为什么数组标号是从0开始的?
这篇讲的是“数组下标从0开始”这个常见设计背后的历史与技术逻辑。作者从“为什么这个设计如此反人类却沿用至今”的疑问出发,追根溯源。 最初的原因可追溯到BCPL语言,C语言继承了它的指针算术逻辑:指针p+0指向首元素,p+5自然对应第六个元素。早期硬件资源极度匮乏,在IBM 7094时代,0-based索引能节省关键的编译时间,这在当时关乎程序能否跑完。有趣的是,C语言采用方括号“[]”仅因为它是键盘上最易输入的成对符号。 文章进一步分析,在现代语言中,这一设计因其实用性而被保留。Python之父Guido van Rossum明确指出,0-based与半开区间结合,能写出a[:n]这样极其优雅的切片语法,若从1开始则复杂得多。同时,在支持指针的语言中,下标作为内存偏移量,从0开始也更符合底层逻辑。 总结来说,这个设计既是早期计算资源约束下的高效选择,也因其在表达子序列时的简洁性,在现代语言中获得了新的生命力。文章通过引用C和Python之父的原始论述,将这个看似“反直觉”的习惯梳理得清晰而有说服力。
流式布局的原理和代码实现
这篇文章深入解析了流式布局的核心原理与代码实现,适合GUI开发者和前端工程师阅读。作者从最简单的布局模型出发,即控件靠左、靠右或堆叠排列,提出使用两个栈(Stack)数据结构——一个管理靠左控件的位置,另一个管理靠右控件——来高效实现流式布局。伪代码清晰展示了布局管理器的工作流程:当放置新控件时,先检查当前空间是否足够;若不够,则根据浮动方向从对应栈中弹出更高位置的控件来释放空间,确保布局不重叠。 文章重点讨论了两个实现关键:一是控件变化时的级联重布局,从子节点一直传递到根节点,这虽然简单但性能开销
软件开发的硬约束
这篇讲的是作者从超市结账小票的两种打印方式出发,对软件开发中“软约束”与“硬约束”的深刻反思。 作者观察到,收银小票倾向于为同一件商品打印多行记录(每行数量为1),而非合并成单行(数量为N),即使后者更省纸。起初他怀疑是设备性能所限,但通过一次收货管理系统的开发与实地部署,他发现了真正的原因:合并记录会影响仓库作业流程的效率与操作习惯——后续员工需要在纸质清单上手动划销,单件单行才最直观。 这个发现让他意识到,长期从事纯软件开发时,功能、架构与责任划分往往具有灵活性(“软约束”),可以按需调整。但现实世界存在大量“硬约束”,比如设备操作习惯、生产线工艺流程、物理环境限制等。他进一步以工厂生产多语言说明书为例:生产线难以像软件模块一样灵活拆分组合,导致不得不为所有市场印刷包含所有语言的通用说明书,以避免为每种语言维护独立生产线的高昂成本。 作者总结道,随着软件深入物理世界,决定其价值的往往不是复杂的技术架构,而是能否与现实约束融洽相处。开发者需要跳出纯粹的代码思维,直面问题的核心限制。文章最后以快递站利用条码替代键盘操作的巧妙案例收尾,说明了解决方案可以完全跳出技术框架,以极低成本满足场景的真实需求。
使用逻辑时钟重述paxos协议
Paxos协议以其晦涩难懂而闻名,但这篇技术博客提供了一个清新的视角:用逻辑时钟来重述它。作者认为,一旦从带时钟同步的RPC协议出发,复杂的共识流程就变得直观起来。 文章首先构建了一个基于逻辑时钟的通信框架。它引入一个全局计数器(globalClock)来产生全局递增的时间戳,规定所有网络消息必须携带时间戳,且接收方拒绝处理“过时”的请求。这个简单的同步机制,为后续的协议设计打下了确定性基础。 在此基础上,Paxos的两个阶段被清晰地映射为两类带时钟的请求。Proposer在Prepare阶段(设置时钟、广播提案号)和Accept阶段(发送具体提案)中,都遵循“时钟必须严格递增”的规则。Acceptor则依据收到的消息时间戳与本地时钟的比较,来决定是接受还是拒绝。这样一来,协议中复杂的冲突避免和提案推进,被转化为了对时钟值的比较和递增操作。 更进一步,文章指出可以摆脱中心化的全局时钟服务。每台机器的本地时钟可由一个二元组(轮次编号roundNumber, 服务器ID)构成。通过定义先比较轮次再比较ID的规则,保证了分布式环境下时间戳的全局唯一性和单调性,使得整个协议更加贴近实际部署场景。 总而言之,这种重述方式将分布式共识中抽象的“提案编号”竞争,转化为对逻辑时钟值的单调递增和比较操作,让Paxos协议的内在逻辑——即如何利用确定的全局顺序来避免冲突、达成一致——变得异常清晰。
PHP概率算法(适用于抽奖、随机广告)
这篇讲的是一个简洁高效的PHP概率算法实现,特别适合用于抽奖系统或随机广告位分配等场景。 文章的核心是一个名为 `get_rand` 的函数。它的巧妙之处在于通过逐步缩小概率范围来工作:给定一个概率数组,函数首先计算总概率值,然后从1到总值之间随机取数。如果随机数落在当前奖项的概率区间内,则返回该奖项;否则,从总值中减去该奖项的概率,并继续判断下一个。这个过程就像从一个箱子里依次摸奖,只要奖项设置好概率,算法总能准确“命中”一个结果,且时间复杂度为O(n)。 文章接着展示了如何将此算法应用到实际抽奖逻辑中。通过一个二维数组配置好各奖项及其对应的整数概率值(v值),总和越大,概率精度越高。后端通过循环提取概率值,调用算法获取中奖ID,然后将中奖结果与未中奖信息分别整理,最终以JSON格式返回给前端。整个实现清晰直接,代码量少,在数据量较大时也能保持出色的性能。
STL笔记之hashtable
这篇讲的是SGI STL中经典hashtable容器的源码实现。作者从自己动手实现一个简单hashtable的经历切入,发现与STL源码的思路惊人相似,由此展开对底层机制的剖析。 文章深入讲解了SGI版本hashtable的核心设计:它采用开链法解决冲突,节点通过链表串联在bucket中。关键实现的巧妙之处体现在两处:一是迭代器逻辑,当前bucket遍历完毕后,能自动跳转到下一个非空bucket,保证了前向遍历的连贯性;二是容器容量的管理,预置了一张精心计算的素数表来动态选择桶的数量,这能有效降低哈希冲突概率,提升查找效率。 通过拆解节点定义、迭代器操作符和容器初始化等关键源码,文章清晰地展现了hashtable从数据结构到算法选择的完整实现脉络,有助于读者真正理解这个高效容器背后的工程权衡与精巧构思。
STL笔记之二叉查找树
这篇讲的是STL关联容器(如map和set)背后的核心数据结构——二叉查找树及其变体。作者从SGI STL的实现出发,系统梳理了三种关键树结构的区别与联系。 文章首先剖析了基础的二叉查找树(BST),说明了它通过键值左小右大的规则实现对数时间操作,但也指出了其退化为链表导致效率骤降至O(N)的风险。为了解决平衡问题,文章对比了AVL树和红黑树:AVL树是严格的平衡树,任何节点的左右子树高度差不超过1,通过旋转保持平衡,保证了稳定的O(log n)性能;而红黑树通过着色规则和局部调整,在不过分追求严格平衡的前提下,同样实现了高效的查找与动态操作。 最后,文章将理论落地,解释了为何红黑树凭借其在插入和删除场景下更少的旋转次数,成为SGI STL中map、set等容器的底层选择,而不只是理想中“更平衡”的AVL树。这种从原理到工程实现的脉络,对于理解标准库的设计哲学很有帮助。
位运算小结(按位与、按位或、按位异或、取反、左移、右移)
这篇讲的是位运算的基础知识系统梳理。作者从计算机底层表示数字的“补码”概念讲起,为后续运算奠定了基础,然后逐一拆解了按位与、或、异或、取反、左移、右移这六种核心操作。 文章没有停留在理论定义,而是用同一个数字(10与-10)作为贯穿始终的例子,详细演示了每种运算的二进制计算过程与最终结果。这种对比式的呈现方式,让不同运算符之间的逻辑差异(比如“与”是“都真才真”,“或”是“有真就真”)变得一目了然。 文中还特别提到了异或运算的一个巧妙应用:利用其“任何数与0异或结果不变”的特性,可以实现两个变量的交换而不借助临时变量。这个经典的算法小技巧,为实用的运算知识增添了工程色彩。 对于需要回顾计算机底层操作、或在实际编程(如权限管理、标志位处理、算法优化)中直接使用位运算的开发者,这篇文章提供了一份清晰、直观的参考手册。
如何编写一个JSON解析器
这篇讲的是如何从头实现一个JSON解析器。作者从JSON解析器的基本定义出发——即将JSON字符串转换为语言内存中的数据结构,对比了它与XML的差异,并梳理了JSON基本类型与Java数据结构(如Map、List)的映射关系。 文章的核心在于拆解实现思路。它强调解析器应采用流式单次扫描,本质是一个状态机。实现的关键步骤被清晰地勾勒出来:首先,需要封装一个`CharReader`来支持`peek()`操作,以便在不移动指针的情况下预判字符;其次,将原始字符流进一步抽象为Token流(如`BEGIN_OBJECT`、`STRING`等),从而大幅简化状态判断逻辑。最后,文章点出了处理嵌套结构的技巧:利用栈来管理Object和Array的构建,遇到开始标记时创建对应的Map或List并压栈,以此高效地完成递归解析。 整个实现过程体现了从具体到抽象、逐步化繁为简的设计思想,将看似复杂的解析任务分解为字符读取、Token识别和栈操作几个清晰的模块。
红黑树并没有我们想象的那么难(下)
这篇讲的是红黑树如何“落地”到我们常用的STL map中。作者从SGI STL源码出发,直接剖析红黑树底层类`_Rb_tree`的实现细节。 文章亮点在于对核心机制的拆解。首先解释了`_M_header`这个辅助头节点的巧妙设计,它同时维护根节点、最小与最大节点,让管理变得规整。重点展开的是两种插入策略:`insert_equal()`允许重复值,逻辑直白;而`insert_unique()`的去重判断则颇为精巧,它利用二叉搜索树性质,在寻找插入位置时通过一次向右再持续向左的走位,结合对前驱节点的比较,就能“hack”地判断出键值是否已存在。 最后,文章也回应了“为何用红黑树而非AVL树”这个经典问题,点明红黑树在搜索效率与修改开销(插入至多两次旋转)之间取得了更好的平衡,是一种实用主义的折中方案。作者通过源码把红黑树从理论概念带到了具体的工业级实现,让那些“旋转”、“着色”的抽象描述变得清晰可触。
红黑树并没有我们想象的那么难(上)
这篇讲的是红黑树,作者从一个初学者的常见困惑出发:红黑树情况太多,似乎很难。文章给出的核心解法是“合并”——通过归结和简化情况来降低理解门槛。 作者首先回顾了红黑树必须满足的五个性质,然后直接切入数据结构定义和基础的二叉搜索树操作。全文的重点放在对插入与删除算法的拆解上。对于插入,文章将其归结为三种核心情况,通过逐步调整颜色和旋转来维持性质。对于删除,分析则更为细致,分多种情况(例如“兄弟节点颜色”或“侄节点颜色”不同)讨论了重新着色和旋转的策略,并配以直观的印象图和伪代码。 整篇文章像一份详尽的算法推演笔记,通过枚举具体场景并展示调整步骤,试图将复杂的平衡操作变得有迹可循。对于想从原理层面弄懂红黑树实现细节的读者,这种直面各种案例的讲解方式可能比单纯记忆规则更有帮助。
TCP 的那些事儿(下)
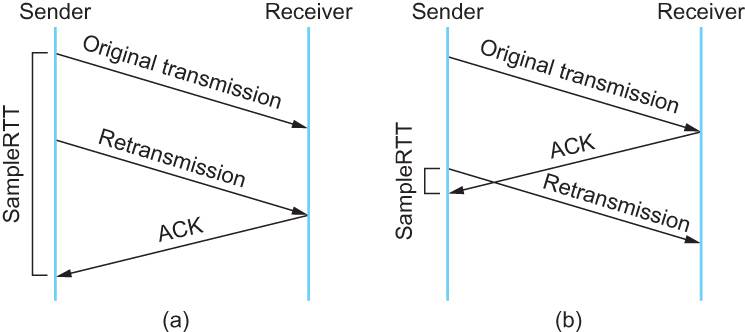
这篇讲的是TCP协议核心机制中的“动态调整”与“流控”部分,聚焦于RTT算法演进和滑动窗口原理。作者从一个实际问题切入:重传超时时间(RTO)为何不能固定设置?由此引出RTT(网络往返时长)的测量难题。 文章清晰对比了三代算法。经典算法依赖加权平均,但容易掩盖网络抖动;Karn算法为解决重传采样矛盾选择“忽略重传”,却又用粗暴的“超时翻倍”来应对网络突变;最终,Linux内核采用的Jacobson/Karels算法则更胜一筹,它引入“偏差”因子,能敏锐感知RTT的波动,计算出更精准的RTO。 另一重点是滑动窗口。文章用生动图示拆解了接收端如何通过Advertised-Window告诉发送端“我能收多少”,从而实现流量控制,并详细说明了Zero Window的处理机制及潜在的DDoS风险。整篇内容扎实,用“不适合在厕所中阅读”幽默地暗示了其思维深度,将抽象算法与网络稳定性的现实关联讲得透彻明白。
為什麼我喜歡玩魔方?
这篇讲的是一个技术人如何通过玩魔方,观察到“万能感”这种迷人的心理机制。作者并非单纯分享魔方技巧,而是从自身业余爱好出发(平均还原时间40秒,最快26秒),将玩魔方时那种“搞定不听话事物”的愉悦,与编程入门时写出“Hello World”的成就感联系了起来。 文章指出,这种通过自身意愿操控复杂系统的满足感,在苹果产品设计中体现为“一键直达”的简洁体验,在更广泛的领域则近乎一种“上帝模式”的诱惑。作者也冷静地提醒,这种“万能感”如同精神毒品,一旦遇到无法掌控的边界,便容易滋生挫败感与负面情绪。最终,他将这个小爱好上升到对“权力的诱惑”的思考,认为这或许是人类历史中无数争斗的缩影。
HLLC基数估算算法在腾讯数据仓库TDW中应用
这篇讲的是腾讯数据仓库TDW如何用一个巧办法,又快又省地计算海量数据里的“不同值个数”(基数)。背景很实际:传统精确去重在大数据面前太耗资源了。文章的核心方案,是引入了HLLC(HyperLogLog Counting)基数估算算法,并将其封装成一个极其简单的SQL聚合函数`est_distinct`。 文章不仅告诉你“是什么”,还深入拆解了“怎么做”。从HQL如何翻译成MapReduce作业,到Map端如何用一个64K桶的数组进行局部聚合,再到Reduce端如何合并数组并套用HLLC公式计算,整个过程图文并茂。其中的难点和巧妙之处在于内存管理:当数据分布不均、单个Key记录海量时,TDW采用“分而治之”策略动态分配内存块,并设计了专用的序列化(SerDe)方式来高效处理溢写到磁盘的Hash表片段,有效平衡了内存与IO开销。 最后通过实测对比给出了明确结论:在数据分布集中的较理想条件下,使用64K桶的HLLC估值计算(精度超99.4%),相比精确去重能带来数倍的效率提升。对于需要在大规模数据上快速获得近似唯一值计数的场景,这提供了非常清晰且可落地的实践参考。
从未降级的搜索-主搜索分层优化
这篇讲的是淘宝主搜索如何通过索引分层技术,将集群架构从二维升级到三维,从而解决长期存在的性能与扩展性瓶颈。 作者从主搜索沿用多年的二维架构出发,指出其存在机器消耗多、低质量商品拖累效率、索引结构单一且难以支持多样化排序等核心问题。文章提出的分层优化方案,核心思路是将商品按质量(Good/Bad)和特定排序需求(如人气)拆分成不同集群,并设计相应的检索策略。例如,对人气排序查询优先走仅包含头部商品的Excellent集群,而对一般查询则优先查Good集群,不足时再补充Bad集群。 这种三维架构带来了显著收益:不仅将集群规模缩减了36%,整体检索性能提升了120%,最终还带动了6%的搜索GMV增长。文章用清晰的架构图和具体数据,展示了如何通过精巧的索引设计,在控制成本的同时满足多样化的排序需求,为主搜索的业务拓展提供了坚实的技术基础。
数据分析中位数的应用
这篇讲的是如何让枯燥的折线图更直观地传达信息。作者发现,普通折线图常常无法突出数据中的关键点,于是通过对比两张图(A图是常规折线,B图则将最高的几个数据点用特殊图标标出),直观地展示了“一目了然”的视觉效果差异。 核心问题随之而来:如何从一堆数据里,自动找出那个用于区分“特殊点”与“普通点”的分界线呢?文章对比了两种常见方法——平均数和中位数。作者指出,平均数虽然反映整体水平,但极易被一两个极端的高值或低值“带偏”,无法稳定代表“大多数”情况。相比之下,中位数是把数据排序后取中间的那个数(或两个数的平均),它不受极端值影响,更能代表数据的“中间”或“典型”水平,因此成为构建这个分界线的更优选择。 为了便于实践,作者还提供了一个计算中位数的PHP函数代码示例。整篇文章从一个可视化的痛点切入,落到具体的统计概念辨析和算法实现,思路清晰,具有不错的实操参考价值。
无锁消息队列
这篇讲的是如何在共享内存中设计高效的无锁消息队列。作者从实际项目需求出发——为了将耗时的数据落地任务从主逻辑进程中剥离,以提升整体处理能力——提出了用无锁队列替代频繁系统调用的方案。 文章的核心是从简单到复杂,逐步推演无锁队列的设计。首先探讨了最基础的单生产者与单消费者场景,仅需维护 front 和 rear 指针,利用循环队列即可高效工作。接着,为解决多消费者并发出队的问题,引入了 CAS(Compare & Set)原子操作来安全地更新指针。最后,在多生产者多消费者的最复杂场景下,通过增加一个 write_index 变量,结合两次 CAS 操作来协调生产者之间的写入竞争,确保了数据一致性。 文章结合具体图示和伪代码,清晰地阐述了不同并发模型下的实现关键与细微差别,例如利用 CAS 实现“乐观锁”,以及在生产者操作失败时通过 sched_yield() 让出 CPU 的优化技巧。作者在项目中实际应用了其中一种设计,最终观察到 CPU 使用率下降了约10%,验证了该方案的有效性。
为比特币绘制 MACD、BOLL、KDJ 指标图
这篇讲的是,作者如何用 Python 从零开始,为比特币行情绘制一套像股票软件那样的技术分析指标图。 核心要解决的问题是数据源的“坑”:比特币中国的 API 返回的最高价、最低价和成交量,是基于过去24小时统计的,但比特币市场根本没有休市概念。作者的设计思路是,参照股市习惯,采用4小时为一个周期进行数据处理和绘图。 文章详细分享了从获取数据、存储到计算指标的全流程。作者先编写程序,将实时交易数据和计算出的4小时周期K线(OHLC)数据存入MySQL数据库。随后,重点展示了 MACD 指标的计算算法:如何通过收盘价序列依次计算出12日和26日指数移动平均线(EMA),得到差离值 DIF,再计算 DIF 的9日EMA作为信号线 DEA,最终求出 MACD 柱状图。整个实现过程逻辑清晰,代码完整。 作者将这套自己的实现与后来 btc123 平台上线的官方指标图作了对比,并大方地将源码分享在博客,为同样在学习 Python 或量化交易的朋友提供了一个不错的实践参考。
萃取(traits)编程技术的介绍和应用
这篇讲的是C++中一项优雅而实用的泛型编程技巧——萃取(traits)技术。作者从STL中迭代器与算法解耦的需求出发,首先展示了一个核心矛盾:为了让统一的算法(如find)既能作用于自定义容器迭代器,又能兼容原生指针(如int*),我们需要一种机制来统一获取迭代器所指对象的类型信息。文章清晰地介绍了如何通过`iterator_traits`这个中间层,结合模版偏特化来解决这一问题,使`int*`这样的原生指针也能被正确萃取出`value_type`。 接着,文章将这一思想从迭代器扩展到了更广阔的“类型萃取”领域。作者以SGI STL的`__type_traits`为例,说明了如何利用萃取技术探测类型特性(如是否有平凡的构造函数、析构函数)。通过为内置类型(如int)提供特化版本,算法(如copy)就能在运行时选择最高效的实现路径——比如直接进行内存拷贝而非调用复杂的构造函数,从而显著提升性能。 文章从具体问题切入,逐步抽象出“特性萃取”的通用编程模式,最后落脚于其对C++泛型库性能优化的实际价值,展示了如何通过编译期的类型信息提取来弥补语言本身的局限。
如何使用1M的内存排序100万个8位数
这篇讲的是如何在仅有1MB内存的约束下,对100万个8位整数进行排序的经典算法难题。问题最初源于Stack Overflow,看似无解——毕竟100万个数直接存储就需要超过1MB的空间。文章介绍了一种巧妙的解法核心:不直接存储排序后的每个数字本身,而是利用它们已排序这一特性,转而记录相邻数字之间的差值。由于这些差值平均很小,理论上可以用大约7位(bit)来表示一个差值,总计约0.875MB,从而在1MB内存内完成编码存储。实现上采用了高效的归并排序,并利用算数编码或哈夫曼编码对差值进行压缩编码。作者还分享了完整的339行实战代码,并提到了其他程序员的不同解题思路,展现了算法在极端约束下化不可能为可能的魅力。