架构的团队,可继续关注AWS中国区的发展。
linux下redis执行bgsave时,报overcommit_memory错误问题
这篇讲的是 Redis 在内存紧张时执行 bgsave 可能遭遇的 overcommit_memory 报错问题。作者从实际故障现象切入,详细说明了错误提示的含义:当系统内存耗尽,fork 子进程进行后台保存时,若恰有数据变更需要申请内存,就可能因分配失败而终止保存。根本原因在于 Linux 内核的内存分配策略参数 `vm.overcommit_memory` 默认为 0,较为保守。 文章进一步剖析了这个内核参数的三个取值含义,并明确给出解决方案:将该参数设置为 1,允许内存适度超量分配。具体操作提供了三种方法:修改 sysctl.conf 文件、直接运行 sysctl 命令或写入 proc 文件系统,并附上了验证命令。 此外,文章还延伸讨论了与内存管理密切相关的 OOM Killer 机制,解释了 Linux 如何选择进程终止来释放内存,并介绍了如何通过 /proc/meminfo 查看 CommitLimit 和 Committed_As 等关键内存指标。整篇文章逻辑清晰,从问题到原理再到解决和扩展,为处理此类内存配置问题提供了完整思路。