ubuntu设置开机后台自动运行
这篇讲的是在Ubuntu系统中设置脚本开机自动后台运行时遇到的典型路径问题。作者从创建一个简单的Shell脚本开始,通过编辑`/etc/rc.local`文件实现开机自启,但重启后却发现日志提示“sslocal:command not found”。 问题根源在于,虽然`sslocal`命令实际存在于`/usr/local/bin/`下,但`rc.local`执行环境的PATH变量并未包含该目录,导致系统无法定位到命令。作者的解决思路很直接:将需要调用的命令文件从`/usr/local/bin/`直接移动到系统标准路径`/bin`下,从而让任何执行环境都能找到它。 这个案例清晰展示了Linux后台任务管理中容易忽略的环境差异问题。对于需要自动化运行的脚本,确保依赖的命令位于系统标准路径,或在脚本中明确指定其绝对路径,是避免此类“命令未找到”错误的关键。
git术语解释staging,index,cache
这篇讲的是Git里三个让人头疼的术语:staging、index和cache。作者从自己的困惑出发——为什么《Pro Git》里叫staging area,`git-reset`的文档里叫index,而`git-rm`的参数却是`-cached`?这三个词到底是不是一回事? 文章追溯了问题的根源,发现这其实是Linus Torvalds当年的“一念之差”。在开发Git初期,为了管理Linux内核的补丁,他设计了一个“目录缓存”来保存完整的目录树快照。这个缓存的内容结构,在源码里被存储在一个叫`index`的文件中。因此,在Git的底层实现(源码)里,操作这个缓冲区的变量都带着“cache”前缀;而“index”这个名字则因为它作为文件直观地出现在了`.git`目录里。 随着时间推移,普通用户更多通过文档而非源码接触Git,“index”成为了更通用的称呼。而“cache”一词则逐渐退居幕后,仅在讨论内部实现时使用,其过去分词“cached”则作为一个形容词保留下来,用于描述“已通过`git add`放入暂存区”的状态。通过引用git核心维护者Junio C Hamano的解释,文章理清了这三个术语的历史脉络和细微差别,帮你理解为什么同一个东西会有这么多名字。
使用Smem精确显示Linux下内存使用情况
Linux系统管理员常被“内存到底被谁吃了”这个问题困扰,尤其是当应用内存占用高但系统监控工具显示不清晰时。这篇文章介绍了一个利器——Smem。 Smem能提供比传统工具更精确的内存视图,它直接读取内核的内存映射,输出包括USS(进程独占内存)、PSS(按比例分摊的内存)和RSS等关键指标,让你一眼看清每个进程的真实“食量”。文中通过实际命令演示了它的多种用法:默认列出所有进程、用`-w`查看整体内存分布、或用`-up`按用户汇总内存占比。 文章还贴心地用图表和文字解释了VSS、RSS、PSS、USS的区别,点明了数值一般满足 VSS ≥ RSS ≥ PSS ≥ USS 的规律,帮你理解这些指标的实际意义。无论你是想排查内存泄漏,还是做容量规划,Smem都能提供更可靠的数据支撑。
SVN为什么比git更好
这篇文章的作者个人偏爱Git,但他从团队实际出发,提出了一个反向思考:在什么情况下,SVN可能是比Git更“好”的选择? 作者以一家拥有约20名程序员、使用多种语言的创业公司为背景,坦率地分析了SVN的优势。它拥有广泛的群众基础,几乎所有人都能快速上手;跨平台支持优异,尤其以Windows下的TortoiseSVN著称;核心优点是简单易用,甚至能被误用作“云端文件夹”也未引发大问题;经过十五年打磨,其功能完善且流程稳定,非常适合传统的公司制研发团队管理。 相对地,作者指出Git的主要短板在于高昂的学习成本(尤其对新人和非核心技术人员),对Windows平台支持不佳,其分布式概念和存储原理构成了一定的抽象门槛,并且过高的自由度容易因误操作给团队带来混乱。 结论是,对于研发规模中等偏上、人员背景多样的创业公司而言,如果团队协作并不涉及高频次的跨地域开源协作,SVN在降低团队协作摩擦和上手成本方面,可能是一个更务实、更稳妥的选择。
git 查看文件修改记录
这篇讲的是,当接手了几年前的历史代码,想追查某行逻辑的修改记录时,`git log` 可能不够用。作者分享了自己从 `git log -p` 到熟练使用 `git blame`,最终定位到“问题代码”最初引入版本的全过程。 文章指出,单纯用 `git log` 只能看提交摘要。加上 `-p` 参数才能看到具体修改内容,但这对于长期演进的文件依然不够精准。真正的利器是 `git blame`,它能标注每一行最后的提交。通过 `-L n,m` 参数,可以只查看特定行范围的修改历史。 更关键的是,文章演示了一套“链式追溯”技巧:用 `git blame` 找到某行的最近一次修改提交,再进入该提交查看对应行号,然后以此提交号和行号为新起点,再次执行 `git blame`,如此循环往复,便能沿着代码的修改路径,一路回溯到最初被引入的那个提交。作者建议配合 Source Tree 等图形化工具查看具体的代码 Diff,让这个追溯过程更直观。
Windows硬链接 软链接 符号链接 快捷方式
这篇技术文章梳理了Windows系统中容易被混淆的四种“链接”机制:快捷方式(.lnk文件)、硬链接、目录连接点(Junction Point)和符号链接。 作者从每种机制的实现原理、适用对象和实际行为切入,给出了清晰的对比。例如,快捷方式是通用的应用层文件,而硬链接是NTFS内置机制且仅能用于同一卷内的文件;目录连接点(常被误称为“软链接”)专用于目录且不能跨主机,而符号链接则最为灵活,能跨盘符、跨主机,同时适用于文件和目录。 文章特别强调了术语规范的重要性,批评了国内不少相关文章概念混淆的问题。通过列举创建、查看、删除各链接类型的具体命令行工具(如mklink、fsutil、junction.exe)及注意事项,本文提供了一份实用的技术速查手册,帮助开发者在文件管理、系统迁移或程序兼容等场景中做出正确选择。
linux 之 mv
这篇文章从一个真实场景切入:同事在使用 `mv` 命令将一个充满小文件的目录移动到另一个磁盘时,发现目标空间在增长,但源空间却迟迟没有释放。作者通过 `lsof` 发现,这是因为文件在移动过程中并未被立即删除,而是全部移完才清理。 那么,关键问题来了:如果移动如此大量的文件过程中发生了中断,已移走的文件会被删除吗?作者猜测可能是“删已移的,留未移的”,但这仅仅是猜测。 真正的答案藏在 `mv` 命令的源码里。作者查看了其核心实现,发现逻辑异常简洁:它只是简单地逐个复制文件,待全部成功后才执行删除操作。源码中并未对“中断”这种意外情况做任何特殊处理。这意味着,一旦中途出错或中断,结果将是:**复制完成了多少就算多少,但不会删除源目录中的任何文件**。 这个结论揭示了 `mv` 在处理大规模文件迁移时的一个重要风险点——它并非原子操作,且中断后状态不确定。对于需要进行此类操作的管理员来说,理解这一底层行为至关重要,它提醒我们务必使用更可靠的工具或脚本(如结合 `rsync` 与检查点)来处理关键数据迁移。
fabric执行在后台运行的命令
这篇讲的是在使用Fabric执行远程命令时,后台进程可能无法正常运行的坑点及解决方案。作者在用Fabric的run()执行nohup命令启动压力测试时,发现命令并未在后台成功运行。文章分析了这背后涉及Fabric对shell交互模式的处理机制,并指出直接使用“&”符并非可靠做法。 为解决此问题,文章推荐了三种更鲁棒的替代方案:优先使用systemd等系统守护进程管理工具,或借助screen/tmux实现进程detach,最后才是尝试nohup(但成功率不稳定)。作者特别指出使用screen时需设置pty=False以避免问题。 文中还附上了一个管理JMeter压力测试的fabfile完整示例,展示了如何实际应用screen命令来部署和启动测试。对于常与自动化部署工具打交道的读者来说,这篇结合踩坑经验与具体代码演示的分享,能提供切实的参考。
一些LVS实验配置、工具和方案
这篇讲的是作者在LVS环境下验证的一种不中断业务的RealServer升级方案。核心目标是在不中断前端服务的情况下,对后端真实服务器进行维护或重启。 作者选用了LVS的DR(直接路由)模式进行实验。文章详细列出了网络规划,包括两台RealServer和一台Director Server的IP分配。关键在于具体的配置实践:在Director上,通过ipvsadm工具设置VIP和采用加权轮询调度算法;在RealServer上,则通过脚本在本地绑定VIP并设置ARP抑制,这是DR模式正常工作的基础。 作者验证的流程是:通过脚本控制,让需要升级的RealServer自动从LVS集群中移除,待维护完成并检查健康后,再自动重新加入集群。整个过程对客户端保持透明,实现了业务不中断。文章提供了可用的脚本片段,将配置步骤代码化,方便读者参考和复现。对于需要在生产环境中安全维护LVS节点的运维人员来说,这个实验记录提供了一套切实可行的操作思路和工具参考。
浅谈运维工具体系
运维体系庞大且复杂,这篇梳理的是支撑高效运维背后的工具全景图。作者从运维的三大核心场景——流程管理、发布变更与监控告警——出发,系统性地拆解了每个环节所需的工具类别与作用。 文章指出,运维工具并非铁板一块。在流程层面,工具负责衔接与审批,确保变更闭环与故障可追溯;在发布变更层面,从版本管理、配置下发到资源隔离,形成了一套从代码到线上状态的完整管控链路,尤其强调了以版本管理为起点、杜绝直接拷贝的规范做法。而在监控告警层面,则构建了从数据采集、异常检测到自动修复、通知的完整流水线,提到了 Logstash、StatsD 等具体技术选型,并区分了本地与远程拨测的不同价值。 整体来看,文章并未空谈理论,而是将各类工具按功能归类,并点明其解决的具体问题,比如配置漂移、故障定位、资源利用率等。它为读者勾勒出一个从操作界面到底层资源、从流程规范到技术实现的立体工具体系,适合正在搭建或优化自身运维体系的团队参考。
Zend Studio集成Git使用
这篇文章提供了一份在Zend Studio中集成和使用Git的详细操作指南。对于许多初次接触Git的开发者来说,其“本地库”与“远程库”分离的工作流以及分支概念往往令人困惑。文章正是从解决这个实际痛点出发,用清晰的步骤拆解了整个过程。 作者首先演示了如何在服务器端建立裸仓库,随后重点落在IDE中的具体操作:从初始化本地Git仓库、提交代码,到配置远程仓库并完成推送与拉取。文章特别指出了一个新手常踩的“坑”:当执行“Pull from Upstream”后,工具并不会自动合并远程更新,需要开发者手动执行“Merge”操作,这个细节描述得很到位。 在分支管理部分,文章不仅介绍了创建、切换和合并分支的命令与IDE操作,还贴心地提醒了切换分支时文件会暂时“消失”的正常现象,避免开发者惊慌。整体而言,这是一份从服务器配置到日常开发(如同步代码、管理分支)的全流程实用指南,适合那些希望在熟悉的IDE环境中快速上手Git的开发者。
详解Linux bash中的变量
这篇详细拆解了Linux bash中的五种核心变量类型:本地变量、局部变量、环境变量、位置变量和特殊变量。作者从实际的运维与脚本编写场景出发,不仅区分了每种变量作用域的差异——例如本地变量作用于整个bash进程,而局部变量(通过local定义)仅限于当前代码段——还深入讲解了它们具体的用法与约束。 文章特别强调了环境变量如何通过`export`传递给子进程,以及位置变量($1, $2...)和`shift`命令在参数处理中的配合使用。对于日常脚本编写至关重要的特殊变量,如`$?`(上一条命令的返回值)、`$#`(参数个数)和`$*`与`$@`的区别,也都有清晰的示例说明。这些细节对比,能帮助你准确选择和使用不同变量,避免脚本中出现作用域混淆或参数传递错误的问题。
一个开发眼中的运维
这篇讲的是前新浪SAE运维主管郑志勇如何用开发思维重塑运维认知。作者从开发转型运维的亲身经历出发,提出了一个关键视角:运维与开发本质相通,核心都是管理资源。 文章首先厘清了运维的定位——不是打杂或服务开发,而是对业务稳定负责,保障系统架构合理。作者将程序设计的抽象、分层思想引入运维,提出“一切运维对象都抽象为资源”,这样就能用统一的方法进行配置和监控。他详细拆解了运维的资源观:不仅是硬件,还包括文件描述符、端口、数据库连接等一切可管理对象。 文章最实用的部分在于总结的运维原则。比如线上变更必须通过配置管理,任何手工操作都是对团队改进机会的浪费;系统上线前必须回答如何保障HA、扩展和监控。作者还强调配置管理的三大核心要素——包、文件和进程,认为只要控制这三者就能掌控整个系统。最后提出的“不犯第三次错误”和“运维越清闲,系统越稳定”等观点,直指运维工作的长期主义思维。 这些从实战中提炼的抽象方法论,尤其适合正在寻求体系化提升的运维人员,或希望与运维更好协作的开发者。
Linux发展编年表
这篇讲的是Linux如何从芬兰学生Linus的个人项目,一步步成长为驱动当今世界的关键力量。作者用一条清晰的时间线,梳理了这个“24年计算机革命”中的关键节点。 摘要里,你可以看到Linux内核的第一个版本如何诞生,以及为何Linus认为将它切换到GPL协议是“做过的最正确的事”。文章也记录了早期关于微内核与宏内核的著名论战,以及第一个成功发行版Slackware和Debian的出现。从Red Hat开始商业化,到Google搜索引擎基于Linux构建,再到2007年Android的发布,文章勾勒出Linux如何从服务器走向桌面、手机和云端。 这些里程碑事件不仅是技术演进,更是一段开源社区与商业力量交织的成长史。文章最后停在2013年Valve推出基于Linux的SteamOS,记录了Linux在游戏领域的新尝试。整篇文章像是为开源爱好者准备的一份详尽档案,让读者能直观感受一个理想如何改变世界的技术底座。
云计算时代:运维人员会踩到哪些坑?
这篇整理自ChinaUnix论坛热议的文章,汇集了多位一线运维人员的实战经验,直面云计算时代运维岗位的核心挑战。讨论焦点并非空谈理论,而是紧扣具体痛点:当服务器从百台暴增至万级,自动化运维如何落地?虚拟化资源池化后,故障定位为何反而更难?文中网友分享了Zabbix、Nagios、Cacti等开源监控工具的部署心得,也直言云磁盘I/O变慢往往是资源争抢或自身程序问题所致,解决方法需“对症下药”。 更关键的是职业转型的讨论。有网友犀利指出,跟不上自动化运维趋势的“手工作坊式”运维将面临淘汰;也有人强调,云平台运维本身创造了更高价值的新岗位,技能要求水涨船高。关于混合云服务商的选择,讨论也具体到阿里云、腾讯云乃至自建平台的性价比权衡。整场对话没有简单结论,而是呈现了云时代运维复杂性的真实切面——技术工具更迭、故障排查逻辑变化与个人技能升级,这三者构成了运维人员必须同时应对的挑战。
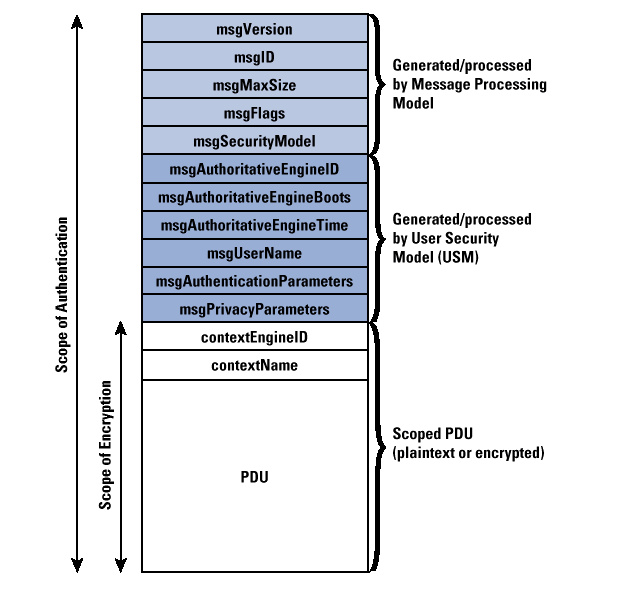
SNMP概述–运维必知的协议基础
这篇讲的是运维人员必须掌握的基础协议——SNMP。文章从“为什么需要远程网络管理”这个现实痛点出发,解释了SNMP如何让一个工作站就能监控成千上万设备。它详细拆解了SNMP的核心架构,包括被管设备、Agent代理和管理站这三个组件是如何通过UDP通信的,并梳理了GET、SET、TRAP等基本操作。 作者重点对比了SNMP的三个版本,指出早期版本因安全性薄弱已逐渐被弃用,而SNMPv3通过引入USM安全模式、身份验证(如MD5/SHA)和加密(如AES)等机制,实现了对消息篡改、伪装和窃听的防护,是当前的主流选择。文章最后还提供了在Linux系统上安装、配置并使用net-snmp服务的具体步骤,让理论落地。 总的来说,这是一篇从概念、原理到实战操作的完整入门指南,帮助运维人员快速建立对这个“简单”却无处不在的协议的系统认识。
Mac下使用SecureCRT的一些记录
这篇记录讲的是作者在Mac上使用SecureCRT终端连接软件时,亲身经历并解决的两个典型“坑”,以及积累的快捷键心得。 核心问题之一在于“密码总是存不住”。作者发现,这是SecureCRT在Mac上默认启用了系统“钥匙串访问”来管理密码所导致的。解决方法很具体:进入软件全局选项的Advanced设置页,取消勾选Use Keychain,即可让SecureCRT使用自带的密码保存功能。 另一个更隐蔽的问题是“CTRL+C发不出中断指令”。作者排除了键盘故障,尝试了各种设置均无效,最终意外发现根源在于输入法:必须将输入法切换至系统自带的“美式英文”,才能正常发送中断信号,即使切换至第三方输入法的英文模式也不行。 此外,文章还整理了一份Mac版SecureCRT与Windows版在快捷键上的差异列表,比如使用Command+L快速新开标签页连接,Command+K新建会话等。这些基于实践的小结,对于经常在Mac上进行远程连接的开发者来说,或许能省去不少摸索的时间。
ssh 免密码登录
这篇讲的是如何通过三个关键命令快速配置SSH免密码登录,免去每次连接都输密码的麻烦。作者从实际操作出发,清晰拆解了`ssh-keygen`生成密钥对、`ssh-add`管理密钥、`ssh-copy-id`分发公钥这三个核心步骤。 文章特别指出了一个容易踩坑的细节:`ssh-copy-id`这个方便的工具其实属于`openssh-clients`包,而不是`openssh`包本身。作者通过直接列出两个软件包的文件清单,让读者一眼就能看清这个差异。 掌握这套方法后,无论是日常运维还是脚本自动化,都能更顺畅地连接远程服务器。理解包之间的区别,则有助于在不同Linux发行版上准确找到和安装所需工具。
Nagios+OMSA监控dell设备硬件
这篇讲的是,如何用 Nagios 和 Dell OMSA (OpenManage Server Administrator) 配合,实现对 Dell 服务器硬件状态的实时监控。 文章的出发点很明确:虽然 Nagios 等监控工具很流行,但它们默认更侧重于服务与应用层的监测。对于服务器本身的硬件健康状况,比如 CPU 温度、风扇转速、存储阵列状态、机箱入侵检测等,则需要额外的解决方案。作者详细演示了整套部署流程。 核心方案分为两部分。在 Nagios 服务端,关键是下载并配置 `check_openmanage` 插件。文章提供了具体的命令定义示例,比如如何检测 CPU、存储、温度等,并且解释了插件的各类 `--only` 参数,让读者可以根据需要定制监控项。 在被监控的 Dell 物理服务器上,则需要安装 Dell 的 OMSA 管理套件。文章给出了在 CentOS 系统上配置 yum 源并安装 `srvadmin-all` 的完整命令。安装成功后,不仅 Nagios 可以通过插件获取硬件数据,管理员还可以通过浏览器访问服务器的 1311 端口,直接查看 OMSA 的 Web 管理界面。 整篇文章是一份非常具体的实操指南,从环境准备到每一步的配置修改都写得很清楚。对于需要管理 Dell 物理服务器运维的工程师来说,它直接给出了一个可用的监控方案。
15年运维经验老兵对公有云的深度剖析
这是一位拥有15年实战经验的运维老兵,从一线视角对公有云行业进行的全景扫描。文章并非理论堆砌,而是基于真实运营数据(如各产品的销售毛利率)和厂商观察,直指行业核心:哪些公有云服务商在“赔本赚吆喝”,哪些已接近盈利,以及CDN业务为何是“暴利”。 作者深入剖析了从盈利模型、技术架构到市场格局的方方面面。技术上,他坦率指出了OpenStack商用的现实瓶颈、分布式存储Ceph的运用门槛,以及不同负载均衡方案背后的成本与性能权衡。在行业判断上,他认为公有云创业窗口已在2013年底关闭,并明确指出了大厂与创业公司在企业市场的不同打法。 这篇文章的价值在于其务实与直白。它不描绘宏大蓝图,而是用具体的数据、技术选型中的“坑”与厂商间的真实竞争态势,为读者描绘了一幅公有云行业的实景地图。无论是技术决策者还是行业观察者,都能从中获得关于成本、架构和市场机会的冷静思考。